如何设计一个坚如磐石的数据层?
Posted 欢迎访问楚原的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何设计一个坚如磐石的数据层?相关的知识,希望对你有一定的参考价值。
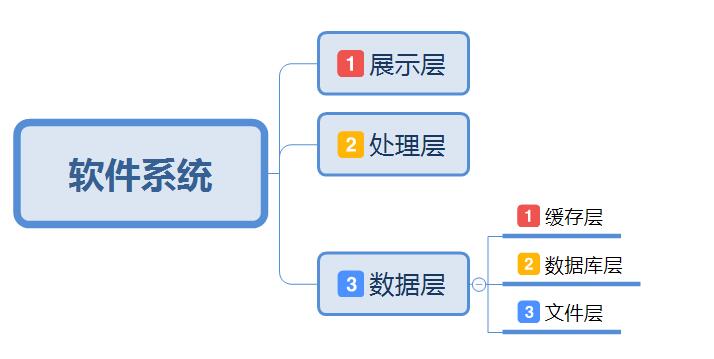
在现代软件工程的开发应用和系统设计中,我们一般把软件系统的逻辑层次分为三层:展示层,处理层和数据层。数据层又可细分为缓存层,数据库层和文件存储层,如图:
鉴于创建高性能程序的关键是多花时间在系统设计上,本文主要对软件系统的数据层优化设计做一些阐述和归纳总结。
缓存
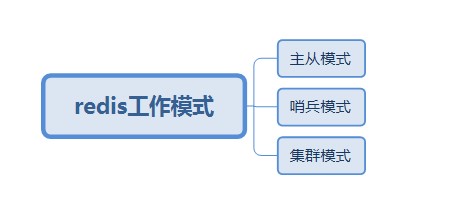
在互联网系统中,缓存技术对高并发,高性能的帮助起着功不可没的作用。以目前使用最为广泛的是redis3.0版本为例,其有三种工作模式:
以上3种模式都支持级联部署。针对不同数据量大小,一般可采用两种方案:
如果数据量在10G以内,单master+3个哨兵集群即可。
数据量在1T以上,采用集群模式,3主3从1备份,至少部署7个或者更多redis实例。可有效解决redis在分布式方面的需求,动态扩容,自动故障转移等。
使用建议
1,合理使用缓存的淘汰策略,redis提供了6种不同的策略。默认是noeviction ,当实际内存超出 maxmemory 时只能删和读,不会写。
2,主动设置缓存的失效时间,为每个缓存对象设置一个随机范围内的失效时间,避免某些缓存大量失效,造成缓存雪崩,以至于引发级联故障。
3,为避免遭受恶意查询请求,如查询不存在的订单,可考虑采用Google guava 提供的boolmFliter。其默认错误率是3%(可配置),5个哈希函数(mumurt,md5,crc300等) ,
bit数组长度是七百多万,0.6M大小。 创建过滤器时,最好将大小设置为单号总量的2倍,以降低hashmap碰撞的概率,实现快速构建。
4, 缓存需要刷新时,直接删除该缓存,让下一次请求去重新设置缓存,或者采用消息中间件异步刷新和定时刷新的方式。
5,如果必须使用分布式事务(尽量避免),可考虑通过setNx(),而不使用数据库去实现。
数据库
一、安全性设计
一般采取的安全策略为用户管理,存取控制、数据加密、审计跟踪和攻击检测。
二、完整性设计
1,在需求分析阶段制定完整的命名规范,尽量使用有意义的英文单词或缩写、下划线等组合,注释完备且正确。
2,慎用目前主流DBMS都支持的触发器功能。一方面性能开销较大,另一方面触发器的多级触发不好控制,容易发生错误,如果需要用最好使用Before型语句级触发器。
3,根据数据的约束的类型确定其实现的系统层次和方式,并提前考虑对性能的影响。一般情况下,字段约束尽量在数据库中,逻辑约束由应用程序去实现,并根据业务规则对数据库做细致的测试。
三、应用设计
应采用数据库连接池技术连接数据库,例如HikariCP ,并设置最大连接数,最小连接数,一个机械硬盘比较可靠稳定的最大连接数200左右,固态硬盘最大连接数是700左右。
mysql单表数据如果大于700万,Oracle单表数据大于5000万,会造成性能大幅下降,应考虑及时修改数据库虚拟内存、分库分表,或者建立数据库集群。
文件
目前应用较广的分布式文件系统有:FastDFS 和 HDFS ,FastDFS适合中小文件,HDFS适合非并发写的大文件。安装和使用都比较简单,都提供了对应接口API。
以上是关于如何设计一个坚如磐石的数据层?的主要内容,如果未能解决你的问题,请参考以下文章