全文搜索原理简单解析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全文搜索原理简单解析相关的知识,希望对你有一定的参考价值。
文前声明:本人只是知识的搬运工,文中许多知识和观点大多数都是来自于网络或书本,因为没有记录的习惯学习研究完,便忘记名称了,如若还记得,在文后自会添加备注。
注:这是本人的第一篇薄文,水平相形见拙,有错误之处,欢迎指正。
今年的计划是存储领域,希望能深入的了解其原理,如果能有创造性的写出一个自己的文件系统出来就更好了,到目前为止尚无动工的迹象,估计会顺延至明年了吧!
我的计划正好赶上公司的总规划,于是便接了“大数据”的活。刚开始进入这一行,走了不少弯路,说多了都是泪(这不是本文的主题,就此打住,后面再叙),就在被Hive,Hbase,Hadoop,Spark等等各种工具搞的眼花缭乱的某个瞬间,头脑中冒出一个问题:如果不让用传统的关系数据库,要你自己去实现大数据存贮的话,第一件事要做的是什么? 搜索,全文搜索。数据存好存,关键是怎么找到你想要找到的数据,于是便花了一天时间研究了全文搜索技术(我想搞大数据的都该懂搜索才对的吧),谷歌、百度还有其他各种所搜都是采用的”全文搜索“,但技术实现各有优劣。
那什么叫“全文搜索“,它的定义是什么? 说白了就是在一堆非结构化的文档中寻找你想要的数据的技术。
全文搜索的实现技术各种各样,最原始的就是顺序查找。顺序查找顾名思义就是一个文档一个文档,一个字符一个字符查找,这种搜索技术简单,但时间复杂度为O(n)。人们发现为什么关系数据库的搜索就非常快,因为关系数据库添加了索引。全文搜索是不是可以参考一下它的实现呢,是的,当然可以,于是便诞生了现代的全新的”全文搜索技术“。这种技术类似于我们查新华字典的过程,现代新华字典增加了两种索引技术,一种是汉语拼音索引,一种是偏旁部首索引,可根据你的喜好自行选择其中一种索引技术去查找汉字。
至此,我们引出了一个新的问题:即如何为一份文档创建索引?这是一个好问题,要讲的内容真不少,它牵涉到分词技术,因篇幅所限,所有问题的答案都从简,直白说,为一份文档创建索引就是提取关键字的过程。举个例子:”周杰伦很有才。他唱歌很好,就是口齿不清,这是一个遗憾!“,在这两句话中,我们提取出来的关键字应该是”周杰伦、有才、唱歌好、口齿不清、遗憾“,剩下的部分在分词技术领域被称为”停用词“(英文名称叫stop words),提取出来的关键字叫tokens。这种提取关键字的技术与我们初中语文课上学习的“提取句子主干即只保留主谓宾”内容相似,细节上区分还是蛮大的。
我们创建起来的索引,大致如下图所示:
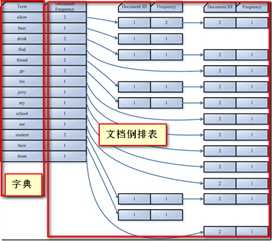
这种为文档创建起来的索引,在学术上称为“倒排索引“,好,索引创建好了,那如何搜索呢?
这一步工作比创建索引要简单些(其实并不简单),我们输入关键字,程序根据关键字返回对应的文档,看起来到这一步貌似很合理,这就结束了?事实上没有这么简单,想想百度的时候,搜索的答案是随机的吗?显然不是(当然百度竞价排名是可恶的),搜索到的答案是根据一定的规则来返回。这个规则学术上称之为“评分”,评分高在前还是低在前要看评分规则了。
开源的搜索引擎"Lucene",评分规则就是低分在前,关于评分的规则也不展开说了,后面有机会再聊。
最后总结一下整个过程吧:
1:获取文档
2:进行分词,创建索引
3:索引存贮,以备后用
4:用户输入查找
5:分析用户输入,还是分词
6:搜索索引,返回相关文档
7:对返回的文档进行评分,进行排序
8:返回搜索到的文档
这里面每一步足以一篇论文来论述,后面有机会去实践这个玩意的时候,再详细叙述吧!
以上是关于全文搜索原理简单解析的主要内容,如果未能解决你的问题,请参考以下文章