Java---XML的解析-DOM解析
Posted 谙忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java---XML的解析-DOM解析相关的知识,希望对你有一定的参考价值。
本章只讲DOM解析。接下来还会学习Dom4j和StAX 解析技术
DOM解析:
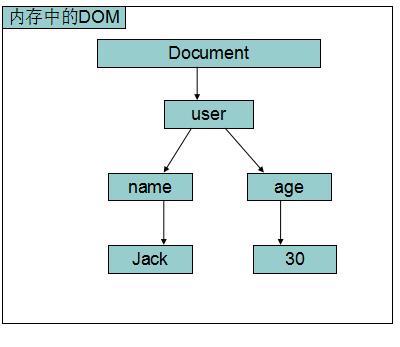
DOM解析一次将所有的元素全部加载到内存中:如有以下XML文档:
<user>
<name>Jack</name>
<age>30</age>
</user>由于DOM解析,一次性的将所有元素(包含属性和文本) 全部加载到内存中,所以不适用于解析大量的数据。
JAXP-DOM解析:
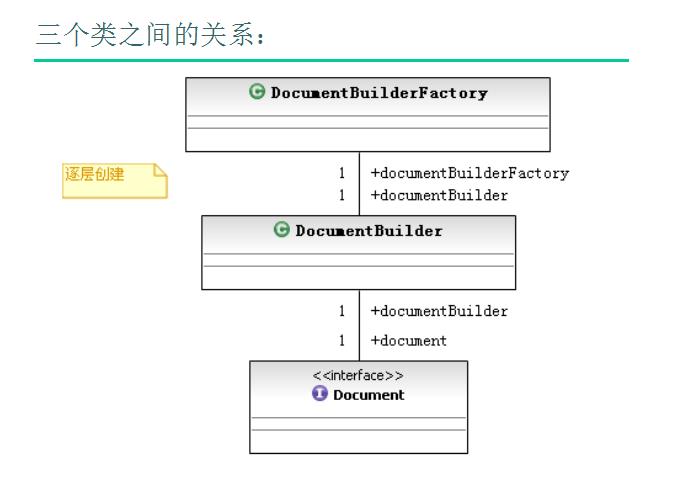
包:
javax.xml.parse – 关键类DocumentBuilder,文档解析对像。
org.w3c.dom – 关键类Document代表内存中的文档对像模型。
java.xml – 关键类Transformer,用于将内存中的文档保存到文件中。
users.xml:-在xml4文件夹下面
<?xml version="1.0" encoding="UTF-8" standalone="no"?><users>
<user id="A001">
<name>Tom</name>
<age>23</age>
</user>
<user id="C001">
<name>李四</name>
<age>33</age>
</user>
</users>
<!--添加进来了吧,为了演示而建立的简单xml文档-->代码演示:
package cn.hncu.dom;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
/**
* @author 陈浩翔 2016-6-29
*/
public class DomDemo1 {
@Test
// 需求:把第一个user节点的name的值取出来
public void getDom() throws SAXException, IOException,
ParserConfigurationException {
// 第一步,通过DocumentBuilderFactory类中的工厂方法等到一个dbf对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 第二步,通过dbf对象创建出一个DocumentBuilder对象
DocumentBuilder db = dbf.newDocumentBuilder();
// 第三步,通过db对象创建出一个Document对象
Document dom = db.parse("xml4/users.xml");
// db.parse( new File("xml4/users.xml") );//也可以
System.out.println(dom);// [#document: null]
Node root = dom.getFirstChild();// 这个是根节点
System.out.println("root:" + root);// root:[users: null]
System.out.println(root.getNodeName());// users
System.out.println(root.getFirstChild().getNodeName());// #text
// 上面一句的输出是:#text ----dom中把空白符也看成是一个Node,这种情况对我们的解析通常会造成很大的麻烦
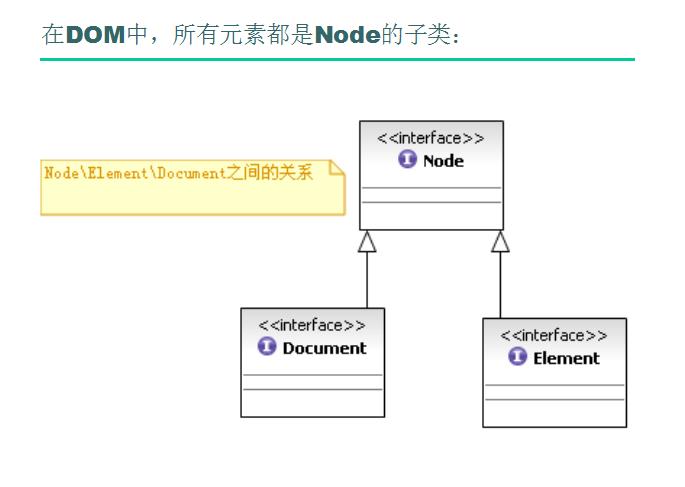
// ※※为解决上面的问题,我们以后解析时尽量不要用Node,而要用Element。
// 因为Element是元素它不包含属性和文字内容(包括空白符),因此可避开空白符的干扰
Element eRoot = (Element) root;
NodeList list = eRoot.getElementsByTagName("user");
System.out.println("user元素的数量:" + list.getLength());
System.out.println("第2个user元素" + list.item(1));
Node user1Node = list.item(0);
Element eUser1 = (Element) user1Node;// 要把Node强转成Element,因为Element是子接口,里面有getElementBy*等方法,而Node没有(只能采用childNodes的方式,这种方式会受空白符的干扰)
NodeList listNames = eUser1.getElementsByTagName("name");
String nm = listNames.item(0).getNodeName();// name--标签名
String nmVal = listNames.item(0).getTextContent();// 标签内部所包含的文本内容----相当于javascript中的innerText
System.out.println(nm + "," + nmVal);
}
@Test //需求:把第二个user节点的age值取出来
public void getAge()throws Exception{
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse(new File("xml4/users.xml"));
Element root = (Element)dom.getFirstChild();
Element user2 = (Element)root.getElementsByTagName("user").item(1);
Element eAge = (Element)user2.getElementsByTagName("age").item(0);
String age = eAge.getTextContent();
System.out.println("age:"+age);
}
//用java对xml文档进行CRUD---创建,遍历,更新,删除
//创建---需求:添加一个新的user
@Test
public void create() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder db = factory.newDocumentBuilder();
Document dom = db.parse(new File("xml4/users.xml"));
Element root = (Element) dom.getFirstChild();
//创建一个新的user元素
Element eUserNode = dom.createElement("user");
eUserNode.setAttribute("id", "C001");//给元素添加属性
//创建name和age子元素
Element eName = dom.createElement("name");
eName.setTextContent("李四");//设置name标签容器中包含的文字
Element eAgeNode = dom.createElement("age");
eAgeNode.setTextContent("33");
//把所创建的元素组装成一颗子树,添加到整颗dom树上
eUserNode.appendChild(eName);
eUserNode.appendChild(eAgeNode);
root.appendChild(eUserNode);
//再把当前内存中的dom对象存储进xml文件
TransformerFactory tf = TransformerFactory.newInstance();
Transformer trans = tf.newTransformer();
trans.transform(new DOMSource(dom), new StreamResult("xml4/users.xml"));
}
//遍历---查找
@Test
public void query() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder db = factory.newDocumentBuilder();
Document dom = db.parse("xml4/users.xml");
Element root = (Element) dom.getFirstChild();//得到根节点
NodeList list = root.getElementsByTagName("user");//这个user是xml文档中的元素
for(int i=0;i<list.getLength();i++){//循环遍历
Element user = (Element) list.item(i);
String id = user.getAttribute("id");
String name = user.getElementsByTagName("name").item(0).getTextContent();
String age = user.getElementsByTagName("age").item(0).getTextContent();
System.out.println("id:"+id+",name:"+name+",age:"+age);
System.out.println("---------------------------------");
}
}
//更新---要求:把最后一个user的年龄+10
@Test
public void update() throws Exception{//为了方便,就只抛这个异常了,如果是以后搞项目,一定要详细才行的
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder db = factory.newDocumentBuilder();
Document dom = db.parse( new File("xml4/users.xml") );
Element root = (Element) dom.getFirstChild();
NodeList list = root.getElementsByTagName("user");
Element eUser = (Element) list.item( list.getLength()-1 );
String sAge = eUser.getElementsByTagName("age").item(0).getTextContent();
int age = Integer.parseInt(sAge)+10;
System.out.println("age:"+eUser.getElementsByTagName("age").item(0).getTextContent());
eUser.getElementsByTagName("age").item(0).setTextContent(""+age);
System.out.println(eUser.getElementsByTagName("age").item(0).getTextContent());
//把内存中的当前dom对象存储到xml文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer trans = tf.newTransformer();
trans.transform(new DOMSource(dom), new StreamResult("xml4/users.xml"));
//把xml源输出到目标---如果目标存在则是更新,否则就是创建
}
//删除---需求:删除最后一个元素
@Test
public void delete() throws Exception{
// 第一步,通过DocumentBuilderFactory类中的工厂方法等到一个dbf对象
DocumentBuilderFactory foctory = DocumentBuilderFactory.newInstance();
// 第二步,通过dbf对象创建出一个DocumentBuilder对象
DocumentBuilder db =foctory.newDocumentBuilder();
// 第三步,通过db对象创建出一个Document对象
Document dom = db.parse("xml4/users.xml");
//获取根节点
Element root =(Element)dom.getFirstChild();
//获取将要删除的元素
NodeList list = root.getElementsByTagName("user");
Element e = (Element)list.item( list.getLength()-1 );
e.getParentNode().removeChild(e);
//在内存中已经移除了。
//把当前内存中的dom对象存储到xml文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer trans = tf.newTransformer();
trans.transform(new DOMSource(dom), new StreamResult( "xml4/users.xml" ));
}
}
小知识点:
注意:子类才可以当父类用。
父类的话,如果你确定那个类一定是这个父类的某个子类了,才可以强转为子类!!!
以上是关于Java---XML的解析-DOM解析的主要内容,如果未能解决你的问题,请参考以下文章