如何判断一个元素是否存在于一个亿级数据集中?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何判断一个元素是否存在于一个亿级数据集中?相关的知识,希望对你有一定的参考价值。
布隆过滤器的概念布隆过滤器(Bloom Filter)于 1970 年由布隆提出的,是专门 用于检索一个元素是否存在于一个集合中的算法。
你可能会想,判断一个元素是否在集合中,这不就是集合自带的功能吗?
元素数量少的时候的确没问题,但如果有海量元素时就麻烦了,例如千万,甚至上亿个元素,而且每个元素的大小不一,有可能很大,这时集合的空间效率和查询效率都会堪忧。
而布隆过滤器就可以巧妙的解决这个问题,它包括了一个很长的二进制向量和一系列的hash函数,它不会实际存储元素内容,只是在二进制向量中标识这个元素是否存在,而 hash 函数就是用来定位元素的。
- 使用场景
布隆过滤器的核心作用是 判断元素是否存在 ,在如今海量数据场景中可以起到非常大的作用。
例如:
2.1 防止数据库穿库
Bigtable、HBase 和 Cassandra 等大数据存储系统也会使用布隆过滤器。
查询操作是磁盘I/O,代价高昂,如果大量的查询不存在的数据,就会严重影响数据库性能。
使用布隆过滤器可以提前判断不存在的数据,避免不必要的磁盘操作。
2.2 防止缓存穿透
查询时一般会先判断是否在缓存中,如果没有,就读DB,并放入缓存。
这是正常流程,没有问题。
但如果有恶意请求,一直查询不存在的数据,例如查询用户abc的详细信息,而abc根本不存在。
按照正常流程的话,就肯定会去读DB,那数据库的压力就大了。
这时就可以使用布隆过滤器,例如请求用户abc的时候,先判断此用户是否存在,不存在就直接返回了,避免了数据库查询。
2.3 爬虫URL去重
避免爬取相同URL地址。
反垃圾邮件
从数十亿垃圾邮件列表中判断某邮箱是否为垃圾邮箱。
- 实现原理
我们通过一个例子来理解其原理。
假设一个二进制数组,长度为8,初始值都为0(0表示不存在)。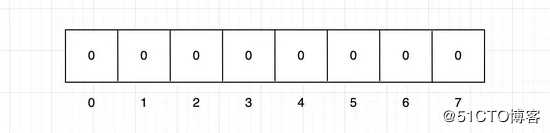
现添加元素 张三 ,先通过hash函数定位其在二进制数组的位置,然后将此位置的值设为 1 :
hash1(张三) % 8 = 4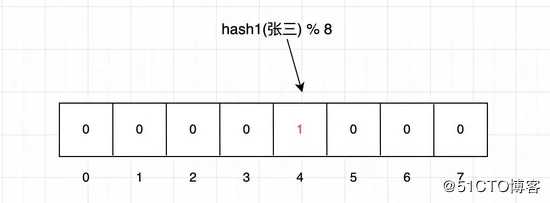
现在需要判断 李四 是否存在,用同样的方法计算出其位置,然后取此位置的值
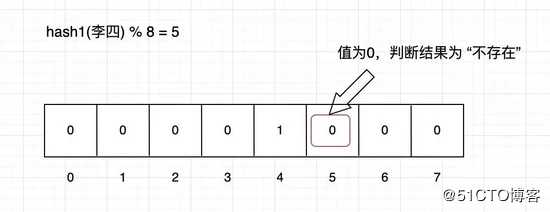
值为 0 ,说明 李四 不存在。
这就是基本原理。
我们都知道哈希冲突是普遍存在的,所以通过一个hash函数定位元素是不可靠的。
例如张三、王五的hash定位都是4:
hash1(张三) % 8 = 4
hash1(王五) % 8 = 4张三 是已经存在的元素, 王五 不存在,但因为 [4] 的值是 1 ,所以对 王五 的判断结果是 存在 ,这就误判了。
为了解决哈希冲突的问题,通常会使用多个hash函数对元素进行定位,例如:
同一个元素,经过多个不同的hash算法,计算出来的结果相同的概率就非常低了。
计算出来的位置的值如果包含 0 ,那么可以肯定元素一定不存在
相反,如果都是1,却不能肯定元素一定存在,因为可能有哈希冲突
Redis 实现布隆过滤器
Redis 4.0 推出了 module 模式,可以开发扩展模块, RedisBloom 就是布隆过滤器的扩展模块。
实践
启动带有 RedisBloom 的 Redis 环境:
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest进入容器中的 redis 客户端:
# 进入容器
docker exec -it redis-redisbloom bash
# 登录redis客户端
redis-cli添加元素:
127.0.0.1:6379> BF.ADD newFilter foo
(integer) 1检测元素是否存在:
127.0.0.1:6379> BF.EXISTS newFilter foo
(integer) 1
127.0.0.1:6379> BF.EXISTS newFilter foo2
(integer) 0以上是关于如何判断一个元素是否存在于一个亿级数据集中?的主要内容,如果未能解决你的问题,请参考以下文章