JDK8:Lambda根据 单个字段多个字段,分组求和
Posted 王晓东
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK8:Lambda根据 单个字段多个字段,分组求和相关的知识,希望对你有一定的参考价值。
使用lambda表达式分别 根据 单个字段、多个字段,分组求和
示意图:
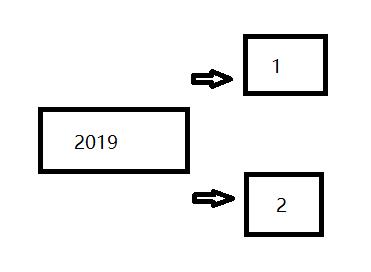
1、根据 单个字段,分组求和:根据2019这个字段,计算一个list集合里,同属于2019的某个字段累加和
2、根据 多个字段,分组求和:
(1)先根据2019这个字段,再根据1这个字段,计算一个list集合里,同属于2019和1的某个字段累加和;
(2)先根据2019这个字段,再根据2这个字段,计算一个list集合里,同属于2019和2的某个字段累加和;
代码如下:
import com.pojo.DataStatisticsResultMiddle;
import java.util.ArrayList;
import java.util.List;
import java.util.LongSummaryStatistics;
import java.util.Map;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
List<DataStatisticsResultMiddle> li = new ArrayList<>();
DataStatisticsResultMiddle middle1 = new DataStatisticsResultMiddle();
middle1.setDatas("2019");
middle1.setCarrierid("1");
middle1.setEnusers(100L);
DataStatisticsResultMiddle middle2 = new DataStatisticsResultMiddle();
middle2.setDatas("2019");
middle2.setCarrierid("1");
middle2.setEnusers(150L);
DataStatisticsResultMiddle middle3 = new DataStatisticsResultMiddle();
middle3.setDatas("2019");
middle3.setCarrierid("1");
middle3.setEnusers(200L);
DataStatisticsResultMiddle middle4 = new DataStatisticsResultMiddle();
middle4.setDatas("2019");
middle4.setCarrierid("2");
middle4.setEnusers(400L);
DataStatisticsResultMiddle middle5 = new DataStatisticsResultMiddle();
middle5.setDatas("2019");
middle5.setCarrierid("2");
middle5.setEnusers(500L);
DataStatisticsResultMiddle middle6 = new DataStatisticsResultMiddle();
middle6.setDatas("2019");
middle6.setCarrierid("2");
middle6.setEnusers(600L);
li.add(middle1);
li.add(middle2);
li.add(middle3);
li.add(middle4);
li.add(middle5);
li.add(middle6);
//单个字段,分组求和(datas)
Map<String, LongSummaryStatistics> enusersCollect1 =
li.stream().collect(Collectors.groupingBy(DataStatisticsResultMiddle:: getDatas, Collectors.summarizingLong(DataStatisticsResultMiddle :: getEnusers)));
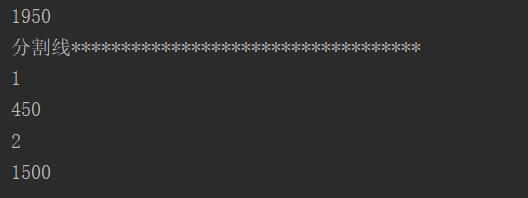
LongSummaryStatistics enusers = enusersCollect1.get("2019");
System.out.println(enusers.getSum());
System.out.println("分割线***********************************");
//多个字段,分组求和(先按datas分组,再按Carrierid分组,求和)
Map<String, Map<String, LongSummaryStatistics>> enusersCollect2 =
li.stream().collect(Collectors.groupingBy(DataStatisticsResultMiddle:: getDatas,
Collectors.groupingBy(DataStatisticsResultMiddle:: getCarrierid,
Collectors.summarizingLong(DataStatisticsResultMiddle :: getEnusers))));
Map<String, LongSummaryStatistics> map = enusersCollect2.get("2019");
for(Map.Entry<String, LongSummaryStatistics> entry : map.entrySet()){
System.out.println(entry.getKey());
System.out.println(entry.getValue().getSum());
}
}
}
输出结果如下:
3、List的某个字段为String,对其求和:
防止精度丢失:用BigDecimal
//字段为String类型,数字带小数,防止精度丢失:用BigDecimal String aaa = list.stream().map(i -> new BigDecimal(i.getCurrentIncome())).reduce(BigDecimal.ZERO, BigDecimal::add).toString(); System.out.println("aaa:"+ aaa); //会精度丢失 String bbb = String.valueOf(list.stream().mapToDouble(i -> Double.parseDouble(i.getCurrentIncome())).sum()); System.out.println("bbb:"+ bbb);
以上是关于JDK8:Lambda根据 单个字段多个字段,分组求和的主要内容,如果未能解决你的问题,请参考以下文章