使用Mat分析大堆信息
Posted 异想天开
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Mat分析大堆信息相关的知识,希望对你有一定的参考价值。
在定位一线问题时经常碰测试中出现Out Of Memory的问题, 通过jmap查看,发现JVM heap全用满了。有很多工具可以查看JVM堆的信息, 收费的比如JProfiler, YourKit,免费的如Oracle JDK自带的visualvm, jhat和Eclipse MAT。这个应用安装在一台AWS上,没有图形界面, 内存也比较小,想通过VNC远程桌面启动visualvm或者MAT不可能,通过jhat分析dump出来的snapshot(大约4.3G)也很慢,半天没有分析完毕,这种办法也放弃。
最后通过MAT的命令行工具分析了dump出来的snapshot,查找到OOM的元凶。
一、使用脚本分析Dump文件
如果没有办法图形化启动visualvm和MAT,那么就使用MAT文件夹下的ParseHeapDump.sh, 特别适合分析大堆的信息。
首先你需要修改MemoryAnalyzer.ini中的Xmx值,确保有充足的硬盘空间(至少dump文件的两倍)。然后运行:
./ParseHeapDump.sh heap.bin org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
会得到suspects, overview和top_components三个视图的信息:
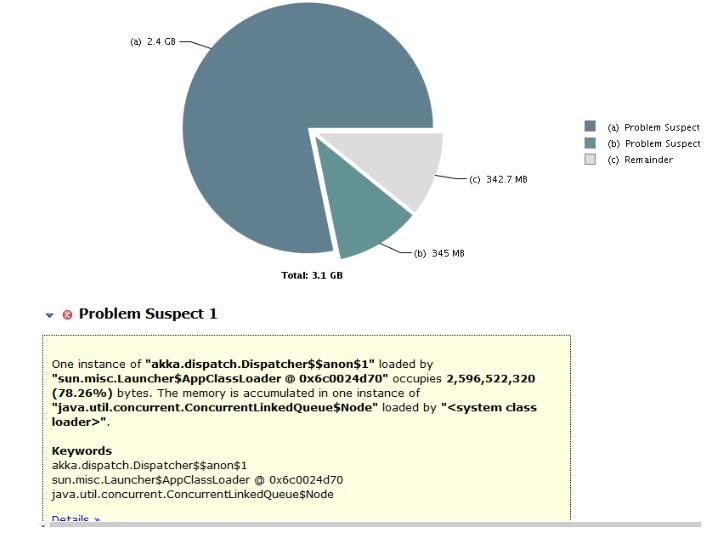
可以看到akka.dispatch.Dispatcher$$anon$1一个实例占用了2.4GB的内存,这就是罪魁祸首。这其实是akka dispatcher的mailbox中java.util.concurrent.ConcurrentLinkedQueue,每个Node占用了81M的内存,消息体太大了。
二、编写程序得到所需信息
也可以引 MAT的类,得到heap dump中的信息, 因为MAT使用Eclipse RCP框架, 基于osgi架构,使用起来不太方便,所以你可以别人抽取出来的MAT库,如https://bitbucket.org/joebowbeer/andromat,然后实现一个命令行程序,比如下面的例子就是输出所有的字符串的值:
import org.eclipse.mat.SnapshotException;
import org.eclipse.mat.parser.model.PrimitiveArrayImpl;
import org.eclipse.mat.snapshot.ISnapshot;
import org.eclipse.mat.parser.internal.SnapshotFactory;
import org.eclipse.mat.snapshot.model.IClass;
import org.eclipse.mat.snapshot.model.IObject;
import org.eclipse.mat.util.ConsoleProgressListener;
import org.eclipse.mat.util.IProgressListener;
import java.io.File;
import java.io.IOException;
import java.util.Collection;
import java.util.HashMap;
public class Main {
public static void main(String[] args) throws SnapshotException, IOException {
String arg = args[args.length - 1];
String fileName = arg;
IProgressListener listener = new ConsoleProgressListener(System.out);
SnapshotFactory sf = new SnapshotFactory();
ISnapshot snapshot = sf.openSnapshot(new File(fileName),new HashMap<String, String>(), listener);
System.out.println(snapshot.getSnapshotInfo());
System.out.println();
String[] classNames = {"java.lang.String"};
for (String name : classNames) {
Collection<IClass> classes = snapshot.getClassesByName(name, false);
if (classes == null || classes.isEmpty()) {
System.out.println(String.format("Cannot find class %s in heap dump", name));
continue;
}
assert classes.size() == 1;
IClass clazz = classes.iterator().next();
int[] objIds = clazz.getObjectIds();
long minRetainedSize = snapshot.getMinRetainedSize(objIds, listener);
System.out.println(String.format("%s instances = %d, retained size >= %d", clazz.getName(), objIds.length, minRetainedSize));
for (int i = 0; i < objIds.length; i++) {
IObject str = snapshot.getObject(objIds[i]);
String address = Long.toHexString(snapshot.mapIdToAddress(objIds[i]));
PrimitiveArrayImpl chars = (PrimitiveArrayImpl) str.resolveValue("value");
String value = new String((char[]) chars.getValueArray());
System.out.println(String.format("id=%d, address=%s, value=%s", objIds[i], address, value));
}
}
}
}
基本上使用ParseHeapDump.sh已经得到了我所需要的结果,优化akka actor消息的内容解决了我的问题。
三、mat常见功能的使用
1、Histogram 查询
用的最多的功能是 Histogram,点击 Actions下的 Histogram项将得到 Histogram结果:
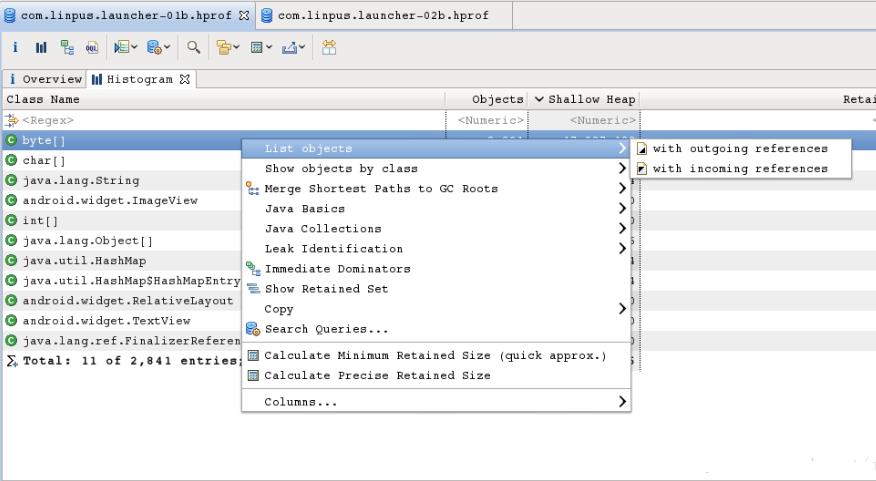
它按类名将所有的实例对象列出来,可以点击表头进行排序,在表的第一行可以输入正则表达式来匹配结果 :

在某一项上右键打开菜单选择 list objects ->with incoming refs 将列出该类的实例:
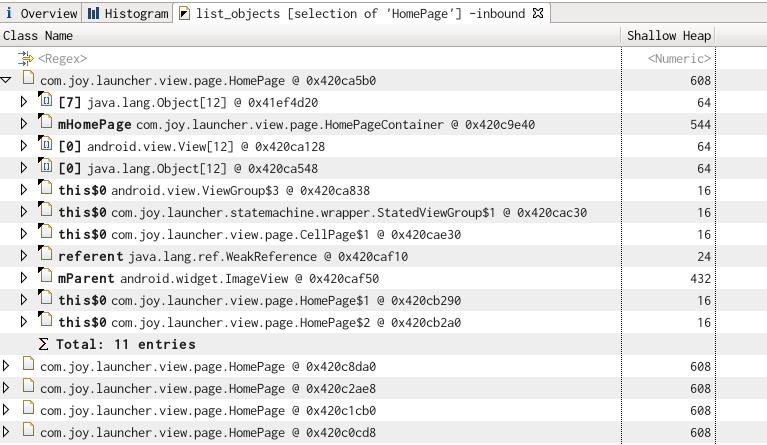
它展示了对象间的引用关系,比如展开后的第一个子项表示这个 HomePage(0x420ca5b0)被 HomePageContainer(0x420c9e40)中的 mHomePage属性所引用.
快速找出某个实例没被释放的原因,可以右健 Path to GC Roots-->exclue all phantom/weak/soft etc. reference :
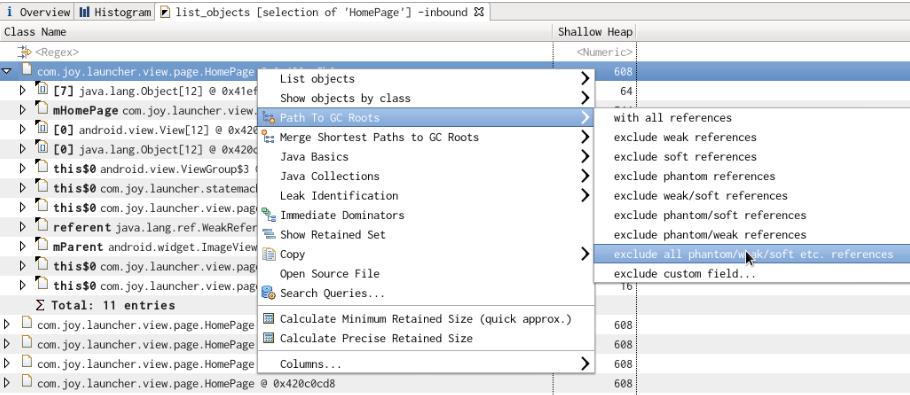
得到的结果是:
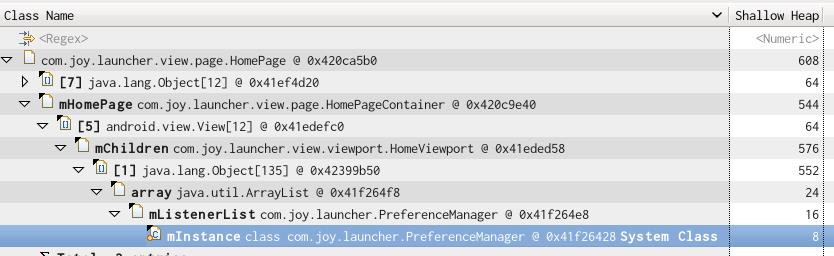
从表中可以看出 PreferenceManager -> … ->HomePage这条线路就引用着这个 HomePage实例。用这个方法可以快速找到某个对象的 GC Root,一个存在 GC Root的对象是不会被 GC回收掉的
关于Histogram 的对比请参见:http://blog.csdn.net/lang_man_xing/article/details/22160849
以上是关于使用Mat分析大堆信息的主要内容,如果未能解决你的问题,请参考以下文章
opencv源代码分析:icvGetTrainingDataCallback简单介绍
OpenCV源代码赏析: Mat对象step属性含义及使用深入分析