Coursera课程《Machine Learning》学习笔记(week1)
Posted 悠望南山
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Coursera课程《Machine Learning》学习笔记(week1)相关的知识,希望对你有一定的参考价值。
这是Coursera上比较火的一门机器学习课程,主讲教师为Andrew Ng。在自己看神经网络的过程中也的确发现自己有基础不牢、一些基本概念没搞清楚的问题,因此想借这门课程来个查漏补缺。目前的计划是先看到神经网络结束,后面的就不一定看了。
当然,看的过程中还是要做笔记做作业的,否则看了也是走马观花。此笔记只针对我个人,因此不会把已经会了的内容复述一遍,相当于是写给自己的一份笔记吧。如果有兴趣,可以移步《Machine Learning》仔细学习。
接下来是第一周的一些我认为需要格外注意的问题。
1 强调了hypothesis与cost函数究竟是“ it of who ”
设一个待拟合函数为y=θ1x+θ0,其中x为输入样本点,θi为待学习参数,这样一个表达式我们把它称之为hypothesis。在这门课程中,可以发现吴恩达老师在念h(x)时念的是“ h of x ”,意思是h是x的函数,在h(x)中x为自变量,即输入样本点x为自变量。
需要强调的是,对于hypothesis h(x),自变量为输入样本点x;而对于cost函数J(θ),这个自变量是待学习参数。所谓的梯度下降法常常给出的那个山一样的图,正是让参数θi密密地取很多很多个值,然后看θi取到多少时整个cost函数达到最低点。
2 梯度下降法
2-1 轮廓图
采用轮廓图的方式代替三维图。
比方说对于一个待拟合函数h(x)=θ1x+θ0,当参数有两个(θ1与θ0),则把cost函数画成三维图是长这样的:
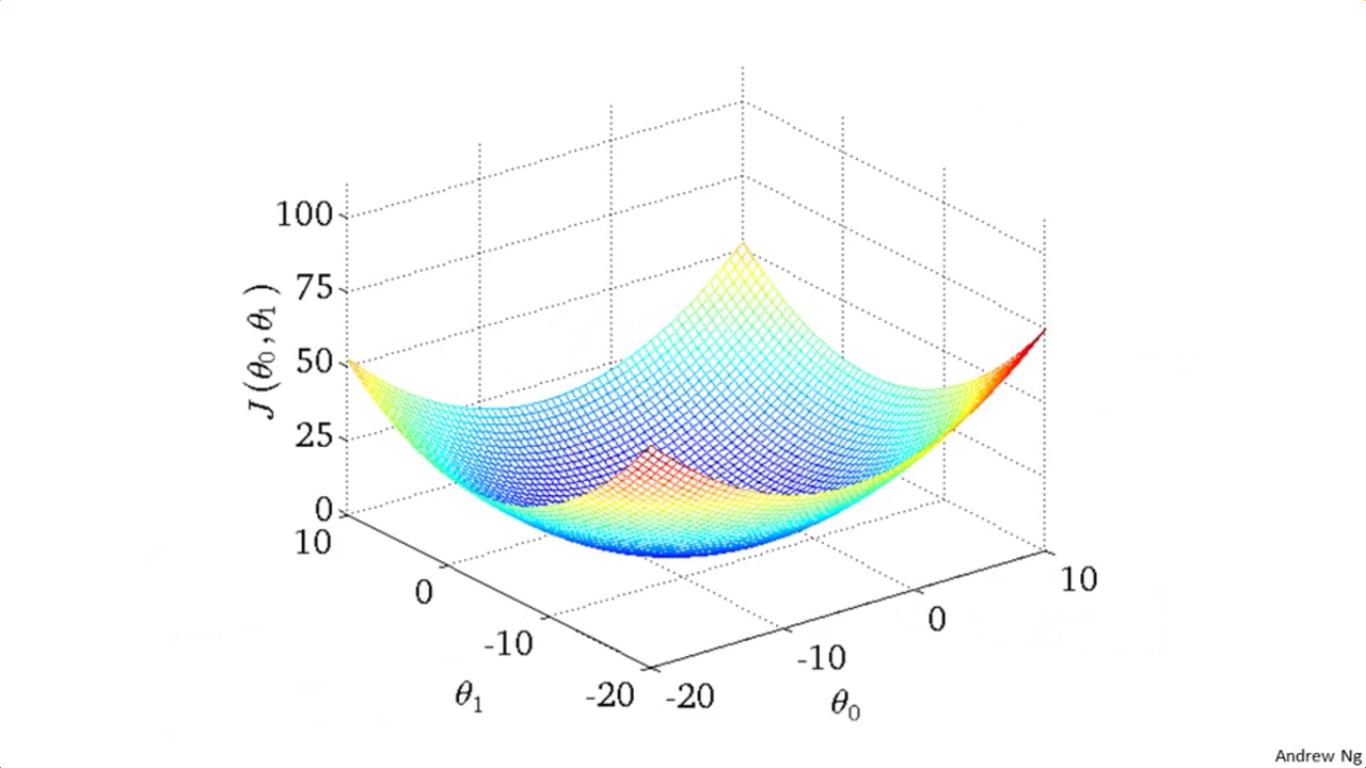
但是用轮廓图表述就是这样的:

如图所示,每一圈上的点它的cost函数值是一样的,相当于对一座山的俯视图吧。好比地理中画山不是画成立体的那个样子,而是以等高线图来表述,因此画的是一圈一圈的。
当极值点落在那个打红叉的位置,拟合结果就是左边这幅图的蓝色直线,可以发现这个时候的 θ1 与 θ0 对应的 hypothesis(即那条蓝色直线的直线方程) 就是一个不错的结果。打红叉的位置可说是这座山的最低谷处。
2-2 强调梯度下降法是所有参数同步更新
就直接拿这幅图说明好了……

上面一目了然地列出了啥叫同步更新,啥叫非同步更新。
好比神经网络一堆的权值,不是说改一个参数然后再算下一个梯度然后再改下一个参数的,而是一次性利用bp算法把所有的梯度值都算出来,并且对整个神经网络所有的参数值都实施同步更新。
原因也很显然,看看右边这个非同步更新的图,是把 θ0 的值都改了,然后你再拿这个改了之后的 θ0 去算 θ1 的梯度值,再去更新 θ1 ,这显然没意义。
(2016.6.28 记)
2-3 用“求导=求某一点处切线的斜率”来理解梯度下降法
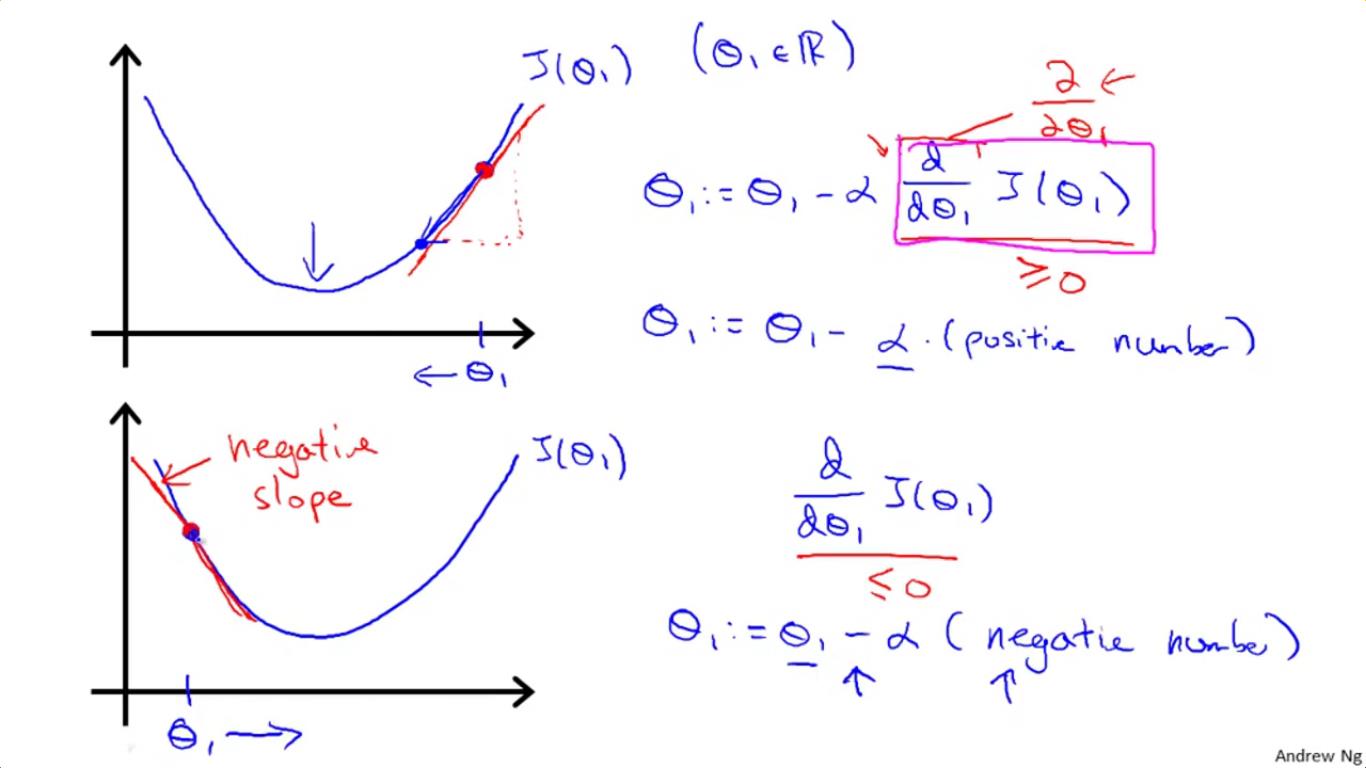
这个想法虽然简单,但是绝妙地用高中的基本导数知识解释了梯度下降法为何是往最低点走的。如图所示,横坐标为参数值θ1,纵坐标为cost函数。
(1)在上面那个图中,所取的点处的导数(即斜率)为正,而α为学习速率也为正,故[θ1-(导数值*α)]所得到的新的θ1是往左移了,也就是往cost更低的地方走去。
(2)在下面那个图中,当所取的点的导数为负,与(1)同理,可以发现这一次[θ1-(导数值*α)]增大了,所得到的新的θ1是往右移的,也一样是往cost更低的地方走去。
(2016.6.29记)
2-4 从“大跨步”到“小碎步”
以只有一个待确定参数为例,此时 cost 函数 J(θ1) 的图还是2-3中所示的那幅图。在这里我们以上面那个图为例,即初始点取在曲线的右半边。
如图所示,使用梯度下降法时,因为越往下走,斜率 dJ(θ1)/dθ1 越小,而学习率α不变,因此相应的,每次θ1所要减去的那个Δθ1会越来越小(梯度下降法更新参数:θ1←θ1-△θ1,其中△θ1=α*dJ(θ1)/dθ1),也就是步子越来越碎。
注意这个步子指的是横坐标上每次θ1朝左挪动多长的距离(即△θ1),这就是“从大跨步到小碎步”的含义。在这个过程中,即使不减小α,也可以实现△θ1逐步减小。
2-5 batch gradient descent
即批量梯度下降法。在这里给出了批量梯度下降法的概念,即每次更新权值时都使用全部的样本点。
我想这应该与之前经常用的“随机梯度下降法”相对,对于随机梯度下降法,正是为了解决一次性使用全部样本点会导致训练速度太慢的问题,因此随机梯度下降法每次都从训练样本点中抽取部分点来进行训练,如此一来保证了全部点都有可能被抽到,同时也不至于每次都把所有的点都过一遍,大大提升了速度。
3 线性回归总结
3-1 线性回归归根结底就是求参数θi
在此我想回顾一下第一周的整个过程:
第一周围绕的主题就是给定一堆样本点,然后用一条直线来拟合这些点,现在我们要用机器学习的方法求解这条直线的方程。
在机器学习中,这条待学习直线被称之为“hypothesis”,记为h(x),我们的目标是求得h(x)=θ1x+θ0,显然,只需要求得θ0和θ1的值,就能够得到这条直线的方程。
那么如何去求得这两个参数的值呢?我们定义了cost函数J(θ0,θ1),然后使用梯度下降法,通过调整θ0与θ1的值,来让cost函数持续下降。最后当cost函数减小到最低的时候,此时的θ0和θ1即我们所求。
因此本质上我们的线性回归,就是为了求得θ0和θ1的值。
3-2 线性回归的cost函数
对于线性回归,其cost函数必然是弓形的(凸函数),只有一个全局最低点,如图所示:
3-3 一道错题
这是在做测验的时候我做错的一道题,在此进行分析一下。原题目如下:
Suppose that for some linear regression problem (say, predicting housing prices as in the lecture), we have some training set, and for our training set we managed to find some θ0, θ1 such that J(θ0,θ1)=0. Which of the statements below must then be true?
翻译一下:假如说我们拟合好了一个hypothesis h(x),使得能够对所有的训练样本点达到cost函数的值为0,以下哪个是对的?
A. For these values of θ0 and θ1 that satisfy J(θ0,θ1)=0, we have that hθ(x(i))=y(i) for every training example (x(i),y(i))
【解析】这个是正确的,可以说明至少在训练集之内,每一个样本点都满足“label=网络输出”,即hθ(x(i))=y(i)。
B. For this to be true, we must have y(i)=0 for every value of i=1,2,…,m.
【解析】错误,跟训练样本点的y值是否等于0没有任何关系,只需要让所有的训练样本点落在拟合直线上就可以了。
C. Gradient descent is likely to get stuck at a local minimum and fail to find the global minimum.
【解析】错误,正如刚才所说,对于线性回归,只有一个全局最小值,所以不存在陷入局部这种问题。
D.We can perfectly predict the value of y even for new examples that we have not yet seen.
【解析】错误,说起来cost函数为0我的第一反应就是:是不是过拟合了……所以不一定能对新的实例达到100%正确预测。
4 线性代数基础
今天总结的时候才发现这门课的信息量其实也不小……第一周还有线代复习专栏。整理了一下自己觉得有帮助的内容发一下:
4-1 矩阵的维数
概念:矩阵的维数指的是“行×列”,用 R行×列 表示;而向量的维数指的是“该向量中有多少个元素”,用R维数表示。
比方说对于R3就是一个由世间所有三维向量所组成的集合(就像实数集R一样),里面的元素可以是:
a =
0.9649
0.1576
0.9706
而R3×4则是由全部 3×4 矩阵所组成的集合,里面的元素可以是:
b =
0.9572 0.1419 0.7922 0.0357
0.4854 0.4218 0.9595 0.8491
0.8003 0.9157 0.6557 0.9340
4-2 矩阵乘法
1、“矩阵与列向量乘法”一节视频的8分50秒处,有个利用矩阵乘法批量计算输出值的技巧。
2、“矩阵与矩阵乘法”一节中讲到,矩阵和矩阵相乘,可以把后面的矩阵视为由若干列向量组成,分别让前一个矩阵与这些列向量相乘,并把乘出的结果摆放在一起,即得矩阵与矩阵相乘的结果。
3、矩阵乘法不满足交换律,但满足结合律。
4-3 单位矩阵&矩阵的逆&矩阵转置
1、单位矩阵(identity matrix)
(1)首先说明一下什么是单位矩阵。单位矩阵记作I,它必然为n×n方阵,且对角线都是1。以下是MATLAB生成5×5单位矩阵的实例:
>> eye(5) ans = 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1
(2)对于单位矩阵,必满足A·I=I·A=A。
这里A可能为3×4矩阵,那么对于前一个I来说它是一个4×4单位阵,对于后一个I来说则是一个3×3单位阵。拿matlab试试如下:
>> a a = 0.6787 0.3922 0.7060 0.0462 0.6948 0.7577 0.6555 0.0318 0.0971 0.3171 0.7431 0.1712 0.2769 0.8235 0.9502 >> b b = 1 0 0 0 1 0 0 0 1 >> c c = 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 >> a*c ans = 0.6787 0.3922 0.7060 0.0462 0.6948 0.7577 0.6555 0.0318 0.0971 0.3171 0.7431 0.1712 0.2769 0.8235 0.9502 >> b*a ans = 0.6787 0.3922 0.7060 0.0462 0.6948 0.7577 0.6555 0.0318 0.0971 0.3171 0.7431 0.1712 0.2769 0.8235 0.9502
2、矩阵的逆(matrix inverse)
一个矩阵的逆,就好比一个常数的倒数一样,有AA^(-1)=A^(-1)A=I。其中:
(1)I为单位矩阵。
(2)A为方阵(“行数=列数”的矩阵称之为方针),只有方阵才有逆矩阵。
(3)以下是一个MATLAB求逆矩阵的操作:
>> a=[1,2;3,4] a = 1 2 3 4 >> b=inv(a) b = -2.0000 1.0000 1.5000 -0.5000 >> b b = -2.0000 1.0000 1.5000 -0.5000
可以很容易发现a与b的乘积正是一个单位矩阵I:
>> a*b ans = 1.0000 0 0.0000 1.0000
3、线性代数中的0和1
(1)单位矩阵I和常数1非常相似。
(2)不存在逆矩阵的矩阵叫做奇异矩阵(又叫退化矩阵),可以把它想象成是和0非常相似的东西(就像0也没有倒数一样)。比如全零矩阵没有逆矩阵,但看Ng老师的意思,退化矩阵一定不止只有全零矩阵一种。
4、矩阵的转置(matrix transpose)
(1)定义是:Aij=Bji,其中A、B互为转置矩阵。
(2)可以视为把矩阵分成若干行,然后每一行都以最左边元素为中心,顺时针旋转90度,由一行变成一列。然后再按顺序一列一列重新编排好。
(3)例如:
>> a=[1,2,3;4,5,6;7,8,9] a = 1 2 3 4 5 6 7 8 9 >> a\' ans = 1 4 7 2 5 8 3 6 9
step1:首先将矩阵拆成三行:[1,2,3]、[4,5,6]、[7,8,9];
step2:分别以最左边元素为旋转中心,顺时针旋转90度,得到3个列向量;
step3:把这三个列向量按顺序一列一列放好,得到:
[1] [4] [7]
[2] [5] [8]
[3] [6] [9]
(4)再给一个列向量的例子:
>> b=[3;6;9] b = 3 6 9 >> b\' ans = 3 6 9
这里仍然是把这个列向量跟矩阵一样处理。
step1:先拆成三行,每行只有一个元素:[3]、[6]、[9]。
step2:每行都以最左边的元素为旋转中心,顺时针旋转90度。由于现在每行只有一个元素,因此旋转完毕后得到的是其本身,得到的三个列向量分别为:[3]、[6]、[9]。
step3:将得到的列向量按顺序一列一列放好,得到:
[3] [6] [9]。
这就是矩阵转置具体该如何实施。
(2016.6.30记)
by 悠望南山
以上是关于Coursera课程《Machine Learning》学习笔记(week1)的主要内容,如果未能解决你的问题,请参考以下文章
Coursera课程《Machine Learning》学习笔记(week1)
Coursera课程《Machine Learning》学习笔记(week1)
Coursera《machine learning》--(14)数据降维
Coursera《machine learning》--单变量线性回归(Linear Regression with One Variable)