多线程中的volatile和伪共享
Posted 为爱奔跑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程中的volatile和伪共享相关的知识,希望对你有一定的参考价值。
伪共享 false sharing,顾名思义,“伪共享”就是“其实不是共享”。那什么是“共享”?多CPU同时访问同一块内存区域就是“共享”,就会产生冲突,需要控制协议来协调访问。会引起“共享”的最小内存区域大小就是一个cache line。因此,当两个以上CPU都要访问同一个cache line大小的内存区域时,就会引起冲突,这种情况就叫“共享”。但是,这种情况里面又包含了“其实不是共享”的“伪共享”情况。比如,两个处理器各要访问一个word,这两个word却存在于同一个cache line大小的区域里,这时,从应用逻辑层面说,这两个处理器并没有共享内存,因为他们访问的是不同的内容(不同的word)。但是因为cache line的存在和限制,这两个CPU要访问这两个不同的word时,却一定要访问同一个cache line块,产生了事实上的“共享”。显然,由于cache line大小限制带来的这种“伪共享”是我们不想要的,会浪费系统资源。
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解内存布局,或找个工具告诉我们。Intel VTune就是这样一个分析工具。
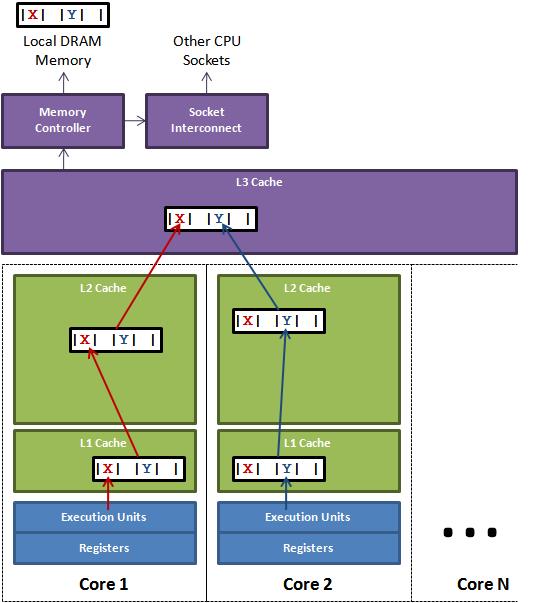
图1说明了伪共享的问题。在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
Java Memory Layout Java内存布局,在项目开发中,大多使用HotSpot的JVM,hotspot中对象都有两个字(四字节)长的对象头。第一个字是由24位哈希码和8位标志位(如锁的状态或作为锁对象)组成的Mark Word。第二个字是对象所属类的引用。如果是数组对象还需要一个额外的字来存储数组的长度。每个对象的起始地址都对齐于8字节以提高性能。因此当封装对象的时候为了高效率,对象字段声明的顺序会被重排序成下列基于字节大小的顺序:
- double (8字节) 和 long (8字节)
- int (4字节) 和 float (4字节)
- short (2字节) 和 char (2字节):char在java中是2个字节。java采用unicode,2个字节(16位)来表示一个字符。
- boolean (1字节) 和 byte (1字节)
- reference引用 (4/8 字节)
- <子类字段重复上述顺序>
在了解这些之后,就可以在任意字段间用7个long来填充缓存行。伪共享在不同的JDK下提供了不同的解决方案。
在JDK1.6环境下,解决伪共享的办法是使用缓存行填充,使一个对象占用的内存大小刚好为64bytes或它的整数倍,这样就保证了一个缓存行里不会有多个对象。
package basic; public class TestFlash implements Runnable { public final static int NUM_THREADS = 4; // change public final static long ITERATIONS = 500L * 1000L * 1000L; private final int arrayIndex; /** * 为了展示其性能影响,我们启动几个线程,每个都更新它自己独立的计数器。计数器是volatile long类型的,所以其它线程能看到它们的进展。 */ public final static class VolatileLong { /* 用volatile[ˈvɑ:lətl]修饰的变量,线程在每次使用变量的时候,JVM虚拟机只保证从主内存加载到线程工作内存的值是最新的 */ public volatile long value = 0L; /* 缓冲行填充 */ /* 37370571461 :不使用缓冲行执行纳秒数 */ /* 16174480826 :使用缓冲行执行纳秒数,性能提高一半 */ public long p1, p2, p3, p4, p5, p6, p7; } private static VolatileLong[] longs = new VolatileLong[NUM_THREADS]; static { for (int i = 0; i < longs.length; i++) { longs[i] = new VolatileLong(); } } public TestFlash(final int arrayIndex){ this.arrayIndex = arrayIndex; } /** * 我们不能确定这些VolatileLong会布局在内存的什么位置。它们是独立的对象。但是经验告诉我们同一时间分配的对象趋向集中于一块。 */ public static void main(final String[] args) throws Exception { final long start = System.nanoTime(); runTest(); System.out.println("duration = " + (System.nanoTime() - start)); } private static void runTest() throws InterruptedException { Thread[] threads = new Thread[NUM_THREADS]; for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(new TestFlash(i)); } for (Thread t : threads) { t.start(); } for (Thread t : threads) { t.join(); } } /* * 为了展示其性能影响,我们启动几个线程,每个都更新它自己独立的计数器。计数器是volatile long类型的,所以其它线程能看到它们的进展 */ @Override public void run() { long i = ITERATIONS + 1; while (0 != --i) { longs[arrayIndex].value = i; } } }
VolatileLong通过填充一些无用的字段p1,p2,p3,p4,p5,p6,再考虑到对象头也占用8bit, 刚好把对象占用的内存扩展到刚好占64bytes(或者64bytes的整数倍)。这样就避免了一个缓存行中加载多个对象。但这个方法现在只能适应JAVA6 及以前的版本了。
在jdk1.7环境下,由于java 7会优化掉无用的字段。因此,JAVA 7下做缓存行填充更麻烦了,需要使用继承的办法来避免填充被优化掉。把填充放在基类里面,可以避免优化(这好像没有什么道理好讲的,JAVA7的内存优化算法问题,能绕则绕)。
package basic; public class TestFlashONJDK7 implements Runnable { public static int NUM_THREADS = 4; public final static long ITERATIONS = 500L * 1000L * 1000L; private final int arrayIndex; private static VolatileLong[] longs; public TestFlashONJDK7(final int arrayIndex){ this.arrayIndex = arrayIndex; } public static void main(final String[] args) throws Exception { Thread.sleep(10000); System.out.println("starting...."); if (args.length == 1) { NUM_THREADS = Integer.parseInt(args[0]); } longs = new VolatileLong[NUM_THREADS]; for (int i = 0; i < longs.length; i++) { longs[i] = new VolatileLong(); } final long start = System.nanoTime(); runTest(); System.out.println("duration = " + (System.nanoTime() - start)); } private static void runTest() throws InterruptedException { Thread[] threads = new Thread[NUM_THREADS]; for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(new TestFlashONJDK7(i)); } for (Thread t : threads) { t.start(); } for (Thread t : threads) { t.join(); } } @Override public void run() { long i = ITERATIONS + 1; while (0 != --i) { longs[arrayIndex].value = i; } } } class VolatileLong extends VolatileLongPadding { public volatile long value = 0L; } class VolatileLongPadding { public volatile long p1, p2, p3, p4, p5, p6, p7; }
在jdk1.8环境下,缓存行填充终于被JAVA原生支持了。JAVA 8中添加了一个@Contended的注解,添加这个的注解,将会在自动进行缓存行填充。以上的例子可以改为:
package basic; public class TestFlashONJDK8 implements Runnable { public static int NUM_THREADS = 4; public final static long ITERATIONS = 500L * 1000L * 1000L; private final int arrayIndex; private static VolatileLong[] longs; public TestFlashONJDK8(final int arrayIndex){ this.arrayIndex = arrayIndex; } public static void main(final String[] args) throws Exception { Thread.sleep(10000); System.out.println("starting...."); if (args.length == 1) { NUM_THREADS = Integer.parseInt(args[0]); } longs = new VolatileLong[NUM_THREADS]; for (int i = 0; i < longs.length; i++) { longs[i] = new VolatileLong(); } final long start = System.nanoTime(); runTest(); System.out.println("duration = " + (System.nanoTime() - start)); } private static void runTest() throws InterruptedException { Thread[] threads = new Thread[NUM_THREADS]; for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(new TestFlashONJDK8(i)); } for (Thread t : threads) { t.start(); } for (Thread t : threads) { t.join(); } } @Override public void run() { long i = ITERATIONS + 1; while (0 != --i) { longs[arrayIndex].value = i; } } }
@Contended
class VolatileLong {
public volatile long value = 0L;
}
执行时,必须加上虚拟机参数-XX:-RestrictContended,@Contended注释才会生效。很多文章把这个漏掉了,那样的话实际上就没有起作用。
补充:
byte字节 bit位 1byte=8bit
volatile说明
package basic; public class TestVolatile { public static int count = 0; /* 即使使用volatile,依旧没有达到我们期望的效果 */ // public volatile static int count = 0; public static void increase() { try { // 延迟10毫秒,使得结果明显 Thread.sleep(10); count++; } catch (InterruptedException e) { e.printStackTrace(); } } public static void main(String[] args) { for (int i = 0; i < 10000; i++) { new Thread(new Runnable() { @Override public void run() { TestVolatile.increase(); } }).start(); } System.out.println("期望运行结果:10000"); System.out.println("实际运行结果:" + TestVolatile.count); } }
volatile关键字的使用:用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最新值。但是由于操作不是原子性的,对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的。
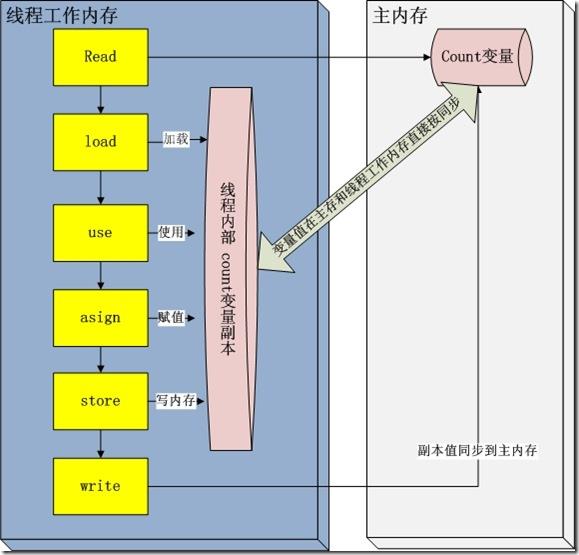
在java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。上面一幅图描述这些交互,过程如下:
- read and load 从主存复制变量到当前工作内存
- use and assign 执行代码,改变共享变量值(其中use and assign 可以多次出现)
- store and write 用工作内存数据刷新主存相关内容
但是这些操作并不是原子性,也就是在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样。对于volatile修饰的变量,JVM虚拟机只是保证从主内存加载到线程工作内存的值是最新的。例如假如线程1,线程2在进行read load操作中,发现主内存中count的值都是5,那么都会加载这个最新的值。在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6。线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6。导致两个线程即使使用volatile关键字修改之后,还是会存在并发的情况。
对于volatile修饰的变量,JVM虚拟机只能保证从主内存加载到线程工作内存的值是最新的。
参考博客:
[1] http://www.cnblogs.com/Binhua-Liu/p/5620339.html
以上是关于多线程中的volatile和伪共享的主要内容,如果未能解决你的问题,请参考以下文章
Java 并发编程 -- 并发编程线程基础(线程安全问题可见性问题synchronized / volatile 关键字CASUnsafe指令重排序伪共享Java锁的概述)
Java 并发编程 -- 并发编程线程基础(线程安全问题可见性问题synchronized / volatile 关键字CASUnsafe指令重排序伪共享Java锁的概述)
多线程知识梳理,当我们谈到volatile的时候,我们在谈什么?
多线程---再次认识volatile,Synchronize,lock