linux 查看服务器性能常用命令
Posted 爱你爱自己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux 查看服务器性能常用命令相关的知识,希望对你有一定的参考价值。
1.命令格式:
top [参数]
2.命令功能:
显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等
3.命令参数:
-b 批处理
-c 显示完整的治命令
-I 忽略失效过程
-s 保密模式
-S 累积模式
-i<时间> 设置间隔时间
-u<用户名> 指定用户名
-p<进程号> 指定进程
-n<次数> 循环显示的次数
4.使用实例:
实例1:显示进程信息
命令:top
输出:
[root@TG1704 log]# top
top - 14:06:23 up 70 days, 16:44, 2 users, load average: 1.25, 1.32, 1.35
Tasks: 206 total, 1 running, 205 sleeping, 0 stopped, 0 zombie
Cpu(s): 5.9%us, 3.4%sy, 0.0%ni, 90.4%id, 0.0%wa, 0.0%hi, 0.2%si, 0.0%st
Mem: 32949016k total, 14411180k used, 18537836k free, 169884k buffers
Swap: 32764556k total, 0k used, 32764556k free, 3612636k cached</p>< p>PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28894 root 22 0 1501m 405m 10m S 52.2 1.3 2534:16 java
18249 root 18 0 3201m 1.9g 11m S 35.9 6.0 569:39.41 java
2808 root 25 0 3333m 1.0g 11m S 24.3 3.1 526:51.85 java
25668 root 23 0 3180m 704m 11m S 14.0 2.2 360:44.53 java
574 root 25 0 3168m 611m 10m S 12.6 1.9 556:59.63 java
1599 root 20 0 3237m 1.9g 11m S 12.3 6.2 262:01.14 java
1008 root 21 0 3147m 842m 10m S 0.3 2.6 4:31.08 java
13823 root 23 0 3031m 2.1g 10m S 0.3 6.8 176:57.34 java
28218 root 15 0 12760 1168 808 R 0.3 0.0 0:01.43 top
29062 root 20 0 1241m 227m 10m S 0.3 0.7 2:07.32 java
1 root 15 0 10368 684 572 S 0.0 0.0 1:30.85 init
2 root RT -5 0 0 0 S 0.0 0.0 0:01.01 migration/0
3 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
4 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
5 root RT -5 0 0 0 S 0.0 0.0 0:00.80 migration/1
6 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/1
7 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/1
8 root RT -5 0 0 0 S 0.0 0.0 0:20.59 migration/2
9 root 34 19 0 0 0 S 0.0 0.0 0:00.09 ksoftirqd/2
10 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/2
11 root RT -5 0 0 0 S 0.0 0.0 0:23.66 migration/3
12 root 34 19 0 0 0 S 0.0 0.0 0:00.03 ksoftirqd/3
13 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/3
14 root RT -5 0 0 0 S 0.0 0.0 0:20.29 migration/4
15 root 34 19 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/4
16 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/4
17 root RT -5 0 0 0 S 0.0 0.0 0:23.07 migration/5
18 root 34 19 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/5
19 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/5
20 root RT -5 0 0 0 S 0.0 0.0 0:17.16 migration/6
21 root 34 19 0 0 0 S 0.0 0.0 0:00.05 ksoftirqd/6
22 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/6
23 root RT -5 0 0 0 S 0.0 0.0 0:58.28 migration/7
top命令输出内容详细说明:
统计信息区:
前五行是当前系统情况整体的统计信息区。下面我们看每一行信息的具体意义。
第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下:
14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
5.9%us — 用户空间占用CPU的百分比。
3.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
90.4% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.2% si — 软中断(Software Interrupts)占用CPU的百分比
备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!
第四行,内存状态,具体信息如下:
32949016k total — 物理内存总量(32GB)
14411180k used — 使用中的内存总量(14GB)
18537836k free — 空闲内存总量(18GB)
169884k buffers — 缓存的内存量 (169M)
第五行,swap交换分区信息,具体信息说明如下:
32764556k total — 交换区总量(32GB)
0k used — 使用的交换区总量(0K)
32764556k free — 空闲交换区总量(32GB)
3612636k cached — 缓冲的交换区总量(3.6GB)
备注:
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:18537836k +169884k +3612636k = 22GB左右。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
其他使用技巧:
1.多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
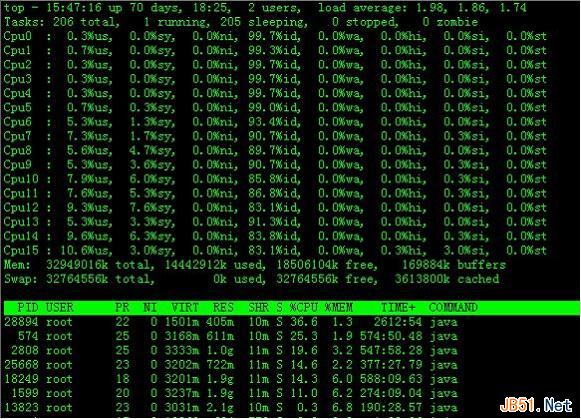
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。再按数字键1,就会返回到top基本视图界面。
2.高亮显示当前运行进程
敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
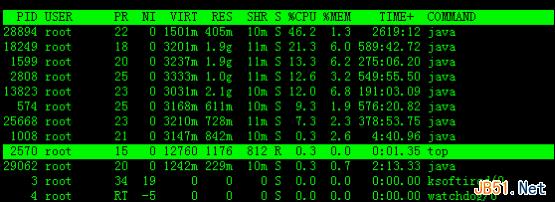
我们发现进程id为2570的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
3.进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的,在下图中进程ID为28894的java进程排在第一(cpu占用142%),进程ID为574的java进程排在第二(cpu占用16%)。
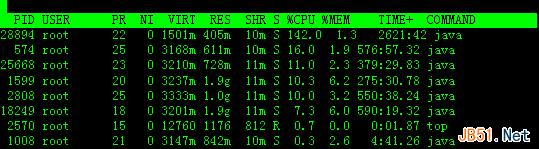
敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
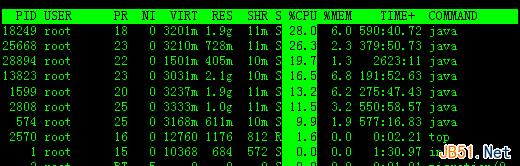
可以看到,top默认的排序列是“%CPU”。
4. 通过”shift + >”或”shift + <”可以向右或左改变排序列
下图是按一次”shift + >”的效果图,视图现在已经按照%MEM来排序。
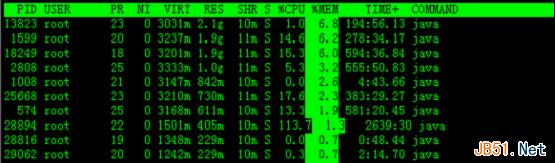
实例2:显示 完整命令
命令:top -c
输出:
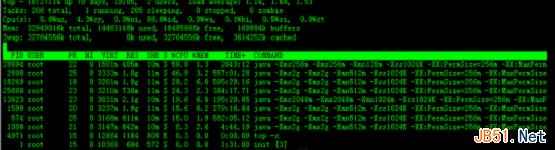
实例3:以批处理模式显示程序信息
命令:top -b
实例4:以累积模式显示程序信息
命令:top -S
实例5:设置信息更新次数
命令:top -n 2
说明:表示更新两次后终止更新显示
实例6:设置信息更新时间
命令:top -d 3
说明:表示更新周期为3秒
实例7:显示指定的进程信息
命令:top -p 574
输出:
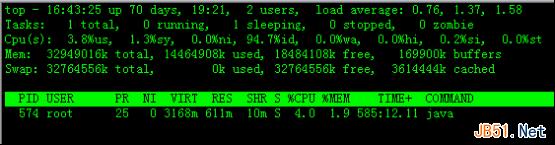
5.top交互命令
在top 命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了s 选项, 其中一些命令可能会被屏蔽。
h 显示帮助画面,给出一些简短的命令总结说明
k 终止一个进程。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序
r 重新安排一个进程的优先级别
S 切换到累计模式
s 改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s
f或者F 从当前显示中添加或者删除项目
o或者O 改变显示项目的顺序
l 切换显示平均负载和启动时间信息
m 切换显示内存信息
t 切换显示进程和CPU状态信息
c 切换显示命令名称和完整命令行
M 根据驻留内存大小进行排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
W 将当前设置写入~/.toprc文件中/bin/ps
ps 是显示瞬间行程的状态,并不动态连续;如果想对进程运行时间监控,应该用 top 工具。
kill 用于杀死进程。
==============ps 的参数说明============================
l 长格式输出;
u 按用户名和启动时间的顺序来显示进程;
j 用任务格式来显示进程;
f 用树形格式来显示进程;
a 显示所有用户的所有进程(包括其它用户);
x 显示无控制终端的进程;
r 显示运行中的进程;
ww 避免详细参数被截断;
-A 列出所有的行程
-w 显示加宽可以显示较多的资讯
-au 显示较详细的资讯
-aux 显示所有包含其他使用者的行程
-e 显示所有进程,环境变量
-f 全格式
-h 不显示标题
-l 长格式
-w 宽输出
a 显示终端上地所有进程,包括其他用户地进程
r 只显示正在运行地进程
x 显示没有控制终端地进程
我们常用的选项是组合是 aux 或 lax,还有参数 f 的应用。
O[+|-] k1 [,[+|-] k2 [,…]] 根据SHORT KEYS、k1、k2中快捷键指定地多级排序顺序显示进程列表.
对于ps地不同格式都存在着默认地顺序指定.这些默认顺序可以被用户地指定所覆盖.在这里面“+”字符是可选地,“-”字符是倒转指定键地方向.
pids只列出进程标识符,之间运用逗号分隔.该进程列表必须在命令行参数地最后一个选项后面紧接着给出,中间不能插入空格.比如:ps -f1,4,5.
下介绍长命令行选项,这些选项都运用“--”开头:
--sort X[+|-] key [,[+|-] key [,…]] 从SORT KEYS段中选一个多字母键.“+”字符是可选地,因为默认地方向就是按数字升序或者词典顺序.比如: ps -jax -sort=uid,-
ppid,+pid.
--help 显示帮助信息.
--version 显示该命令地版本信息.
在前面地选项说明中提到了排序键,接下来对排序键作进一步说明.需要注意地是排序中运用地值是ps运用地内部值,并非仅用于某些输出格式地伪值.排序键列表见下表.
============排序键列表==========================
c cmd 可执行地简单名称
C cmdline 完整命令行
f flags 长模式标志
g pgrp 进程地组ID
G tpgid 控制tty进程组ID
j cutime 累计用户时间
J cstime 累计系统时间
k utime 用户时间
K stime 系统时间
m min_flt 次要页错误地数量
M maj_flt 重点页错误地数量
n cmin_flt 累计次要页错误
N cmaj_flt 累计重点页错误
o session 对话ID
p pid 进程ID
P ppid 父进程ID
r rss 驻留大小
R resident 驻留页
s size 内存大小(千字节)
S share 共享页地数量
t tty tty次要设备号
T start_time 进程启动地时间
U uid UID
u user 用户名
v vsize 总地虚拟内存数量(字节)
y priority 内核调度优先级
================================================
=================ps aux 或 lax 输出的解释=========================
2、ps aux 或 lax 输出的解释
au(x) 输出格式 :
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
USER: 进程所有者
PID: 进程ID
%CPU: 占用的 CPU 使用率
%MEM: 占用的内存使用率
VSZ: 占用的虚拟内存大小
RSS: 占用的内存大小
TTY: 终端的次要装置号码 (minor device number of tty)
STAT: 进程状态:
START: 启动进程的时间;
TIME: 进程消耗CPU的时间;
COMMAND:命令的名称和参数;
=================进程STAT状态====================
D 无法中断的休眠状态(通常 IO 的进程);
R 正在运行,在可中断队列中;
S 处于休眠状态,静止状态;
T 停止或被追踪,暂停执行;
W 进入内存交换(从内核2.6开始无效);
X 死掉的进程;
Z 僵尸进程不存在但暂时无法消除;
W: 没有足够的记忆体分页可分配
WCHAN 正在等待的进程资源;
<: 高优先级进程
N: 低优先序进程
L: 有记忆体分页分配并锁在记忆体内 (即时系统或捱A I/O),即,有些页被锁进内存
s 进程的领导者(在它之下有子进程);
l 多进程的(使用 CLONE_THREAD, 类似 NPTL pthreads);
+ 位于后台的进程组;
================kill 终止进程=========================
kill 终止进程
有十几种控制进程的方法,下面是一些常用的方法:
kill -STOP [pid]
发送SIGSTOP (17,19,23)停止一个进程,而并不消灭这个进程。
kill -CONT [pid]
发送SIGCONT (19,18,25)重新开始一个停止的进程。
kill -KILL [pid]
发送SIGKILL (9)强迫进程立即停止,并且不实施清理操作。
kill -9 -1
终止你拥有的全部进程。
SIGKILL 和 SIGSTOP 信号不能被捕捉、封锁或者忽略,但是,其它的信号可以。所以这是你的终极武器。
=================范例========================
$ ps
PID TTY TIME COMMAND
5800 ttyp0 00:00:00 bash
5835 ttyp0 00:00:00 ps
可以看到,显示地项目共分为四项,依次为PID(进程ID)、TTY(终端名称)、TIME(进程执行时间)、COMMAND(该进程地命令行输入).
可以运用u选项来查看进程所有者及其他少许详细信息,如下所示:
$ ps u
USER PID %CPU %MEM USZ RSS TTY STAT START TIME COMMAND
test 5800 0.0 0.4 1892 1040 ttyp0 S Nov27 0:00 -bash
test 5836 0.0 0.3 2528 856 ttyp0 R Nov27 0:00 ps u
在bash进程前面有条横线,意味着该进程便是用户地登录shell,所以对于一个登录用户来说带短横线地进程只有一个.还可以看到%CPU、%MEM两个选项,前者指该进程占用地CPU时间
和总时间地百分比;后者指该进程占用地内存和总内存地百分比.
在这种情况下看到了所有控制终端地进程;当然对于其他那些没有控制终端地进程还是没有观察到,所以这时就需要运用x选项.运用x选项可以观察到所有地进程情况.
1)ps a 显示现行终端机下的所有程序,包括其他用户的程序。
2)ps -A 显示所有程序。
3)ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
4)ps -e 此参数的效果和指定"A"参数相同。
5)ps e 列出程序时,显示每个程序所使用的环境变量。
6)ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
7)ps -H 显示树状结构,表示程序间的相互关系。
8)ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
9)ps s 采用程序信号的格式显示程序状况。
10)ps S 列出程序时,包括已中断的子程序资料。
11)ps -t<终端机编号> 指定终端机编号,并列出属于该终端机的程序的状况。
12)ps u 以用户为主的格式来显示程序状况。
13)ps x 显示所有程序,不以终端机来区分。
三、虚拟内存的实时监控工具vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@ubuntu:~# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 3498472 315836 3819540 0 0 0 1 2 0 0 0 100 0
2表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:
root@ubuntu:~# vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 3499840 315836 3819660 0 0 0 1 2 0 0 0 100 0
0 0 0 3499584 315836 3819660 0 0 0 0 88 158 0 0 100 0
0 0 0 3499708 315836 3819660 0 0 0 2 86 162 0 0 100 0
0 0 0 3499708 315836 3819660 0 0 0 10 81 151 0 0 100 0
1 0 0 3499732 315836 3819660 0 0 0 2 83 154 0 0 100 0
这表示vmstat每2秒采集数据,一直采集,直到我结束程序,这里采集了5次数据我就结束了程序。
好了,命令介绍完毕,现在开始实战讲解每个参数的意思。
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 每秒从块设备接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 每秒向块设备发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
r: The number of processes waiting for run time.
b: The number of processes in uninterruptible sleep.
swpd: the amount of virtual memory used.
free: the amount of idle memory.
buff: the amount of memory used as buffers.
cache: the amount of memory used as cache.
inact: the amount of inactive memory. (-a option)
active: the amount of active memory. (-a option)
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
bi: Blocks received from a block device (blocks/s).
bo: Blocks sent to a block device (blocks/s).
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
Reads
total: Total reads completed successfully
merged: grouped reads (resulting in one I/O)
sectors: Sectors read successfully
ms: milliseconds spent reading
total: Total writes completed successfully
merged: grouped writes (resulting in one I/O)
sectors: Sectors written successfully
ms: milliseconds spent writing
cur: I/O in progress
s: seconds spent for I/O
reads: Total number of reads issued to this partition
read sectors: Total read sectors for partition
writes : Total number of writes issued to this partition
requested writes: Total number of write requests made for partition
Procs
r: The number of processes waiting for run time.
b: The number of processes in uninterruptible sleep.
swpd: the amount of virtual memory used.
free: the amount of idle memory.
buff: the amount of memory used as buffers.
cache: the amount of memory used as cache.
inact: the amount of inactive memory. (-a option)
active: the amount of active memory. (-a option)
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
bi: Blocks received from a block device (blocks/s).
bo: Blocks sent to a block device (blocks/s).
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
语法
mpstat [-P {|ALL}] [internal [count]]
参数 解释
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal 相邻的两次采样的间隔时间、
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。
实例
查看多核CPU核心的当前运行状况信息, 每2秒更新一次
mpstat 219:45:12 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 19:45:14 all 0.04 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.96 19:45:16 all 0.00 0.00 0.00 0.03 0.00 0.00 0.00 0.00 99.97 19:45:18 all 0.00 0.07 0.07 0.00 0.00 0.00 0.00 0.00 99.87
如果要看每个cpu核心的详细当前运行状况信息,输出如下:

mpstat -P ALL 2 19:43:58 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 19:43:59 all 0.00 0.00 0.04 0.00 0.00 0.00 0.00 0.00 99.96 19:43:59 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 19:43:59 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 ....... 19:43:59 13 0.99 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.01 19:43:59 14 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 19:43:59 15 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
字段的含义如下
%user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100 %nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100 %sys 在internal时间段里,内核时间(%) (system/total)*100 %iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100 %irq 在internal时间段里,硬中断时间(%) (irq/total)*100 %soft 在internal时间段里,软中断时间(%) (softirq/total)*100 %idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
计算公式如下
total_cur=user+system+nice+idle+iowait+irq+softirq total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq user=user_cur – user_pre total=total_cur-total_pre 其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。
五、设备IO负载的实时监控工具 iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。iostat属于sysstat软件包。可以用yum install sysstat 直接安装。
1.命令格式:
iostat[参数][时间][次数]
2.命令功能:
通过iostat方便查看CPU、网卡、tty设备、磁盘、CD-ROM 等等设备的活动情况, 负载信息。
3.命令参数:
-C 显示CPU使用情况
-d 显示磁盘使用情况
-k 以 KB 为单位显示
-m 以 M 为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS 使用情况
-p[磁盘] 显示磁盘和分区的情况
-t 显示终端和CPU的信息
-x 显示详细信息
-V 显示版本信息
4.使用实例:
iostat -d -k 2
参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;2表示,数据显示每隔2秒刷新一次。
输出如下
iostat -d -k 1 10 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 39.29 21.14 1.44 441339807 29990031 sda1 0.00 0.00 0.00 1623 523 sda2 1.32 1.43 4.54 29834273 94827104 sda3 6.30 0.85 24.95 17816289 520725244 sda5 0.85 0.46 3.40 9543503 70970116 sda6 0.00 0.00 0.00 550 236 sda7 0.00 0.00 0.00 406 0 sda8 0.00 0.00 0.00 406 0 sda9 0.00 0.00 0.00 406 0 sda10 60.68 18.35 71.43 383002263 1490928140 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 327.55 5159.18 102.04 5056 100 sda1 0.00 0.00 0.00 0 0
输出信息的意义
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。 kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量; kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
上面的例子中,我们可以看到磁盘sda以及它的各个分区的统计数据,当时统计的磁盘总TPS是39.29,下面是各个分区的TPS。(因为是瞬间值,所以总TPS并不严格等于各个分区TPS的总和)
指定监控的设备名称为sda,该命令的输出结果和上面命令完全相同。
iostat -d sda 2
默认监控所有的硬盘设备,现在指定只监控sda。
-x 参数
iostat还有一个比较常用的选项-x,该选项将用于显示和io相关的扩展数据。
iostat -d -x -k 1 10 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util sda 1.56 28.31 7.80 31.49 42.51 2.92 21.26 1.46 1.16 0.03 0.79 2.62 10.28 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util sda 2.00 20.00 381.00 7.00 12320.00 216.00 6160.00 108.00 32.31 1.75 4.50 2.17 84.20
输出信息的含义
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
rsec/s:每秒读取的扇区数;
wsec/:每秒写入的扇区数。
rKB/s:The number of read requests that were issued to the device per second;
wKB/s:The number of write requests that were issued to the device per second;
avgrq-sz 平均请求扇区的大小
avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。
await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
svctm 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长, 系统上运行的应用程序将变慢。
%util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度
。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
-c 参数
iostat还可以用来获取cpu部分状态值:
iostat -c 1 10 avg-cpu: %user %nice %sys %iowait %idle 1.98 0.00 0.35 11.45 86.22 avg-cpu: %user %nice %sys %iowait %idle 1.62 0.00 0.25 34.46 63.67
常见用法
iostat -d -k 1 10 #查看TPS和吞吐量信息(磁盘读写速度单位为KB) iostat -d -m 2 #查看TPS和吞吐量信息(磁盘读写速度单位为MB) iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await) iostat -c 1 10 #查看cpu状态
实例分析
ostat -d -k 1 |grep sda10 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda10 60.72 18.95 71.53 395637647 1493241908 sda10 299.02 4266.67 129.41 4352 132 sda10 483.84 4589.90 4117.17 4544 4076 sda10 218.00 3360.00 100.00 3360 100 sda10 546.00 8784.00 124.00 8784 124 sda10 827.00 13232.00 136.00 13232 136
上面看到,磁盘每秒传输次数平均约400;每秒磁盘读取约5MB,写入约1MB。
iostat -d -x -k 1 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util sda 1.56 28.31 7.84 31.50 43.65 3.16 21.82 1.58 1.19 0.03 0.80 2.61 10.29 sda 1.98 24.75 419.80 6.93 13465.35 253.47 6732.67 126.73 32.15 2.00 4.70 2.00 85.25 sda 3.06 41.84 444.90 54.08 14204.08 2048.98 7102.04 1024.49 32.57 2.10 4.21 1.85 92.24
可以看到磁盘的平均响应时间<5ms,磁盘使用率>80。磁盘响应正常,但是已经很繁忙了。
六、查看当前系统内存使用状况(free):
free命令有以下几个常用选项:
| 选项 | 说明 |
| -b | 以字节为单位显示数据。 |
| -k | 以千字节(KB)为单位显示数据(缺省值)。 |
| -m | 以兆(MB)为单位显示数据。 |
| -s delay | 该选项将使free持续不断的刷新,每次刷新之间的间隔为delay指定的秒数,如果含有小数点,将精确到毫秒,如0.5为500毫秒,1为一秒。 |
free命令输出的表格中包含以下几列:
| 列名 | 说明 |
| total | 总计物理内存的大小。 |
| used | 已使用的内存数量。 |
| free | 可用的内存数量。 |
| Shared | 多个进程共享的内存总额。 |
| Buffers/cached | 磁盘缓存的大小。 |
见以下具体示例和输出说明:
/> free -k
total used free shared buffers cached
Mem: 1031320 671776 359544 0 88796 352564
-/+ buffers/cache: 230416 800904
Swap: 204792 0 204792
对于free命令的输出,我们只需关注红色高亮的输出行和绿色高亮的输出行,见如下具体解释:
红色输出行:该行使从操作系统的角度来看待输出数据的,used(671776)表示内核(Kernel)+Applications+buffers+cached。free(359544)表示系统还有多少内存可供使用。
绿色输出行:该行则是从应用程序的角度来看输出数据的。其free = 操作系统used + buffers + cached,既:
800904 = 359544 + 88796 + 352564
/> free -m
total used free shared buffers cached
Mem: 1007 656 351 0 86 344
-/+ buffers/cache: 225 782
Swap: 199 0 199
/> free -k -s 1.5 #以千字节(KB)为单位显示数据,同时每隔1.5刷新输出一次,直到按CTRL+C退出
total used free shared buffers cached
Mem: 1007 655 351 0 86 344
-/+ buffers/cache: 224 782
Swap: 199 0 199
total used free shared buffers cached
Mem: 1007 655 351 0 86 344
-/+ buffers/cache: 224 782
Swap: 199 0 199
七、报告磁盘空间使用状况(df):
该命令最为常用的选项就是-h,该选项将智能的输出数据单位,以便使输出的结果更具可读性。
/> df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 5.8G 3.3G 2.2G 61% /
tmpfs 504M 260K 504M 1% /dev/shm
八、评估磁盘的使用状况(du):
| 选项 | 说明 |
| -a | 包括了所有的文件,而不只是目录。 |
| -b | 以字节为计算单位。 |
| -k | 以千字节(KB)为计算单位。 |
| -m | 以兆字节(MB)为计算单位。 |
| -h | 是输出的信息更易于阅读。 |
| -s | 只显示工作目录所占总空间。 |
| --exclude=PATTERN | 排除掉符合样式的文件,Pattern就是普通的Shell样式,?表示任何一个字符,*表示任意多个字符。 |
| --max-depth=N | 从当前目录算起,目录深度大于N的子目录将不被计算,该选项不能和s选项同时存在。 |
#仅显示子一级目录的信息。
/> du --max-depth=1 -h
246M ./stephen
246M .
/> du -sh ./* #获取当前目录下所有子目录所占用的磁盘空间大小。
352K ./MemcachedTest
132K ./Test
33M ./thirdparty
#在当前目录下,排除目录名模式为Te*的子目录(./Test),输出其他子目录占用的磁盘空间大小。
/> du --exclude=Te* -sh ./*
352K ./MemcachedTest
33M ./thirdparty
sar
sar [options] [-A] [-o file] t [n]
在命令行中,n 和t 两个参数组合起来定义采样间隔和次数,t为采样间隔,是必须有
的参数,n为采样次数,是可选的,默认值是1,-o file表示将命令结果以二进制格式
存放在文件中,file 在此处不是关键字,是文件名。options 为命令行选项,sar命令
的选项很多,下面只列出常用选项:
-A:所有报告的总和。
-u:CPU利用率
-v:进程、I节点、文件和锁表状态。
-d:硬盘使用报告。
-r:内存和交换空间的使用统计。
-g:串口I/O的情况。
-b:缓冲区使用情况。
-a:文件读写情况。
-c:系统调用情况。
-q:报告队列长度和系统平均负载
-R:进程的活动情况。
-y:终端设备活动情况。
-w:系统交换活动。
-x { pid | SELF | ALL }:报告指定进程ID的统计信息,SELF关键字是sar进程本身的统计,ALL关键字是所有系统进程的统计。
用sar进行CPU利用率的分析
#sar -u 2 10
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/28/2009
07:40:17 PM CPU %user %nice %system %iowait %steal %idle
07:40:19 PM all 12.44 0.00 6.97 1.74 0.00 78.86
07:40:21 PM all 26.75 0.00 12.50 16.00 0.00 44.75
07:40:23 PM all 16.96 0.00 7.98 0.00 0.00 75.06
07:40:25 PM all 22.50 0.00 7.00 3.25 0.00 67.25
07:40:27 PM all 7.25 0.00 2.75 2.50 0.00 87.50
07:40:29 PM all 20.05 0.00 8.56 2.93 0.00 68.46
07:40:31 PM all 13.97 0.00 6.23 3.49 0.00 76.31
07:40:33 PM all 8.25 0.00 0.75 3.50 0.00 87.50
07:40:35 PM all 13.25 0.00 5.75 4.00 0.00 77.00
07:40:37 PM all 10.03 0.00 0.50 2.51 0.00 86.97
Average: all 15.15 0.00 5.91 3.99 0.00 74.95
在显示内容包括:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
在所有的显示中,我们应主要注意%iowait和%idle,%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
用sar进行运行进程队列长度分析:
#sar -q 2 10
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/28/2009
07:58:14 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
07:58:16 PM 0 493 0.64 0.56 0.49
07:58:18 PM 1 491 0.64 0.56 0.49
07:58:20 PM 1 488 0.59 0.55 0.49
07:58:22 PM 0 487 0.59 0.55 0.49
07:58:24 PM 0 485 0.59 0.55 0.49
07:58:26 PM 1 483 0.78 0.59 0.50
07:58:28 PM 0 481 0.78 0.59 0.50
07:58:30 PM 1 480 0.72 0.58 0.50
07:58:32 PM 0 477 0.72 0.58 0.50
07:58:34 PM 0 474 0.72 0.58 0.50
Average: 0 484 0.68 0.57 &
以上是关于linux 查看服务器性能常用命令的主要内容,如果未能解决你的问题,请参考以下文章