网络爬虫--小实战
Posted haoliuhust
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫--小实战相关的知识,希望对你有一定的参考价值。
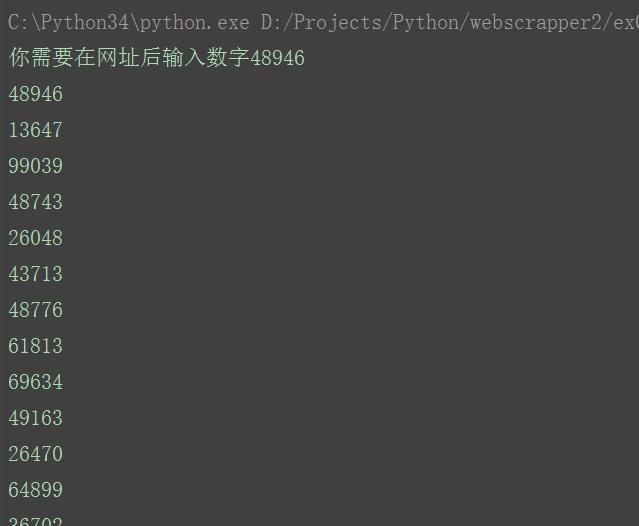
到目前为止,我们学习了如何访问远程网站,如何解析页面内容,是时候开始应用一下了。在这里,我们以通过http://www.heibanke.com/lesson/crawler_ex00/为例,这个网站会告诉我们爬虫应该向哪里链接,直到爬到通过为止。
首先我们需要查看网页的源代码,确定我们需要的信息在哪里。通过查看源代码,我们可以知道,我们关注的信息应该是h3标签文本中的数字。

因此我们的任务就是提取出这个数字,然后链接到新的地址,直到完成为止。
首先我们从BeautifulSoup中提取出标签h3中的文本,然后通过正则表达式分解出里面的数字,将数字加入地址,继续访问新地址,知道没有数字为止。
1 # coding=utf-8 2 __author__ = \'f403\' 3 from urllib.request import urlopen 4 from urllib.error import HTTPError 5 from bs4 import BeautifulSoup 6 import re 7 rootUrl = "http://www.heibanke.com/lesson/crawler_ex00/" 8 9 def getUrl(url=""): 10 try: 11 html = urlopen(rootUrl+url) 12 if html is None: 13 print("html is empty") 14 return None 15 else: 16 try: 17 bs = BeautifulSoup(html.read().decode(\'utf8\'),"lxml") 18 #text = bs.find("h3").get_text() 19 20 text = bs.find(\'h3\').get_text() 21 return text 22 except AttributeError as e: 23 return None 24 except HTTPError as e: 25 return None 26 27 if __name__ ==\'__main__\': 28 txt = getUrl() 29 print(txt) 30 while txt is not None: 31 pattern = re.compile("[0-9]+") 32 num = pattern.search(txt) 33 if num is not None: 34 print(num.group()) 35 txt = getUrl(num.group()) 36 else: 37 txt = None 38 39 print("end")
以上是关于网络爬虫--小实战的主要内容,如果未能解决你的问题,请参考以下文章