hive--构建于hadoop之上让你像写SQL一样编写MapReduce程序
Posted traditional
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive--构建于hadoop之上让你像写SQL一样编写MapReduce程序相关的知识,希望对你有一定的参考价值。
hive介绍
什么是hive?
hive:由Facebook开源用于解决海量结构化日志的数据统计
hive是基于hadoop的一个数据仓库工具,可以将结构化的数据映射为数据库的一张表,并提供类SQL查询功能。本质就是将HQL(hive sql)转化为MapReduce程序
我们使用MapReduce开发会很麻烦,但是程序员很熟悉sql,于是hive就出现了,可以让我们像写sql一样来编写MapReduce程序,会自动将我们写的sql进行转化。但底层使用的肯定还是MapReduce。
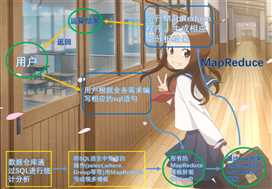
hive处理的数据存储在hdfshive分析数据底层的默认实现是MapReduce执行程序运行在yarn上
hive的优缺点
优点:
操作接口采用类SQL的语法,提供快速开发的能力(简单、容易上手)避免了去写MapReduce,减少开发人员的学习成本hive的执行延迟比较高,因此hive擅长于数据分析、对实时性要求不高的场合还是因为hive的延迟比较高,使得hive的优势在于处理大数据,对于处理小数据没有优势hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点:
hive的HQL表达能力比较有限1.迭代式算法无法表达
2.数据挖掘方面不擅长
hive的效率比较低1.hive虽然自动地生成MapReduce作业,但是通常情况下不够智能化
2.hive调优比较困难,粒度较粗
hive的架构
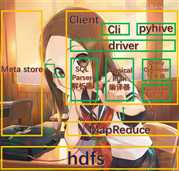
1.用户接口:Client
CLI(hive shell),pyhive(python访问hive),WebUi(浏览器访问hive)
2.元数据:Meta store
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等等
3.hadoop
使用hdfs进行存储,使用MapReduce进行计算
4.驱动器:Driver
1.解析器(sql parser):将SQL字符串转成抽象语法树(ast),这一步一般都用于第三方工具完成,比如antlr,然后对ast进行语法分析,比如表是否存在、字段是否存在、逻辑是否有误等等
2.编译器(physical plan):将ast编译生成逻辑执行计划
3.优化器(query optimizer):对逻辑执行计划进行优化
4.执行器(execution):把逻辑执行计划转化为可以运行的物理计划。
hive和数据库的比较
由于hive采用了类似于SQL的查询语言HQL(hive query language),因此很容易将hive理解为数据库。其实从结构上看,hive除了和数据库拥有类似的查询语言,再无相似之处,下面我们来看看两者的差异
查询语言由于SQL被广泛的运用在数据仓库中,因此,专门针对hive的特性设计类SQL的查询语言HQL,熟悉SQL开发的开发者可以很方便的使用hive进行开发
数据的存储位置hive是建立在hadoop之上的,所有的hive数据是存储在hdfs中的,而数据库则是可以将数据保存在块设备或本地文件系统中的
数据更新由于hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此hive不建议对数据进行改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要进行修改的。
索引hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些key建立索引。hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。而由于MapReduce的引入,hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,即使没有索引,hive仍可以体现出优势。数据库中,通常会针对一个或几个列建立索引,因此对于少量的具有特定条件的数据访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了hive不适合在线数据查询。
执行引擎hive中大多数查询的执行是通过hadoop提供的MapReduce实现的,而数据库通常有自己的执行引擎
执行延迟hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延时较高。另外一个导致hive执行延迟高的因素是MapReduce框架,由于MapReduce本身具有较高的延迟,因此在利用MapReduce执行hive查询时,也会有较高的延迟。相对的,数据的执行延迟较低,当然这个低是有条件的,即数据的规模较小。当数据的规模大到超过了数据库的处理能力的时候,hive的并行计算显然能够体现出其优势。
可扩展性由于hive是建立在hadoop之上的,所以hive的可扩展性和hadoop是一样的(世界上最大的hadoop集群在Yahoo!,2009年的规模在4000台节点左右)。而数据库由于ACID语义的严格限制,扩展性非常有限。目前最先进的并行数据库Oracle在理论上的扩展能力也只有100台左右
数据规模由于hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据。对应的,数据库支持的数据规模较小
hive的安装
由于hive是Apache的顶级项目(Facebook交给了Apache),所以直接官网hive.apache.org下载,首先说明一下,安装hive之前肯定要安装jdk和hadoop,关于这两者的安装我在介绍hadoop的那篇博客中已经说了,这里不再赘述,下面我们就去官网安装hive,hive我们安装2.3.6版本,和我阿里云上2.7.7版本的hadoop是匹配的。
我的hive会安装在/opt/hive目录下,所有的大数据组件都是这样的,java的话就是/opt/java,hadoop就是/opt/hadoop
先来看看hive的目录结构
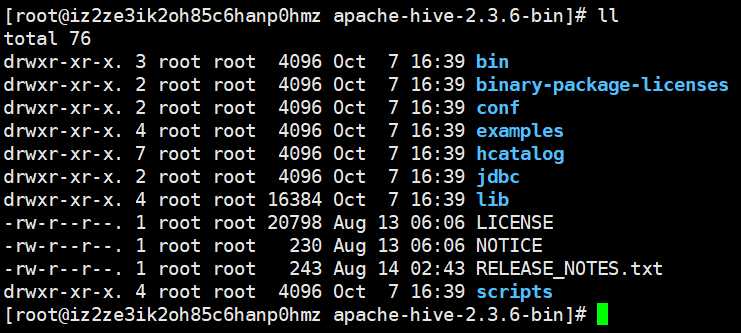
bin目录是用来执行一些命令的,我们注意到没有sbin目录,sbin目录一般是存放启动文件的,就像hadoop的sbin一样,显然对于hive是将两者合并了到bin目录里面了。conf显然是存放配置的,examples,案例,等等。
修改配置文件
hive-env.sh
在hadoop中我们说了,返回以-env.sh结尾,基本上都是配置路径,当然对于hive来说,我们要配置HADOOP_HOME和HIVE_CONF_DIR,因为hive是基于hadoop的嘛。当然conf目录下没有hive-env.sh,只有hive-env.sh.template,老规矩,需要先cp hive-env.sh.template hive-env.sh。然后,因为文件时注释掉的,我们直接在末尾添加即可,HIVE_CONF_DIR就是我们刚才说的conf目录的绝对路径
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export HIVE_CONF_DIR=/opt/hive/apache-hive-2.3.6-bin/conf
另外如果你的hadoop都已经配置了环境变量,那么这些配置也可以不用改,可以自动找到,但是还是建议配一下。
修改完毕,由于我已经配置了环境变量,所以在家目录启动一下hive,直接输入hive即可,如果没有配置环境变量,那么需要进入到bin目录里面
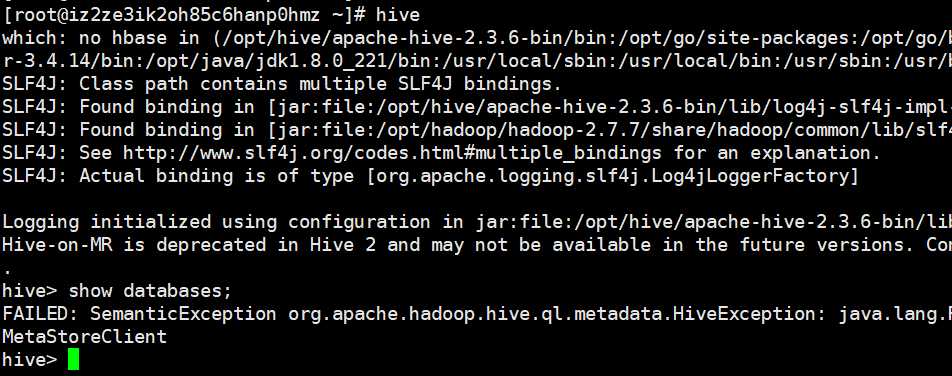
执行成功,但是当我们show?databases;的时候报错了,为啥嘞,显然是没有数据库啊,不过至少目前hive是启动成功了。
下面我们就来安装mysql
1.wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
2.rpm -ivh mysql-community-release-el7-5.noarch.rpm
3.yum install mysql-server(如果失败的话,可以先执行一下yum update)
4.mysqld --initialize
5.systemctl start mysqld
6.输入:mysqladmin --version,如果有类似如下内容说明安装成功
? mysqladmin Ver 8.42 Distrib 5.6.45, for Linux on x86_64
7.设置密码:mysqladmin -u root password 你的密码
8.mysql -u root -p进入数据库
大功告成。
下载驱动配置mysql
安装驱动
我们安装好了mysql,但是java要连接是不是要需要驱动呢?是的,所以我们还需要单独下载驱动,至于驱动的下载地址,随便百度一搜java连接mysql驱动就能找到,这里我们可以使用菜鸟教程提供的https://www.runoob.com/java/java-mysql-connect.html,进去会看到页面所提供的下载路径
下载完毕之后,直接扔到HIVE_HOME的lib目录里面去就行了
配置mysql
hive默认使用的derby,我们要配置成mysql。显然要修改配置文件,这里我们修改conf目录下的hive-site.xml,但是没有这个文件,所以我们要touch?hive-site.xml,然后打开在里面输入如下内容:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定mysql -->
<property>
<name>javax.jdo.option.ConnectionURL</name>mysql
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value>
</property>
<!-- 指定mysql的驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>mysql驱动程序
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 指定mysql的用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 指定mysql的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>密码
<value>密码</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>重新启动hive
启动成功之后,可以看到metastore这个数据库已经自动为我们创建了
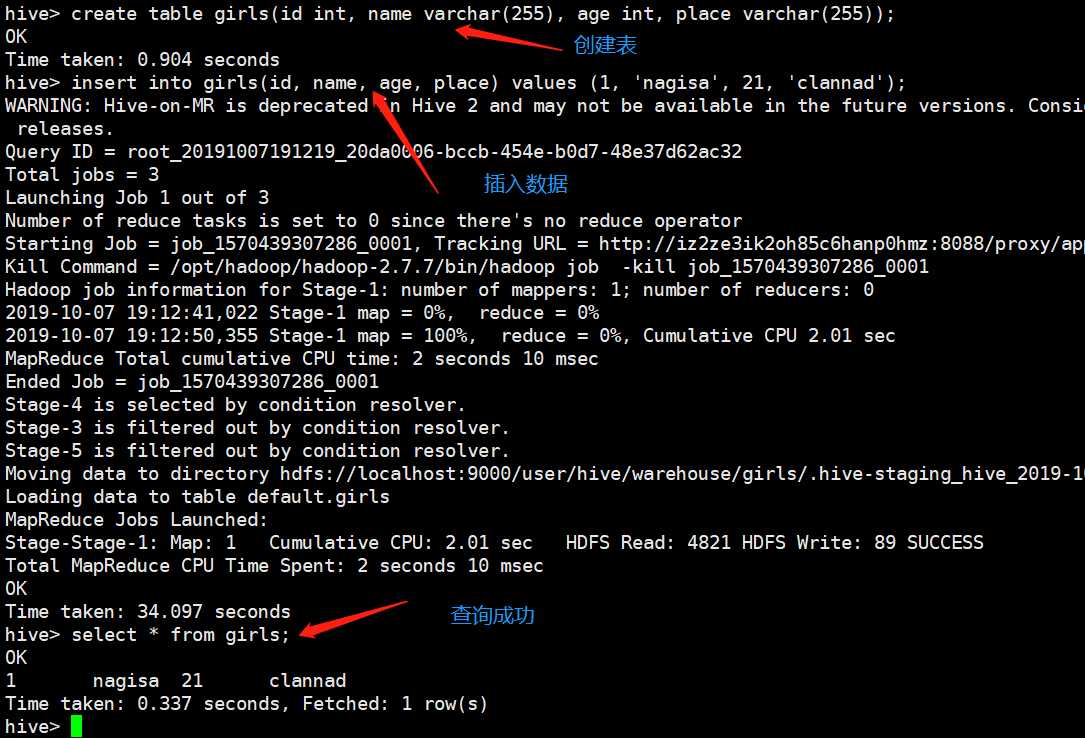
随便测试一下

我们虽然查询到了数据,但是不要忘记,这个数据是存在hdfs上面的,mysql里面只是存储了元数据的信息,那么我们就来看看这个mysql里面到底存了些什么东西。数据显然存在metastore里面,但是是哪一张表呢?表有很多,但是存的那张表叫做TBLS
我们通过webUI的方式查看一下
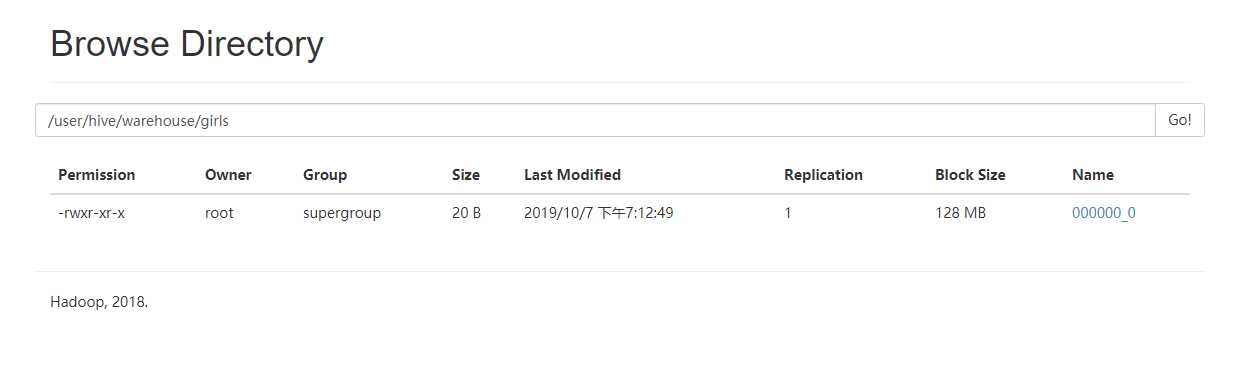
我们把那个000000_0的文件下载下来看一看
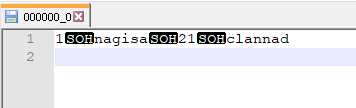
这不就是我们之前存的内容嘛。
python连接hive
python若想连接hive,需要下载第三方包。
pip install sasl
? 这个如果直接pip安装的话其实不出意外会报错,因为有C或者C++扩展,我们需要去https://www.lfd.uci.edu/~gohlke/pythonlibs/这个网站去下载对应python版本的sasl,然后安装就可以了。至于下面三个,直接pip 安装即可
pip install thrift
pip install thrift_sasl
pip install pyhive
from sqlalchemy import create_engine
engine = create_engine("hive://47.94.174.89:10000/default")
# 就把hive当成一个数据库使用就行,也是支持sqlalchemy的,当然底层使用pyhive
import pandas as pd
df = pd.read_sql("select * from girls", engine)golang连接hive
golang若想连接hive,同样需要下载第三方包。go?get?github.com/lwldcr/gohive?
package main
import (
"fmt"
"github.com/lwldcr/gohive"
"os"
)
func main()
//创建连接
client, err := gohive.NewTSaslTransport("47.94.174.89", 10000, "", "", gohive.DefaultOptions)
if err != nil
fmt.Println("连接出错,错误信息:", err)
os.Exit(1)
//打开socket,启动sasl客户端,发送初始信息,打开session会话
//这一步看似只返回了一个error,但是必须要有,否则无法查询
if err := client.Open(); err != nil
fmt.Println("open failed:", err)
os.Exit(1)
defer client.Close()
// client.Query执行查询
rows, err := client.Query("select * from girls")
if err != nil
fmt.Println("查询出错,错误信息:", err)
os.Exit(1)
defer rows.Close()
//打印所有列
fmt.Println(rows.Columns()) // [girls.id girls.name girls.age girls.place]
type Girl struct
id int
name string
age int
place string
girls := make([]Girl, 0)
//迭代
for rows.Next()
girl := Girl
//Scan
if err := rows.Scan(&girl.id, &girl.name, &girl.age, &girl.place); err != nil
fmt.Println("获取数据出错,错误信息:", err)
os.Exit(1)
girls = append(girls, girl)
fmt.Println(girls) // [1 nagisa 21 clannad 2 mashiro 16 sakurasou 3 yuuko 16 ef]
以上是关于hive--构建于hadoop之上让你像写SQL一样编写MapReduce程序的主要内容,如果未能解决你的问题,请参考以下文章