CURL抓取页面
Posted nineleopard
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CURL抓取页面相关的知识,希望对你有一定的参考价值。
cURL的基本原理
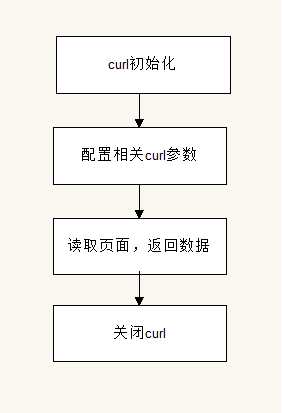
curl是利用URL语法在命令行方式下工作的开源文件传输工具,他能够从互联网上获得各种各样的网络资源。简单来说,curl就是抓取页面的升级版。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<?php //1.初始化,创建一个新cURL资源 $ch = curl_init();//2.设置URL和相应的选项 curl_setopt($ch, CURLOPT_URL, "http://www.baidu.com/"); curl_setopt($ch, CURLOPT_HEADER, 0);//3.抓取URL并把它传递给浏览器 curl_exec($ch);//4.关闭cURL资源,并且释放系统资源 curl_close($ch);?> |
cURL爬取页面之爬取网页信息并替换
|
1
2
3
4
5
6
7
8
|
<?php$curlobj = curl_init(); // 初始化curl_setopt($curlobj, CURLOPT_URL, "http://www.baidu.com"); // 设置访问网页的URLcurl_setopt($curlobj, CURLOPT_RETURNTRANSFER, true); // 执行之后不直接打印出来$output=curl_exec($curlobj); // 执行curl_close($curlobj); // 关闭cURLecho str_replace("百度","php",$output);?> |
cURL爬取页面之获取天气
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<?php$data = ‘theCityName=北京‘;$curlobj = curl_init();curl_setopt($curlobj, CURLOPT_URL, "http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getWeatherbyCityName");curl_setopt($curlobj, CURLOPT_USERAGENT, "user-agent:Mozilla/5.0 (Windows NT 5.1; rv:24.0) Gecko/20100101 Firefox/24.0");curl_setopt($curlobj, CURLOPT_HEADER, 0); //启用时会将头文件的信息作为数据流输出。这里不启用curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1); //如果成功只将结果返回,不自动输出任何内容。如果失败返回FALSEcurl_setopt($curlobj, CURLOPT_POST, 1); //如果你想PHP去做一个正规的HTTP POST,设置这个选项为一个非零值。这个POST是普通的 application/x-www-from-urlencoded 类型,多数被HTML表单使用。curl_setopt($curlobj, CURLOPT_POSTFIELDS, $data); //需要POST的数据curl_setopt($curlobj, CURLOPT_HTTPHEADER, array("application/x-www-form-urlencoded; charset=utf-8", "Content-length: ".strlen($data)));$rtn = curl_exec($curlobj);if(!curl_errno($curlobj)) // $info = curl_getinfo($curlobj); // print_r($info); echo $rtn; else echo ‘Curl error: ‘ . curl_error($curlobj);curl_close($curlobj);?> |
原贴地址:https://www.cnblogs.com/laomao666/p/10952235.html
以上是关于CURL抓取页面的主要内容,如果未能解决你的问题,请参考以下文章