redis源码分析--rdb持久化
Posted yang-zd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis源码分析--rdb持久化相关的知识,希望对你有一定的参考价值。
Redis rdb持久化
Redis支持两种持久化方式:rdb与aof。rdb将一个节点上的内存数据序列化后存储到磁盘中,序列化的数据以尽可能节约空间的方式存储,并非完全的ascii表示。它的优点在于节约空间,恢复速度快,缺点在于每一次操作都需要对整个内存数据进行序列化,并且持久化过程中的修改被丢失。而aof将数据以操作命令的方式进行存储,从aof恢复数据即从aof文件读入命令再执行命令。它的优点是可以记录持久化过程中的产生的命令,而缺点在于完全以ascii编码,使用空间更多,且恢复速度更慢。这篇文件章主要对rdb的持久化方式进行大致介绍。
Redis中有多种数据类型,如string、set、zset、hash、list等,并且具有多个db(一个db即是一个字典,存储了string、list、set等类型的数据),为了完成不同类型数据的序列化,Redis设计了相应的持久化格式。
1. 序列化string
序列化string时,首先会存储string的长度,然后存储string的真实值。为了节约空间,对于不同长度的string,redis使用尽可能少的空间来存储它的长度,因此设计了如下的字符串长度存储格式:
- len < 1<<6,使用1个字节编码长度,该字节的高2bits为00,低6bits代表长度
- 1<<6 <= len < 1<<14,使用2个字节编码长度,第1个字节的高两bits为01,后续14bits代表长度
- 1<<14 <= len <= UINT32_MAX,使用5个字节编码长度,第1个字节为0x80,后续4字节代表长度
- UINT32_MAX < len,使用9个字节编码长度,第1个字节为0x81,后续8字节代表长度
Redis中相应的定义如下:
/* Defines related to the dump file format. To store 32 bits lengths for short * keys requires a lot of space, so we check the most significant 2 bits of * the first byte to interpreter the length: * * 00|XXXXXX => if the two MSB are 00 the len is the 6 bits of this byte * 01|XXXXXX XXXXXXXX => 01, the len is 14 byes, 6 bits + 8 bits of next byte * 10|000000 [32 bit integer] => A full 32 bit len in net byte order will follow * 10|000001 [64 bit integer] => A full 64 bit len in net byte order will follow * 11|OBKIND this means: specially encoded object will follow. The six bits * number specify the kind of object that follows. * See the RDB_ENC_* defines. * * Lengths up to 63 are stored using a single byte, most DB keys, and may * values, will fit inside. */
举例,对string“hello world”编码结果如下:
0xC “hello, world”
0xC以1个字节表示字符串长度为12字节,后续12字节即为字符串的真实值。由于是非前缀码,因此根据第1个字节的值完全可以进行区分是哪种格式,反序列化时首先读1个字节的内容,然后根据该字节的值即可选择正确的操作。
redis中rdb.c源文件中的rdbSaveLen函数完成长度的编码,而rdbLoadLen完成长度值的解码。
2. 序列化int
当需要序列化的值为整形值时,整形值会以二进制的形式直接进行序列化,而不是转换成ascii码的字符串形式进行序列化,从而进一步节约空间。此外,根据整形值的大小,redis同样以尽可能少的空间来存储该值。与字符串类似,首先有一个字节的高2bits设置为11代表后续的值是一个整形值,同时以低6bits的值区分使用的字节数。
- (value >= -(1<<7) && value <= (1<<7)-1),低6bit值为0,后续1个字节存储整形值。
- (value >= -(1<<15) && value <= (1<<15)-1),低6btis值为1,后续2个字节存储整形值。
- (value >= -((long long)1<<31) && value <= ((long long)1<<31)-1),低6bits值为2,后续4个字节存储整形值。
整体形式如下:
11000000[8 bit integer] 11000001[16 bit integer] 11000002[32 bit integer]
举例,序列化整形值0x300的结果如下:
0xC1 0x0300
0xC1表示后续是一个以int16形式存储的整形值,0x0300即为该整形值。由于第1个字节的高2bits为11,与string类型表示长度的格式不相同,所此可以区分是string还是int型。
此外,若第1个字节的高2bits为11,低6bits为3(RDB_ENC_LZF),那么后续的数据为压缩数据,该字节后跟着两个长度值,分别表示压缩后的数据长度与压缩前的数据长度,再后面才是真正的数据。
3. RDB_TYPE_*与RDB_OPCODE_*
Redis是一个key-value缓存系统,所有的值都以key-value的形式存储在db字典中。但是redis中value的类型并不仅限于string,它还可以是结构体类型,如set、list、hash等。为了序列化这些类型,redis中首先会以一个字节存储数据类型,然后如果是复合类型,会存储该类型的成员数目,然后遍历成员值并以基本的int或者string类型进行存储。
Redis中定义了如下的类型值:
/* Map object types to RDB object types. Macros starting with OBJ_ are for * memory storage and may change. Instead RDB types must be fixed because * we store them on disk. */ #define RDB_TYPE_STRING 0 #define RDB_TYPE_LIST 1 #define RDB_TYPE_SET 2 #define RDB_TYPE_ZSET 3 #define RDB_TYPE_HASH 4 #define RDB_TYPE_ZSET_2 5 /* ZSET version 2 with doubles stored in binary. */ #define RDB_TYPE_MODULE 6 #define RDB_TYPE_MODULE_2 7 /* Module value with annotations for parsing without the generating module being loaded. */ /* NOTE: WHEN ADDING NEW RDB TYPE, UPDATE rdbIsObjectType() BELOW */ /* Object types for encoded objects. */ #define RDB_TYPE_HASH_ZIPMAP 9 #define RDB_TYPE_LIST_ZIPLIST 10 #define RDB_TYPE_SET_INTSET 11 #define RDB_TYPE_ZSET_ZIPLIST 12 #define RDB_TYPE_HASH_ZIPLIST 13 #define RDB_TYPE_LIST_QUICKLIST 14 #define RDB_TYPE_STREAM_LISTPACKS 15 /* NOTE: WHEN ADDING NEW RDB TYPE, UPDATE rdbIsObjectType() BELOW */
这些类型值代表了被序列化的value的类型,如list、set等,此外还代表了value的具体实现方式,如set可以使用hash表实现,相应类型值为RDB_TYPE_SET,也可以使用一个有序的整形数组实现,对应类型值为RDB_TYPE_SET_INTSET。反序列化时,首先读取1个字节的值判断后续数据的类型,然后进行相应的类型重建。
举例,一个string类型的key-value对 “key1” “hello, world”的序列化结果为:
RDB_TYPE_STRING 0x4 “key1” 0xC “hello, world”
首先1个字节的类型值RDB_TYPE_STRING,然后一个字节的长度值0x4,即后面有4个字节的关键字字符串,然后一个字节的长度值0xC,即后面有12个字节的字符串值。
反序列化时:
- 首先读取1个字节得RDB_TYPE_STRING,得到后续为一个string对象
- 然后读取长度值0x4,并读取相应的4个字节得到关键字,
- 最后再读取长度0xC,并读取相应的12字节值得到value值。
举例,一个list类型的key-value对:”key2” 2 3 4 0x300的序列化结果为:
RDB_TYPE_LIST 0x4 “key2” 0x4 0xc0 0x2 0xc0 0x3 0xc0 0x4 0xC1 0x0300
首先是1个字节的类型值RDB_TYPE_LIST,然后长度值为0x4,表示有4个字节的关键字字符串,然后是0x4表示该list有4个成员,然后4个成员依次以整形的格式序列化。
反序列化时:
- 首先读取1个字节得到RDB_TYPE_LIST,得到后续为一个list对象,
- 读取关键字的长度为0x4,读取4字节得到”key2”
- 读取长度0x4,得到list成员数目为4
- 读取长度,然后读取整形值,循环4次,完成list对象的重建。
除了RDB_TYPE*与redis中存储的数据类型对应,还有一类RDB_OPCODE*表示一些其它的数据,如:RDB_OPCODE_EXPIRETIME表示后面的数据是该对象的超时时间;RDB_OPCODE_SELECTDB表示接下来的数据是一个db索引,直到遇到下一个RDB_OPCODE_SELECTDB之前,所有反序列化的数据都应该存储在该索引的db字典中。Redis中定义了如下类型的RDB_OPCODE*值:
/* Special RDB opcodes (saved/loaded with rdbSaveType/rdbLoadType). */ #define RDB_OPCODE_MODULE_AUX 247 /* Module auxiliary data. */ #define RDB_OPCODE_IDLE 248 /* LRU idle time. */ #define RDB_OPCODE_FREQ 249 /* LFU frequency. */ #define RDB_OPCODE_AUX 250 /* RDB aux field. */ #define RDB_OPCODE_RESIZEDB 251 /* Hash table resize hint. */ #define RDB_OPCODE_EXPIRETIME_MS 252 /* Expire time in milliseconds. */ #define RDB_OPCODE_EXPIRETIME 253 /* Old expire time in seconds. */ #define RDB_OPCODE_SELECTDB 254 /* DB number of the following keys. */ #define RDB_OPCODE_EOF 255 /* End of the RDB file. */
这些特殊类型后续值的长度通常是固定的,如RDB_OPCODE_EXPIRETIME以32bit表示超时时间,单位为s;RDB_OPCODE_EXPIRETIME_MS后面是64bit表示的超时时间,单位为ms;RDB_OPCODE_SELECTDB后续是使用的db索引,以len的编码方式进行存储,而RDB_OPCODE_AUX表示一些key-value对,而这些key, value都是string与int等基本类型。
除了rdb文件开头的固定字节的magic码,所有rdb序列化的数据都有一个前置的RDB_TYPE_*值或者RDB_OPCODE_*值,它表示了后续数据的存储方式,从而反序列化时采取正确的操作。
4. RDB序列化流程
1. 序列化前置信息,如magic识别码,版本号,时间戳
2.遍历db,序列化每一个db
2.1 序列化RDB_OPCODE_SELETCTDB
2.2 序列化RDB_OPCODE_RESIZEDB,存储该db的大小
2.3 序列化db中的每一个key-value对
2.3.1 序列化超时时间RDB_OPCODE_EXPIRETIME
2.3.2 序列化lru值,RDB_OPCODE_IDLE
2.3.3 序列化LFU值,RDB_OPCODE_FREQ
2.3.4 序列化值类型
2.3.5 序列化key(string)
2.3.6 序列化value
在前一篇文件中介绍过redis的rio抽象层,而这些序列化操作正是以rio作为接口,以rio为目的地,既可以将序列化内容输出到文件,也可以将序列化内容输出到多个sockets中。普通的持久化操作使用文件作为输出对象,而在master-slave中的数据同步可能会使用到sockets作为输出对象,通过rio的抽象,将序列化与底层io进行解藕。
redis中的序列化函数调用栈如下:
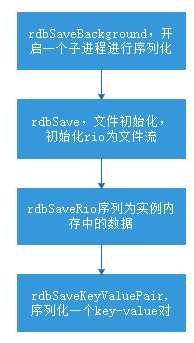
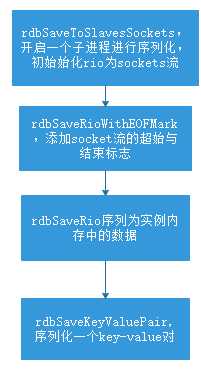
左图是输出对象为文件的序列化调用关系,右图是输出对象为sockets的序列化调用关系。
5. RDB反序列化流程
1.读取9字节magic标志,并验证
循环进行2-3步
2. 读取1字节RDB_TYPE_*或者RDB_OPCODE_*标志
3. 根据RDB_OPCODE_*或者RDB_TYPE_*的值做相应的处理
上述第3步中,如果需要读取string或者int这种基本类型,处理过程为:
- 调用rdbLoadLen读取长度
- 根据rdbLoadLen返回值读取string或者整形值
如果对应的类型为复合类型,如list、set等,处理过程为:
- 调用rdbLoadLen读取复合类型成员数目
- 循环读取成员值,直到指定数目的值被读出。读取成员的操作即读取string或者int基本类型。
反序列化的输入为文件,即使序列化的输出目的地为sockets,接收端也会先将数据存储到一个文件中,然后再从文件反序列化。反序列化的调用栈为
- rdbLoad,初始化rio为文件流
- rdbLoadRio以rio为输入,从文件中读取数据并完成反序列化。
6. 后台进程
由于redis是单线程模式,因此它选择将持久化操作放在子进程中进行,否则持久化过程中将停止响应请求。
根据fork函数的特性,子进程创建后与父进程拥有相同的内存内容,因此fork函数调用后子进程即得到了此时db中的完整内容。并且由于copy-on-write特性,并不会发生大量的内存copy,仅在write操作发生时,相应的内存页才进行一个copy生成副本,即该操作也不会特别耗时。
但相应的,父进程继续接受客户端的命令,修改的内容并不会反应到子进程的内存中,因此rdb持久化过程中出现的修改将会丢失。
以上是关于redis源码分析--rdb持久化的主要内容,如果未能解决你的问题,请参考以下文章