内存数据库技术选型
Posted zhanqing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内存数据库技术选型相关的知识,希望对你有一定的参考价值。
一、内存数据库的应用场景
- 数据缓存:将经常使用的数据存放在内存中,全局共享,减少和数据之间的交互频率,提升数据访问速度,主要用于应用程序的全局共享缓存。
- 内存计算:支持通过标准的SQL或Linq的方式实现内存数据的聚合、计算和查询、充分发挥、利用应用服务器的资源
二、业界有哪几类的主流内存数据库
1.关系型内存数据库
- 传统关系型数据库场景下,应用层的数据缓存
- 将传统的关系型数据库表搬到内存中,内存数据和数据库数据之间进行结构映射
- 支持通过SQL语句的方式实现对内存数据的访问,更加贴合业务实现
- 将经常使用的数据存放在内存中,减少和数据库之间的交互频率,提升数据访问数据
- 数据实时/定时同步
- 有限的事物保证
2.键值对内存数据库
- 键值对存储结构
- 按Key进行数据读取
- Value支持各种数据类型
- 类似Redis
3.传统数据库的内存数据库引擎
- SQLServer2016 In Memory OLTP
- MySQL Memory Engine
- 在数据库层面提供了内存数据库引擎机制,最大程度的减少磁盘IO
- 数据类型有一定的限制
- 事物支持
- 数据持久化保证
还有Oracle 的Timesten、SAP的HANA等,这些商业中间件不在我们研究的范围之内。
那么,传统数据库和内存数据库之间是什么关系? 相互补充、珠联璧合的关系
内存数据库不会独立于传统数据库而单独存在,因为内存是易失的。现在具有持久化功能的内存库,如redis、couchbase等,其持久化功能相较传统数据库还较溥弱,持久化性能也不如传统数据库。因此,内存数据库在一段时期内,将是传统数据库的一种强有力的补充。
如果说传统数据库是一支军队,那么内存数据库就是为执行某种特殊任务的特种部队,不要求功能多,但一定要快速、迅猛。
我们继续一一对比分析一下上面所述的几类内存数据库。
三. 业界主流的内存数据库
1. SQL Server 2016 In-Memory OLTP
SQL Server 2016的In-Memory OLTP,通俗地讲,是内存数据库,使用内存优化表(Memory-Optimized Table,简称MOT)来实现,MOT驻留在内存中,使用 Hekaton 内存数据库引擎访问。在查询MOT时,只从内存中读取数据行,不会产生Disk IO消耗;在更新MOT时,数据的更新直接写入到内存中。内存优化表能够在Disk上维护一个数据副本,该副本只用于持久化数据,不用于数据读写操作。
在内存数据库中,不是所有的数据都需要存储在内存中,有些数据仍然能够存储在Disk上,硬盘表(Disk-Based Table,简称DBT)是传统的表存储结构,每个Page是8KB,在查询和更新DBT时,产生Disk IO操作,将数据从Disk读取到内存,或者将数据更新异步写入到Disk中。
内存数据库将原本存储在Disk上的数据,存储在内存中,利用内存的高速访问优势实现数据的快速查询和更新,但是,内存数据库,不仅仅是存储空间的变化,Hekaton 内存数据库访问引擎实现本地编译模块(Natively compiled),交叉事务(Cross-Container Transaction)和查询互操作(Query Interop):
本地编译模块:如果代码模块只访问MOT,那么可以将该模块定义为本地编译模块,SQL Server直接将TSQL脚本编译成机器代码;SQL Server 2016支持本地编译的模式有:存储过程(SP),触发器(Trigger),标量值函数(Scalar Function)或内嵌多语句函数(Inline Multi-Statement Function)。相比于解释性(Interpreted)TSQL 模块,机器代码直接使用内存地址,性能更高。
交叉事务:在解释性TSQL模块中,一个事务既能访问硬盘表,也能访问内存优化表;实际上,SQL Server创建了两个事务,一个事务用于访问硬盘表,一个事务用于访问内存优化表,在DMV中,分别使用transaction_id 和 xtp_transaction_id 来标识。
查询互操作:解释性TSQL脚本能够访问内存优化表和硬盘表,本地编译模块只能访问内存优化表。
内存数据被整合到SQL Server关系引擎中,使用内存数据库时,客户端应用程序甚至感受不到任何变化,DAL接口也不需要做任何修改。由于Query Interop的存在,任何解释性TSQL脚本都能透明地访问MOT,只是性能没有本地编译TSQL脚本性能高。在使用分布式事务访问MOT时,必须设置合适的事务隔离级别,推荐使用Read Committed,如果发生MSSQLSERVER_41333 错误,说明产生交叉事务隔离错误(CROSS_CONTAINER_ISOLATION_FAILURE),原因是当前事务的隔离级别太高。
2. Apache Ignite
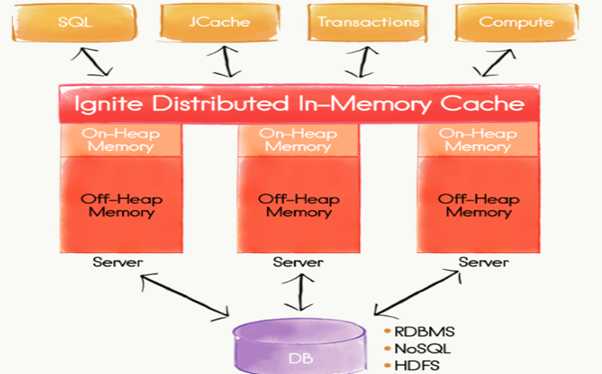
Apache Ignite是一个内存数据组织是高性能的、集成化的以及分布式的内存平台,他可以实时地在大数据集中执行事务和计算,和传统的基于磁盘或者闪存的技术相比,性能有数量级的提升。
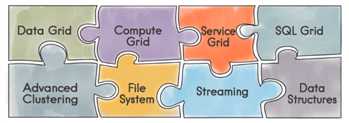
可以将Ignite视为一个独立的、易于集成的内存组件的集合,目的是改进应用程序的性能和可扩展性。
Data Grid:Ignite内存数据网格是一个内存内的键值存储,他可以在分布式集群的内存内缓存数据。 它通过强语义的数据位置和关系数据路由,来降低冗余数据的噪声,使其可以节点数的线性增长,直至几百个节点。 Ignite数据网格速度足够快,经过官方不断的测试,目前,他是分布式集群中支持事务性或原子性数据的最快的实现之一。
SQL Grid:内存SQL网格为Apache Ignite提供了分布式内存数据库的功能,它水平可扩展,容错并且兼容SQL的ANSI-99标准。 SQL网格支持完整的DML命令,包括SELECT, UPDATE, INSERT, MERGE以及DELETE。 同时支持分布式SQL Join关联
RDBMS集成: Ignite支持与各种持久化存储的集成,它可以连接数据库,导入模式,配置索引类型,以及自动生成所有必要的XML OR映射配置和Java领域模型POJO,这些都可以轻易地下载和复制进自己的工程。 Ignite可以与任何支持JDBC驱动的关系数据库集成,包括Oracle、PostgreSQL、MS SQL Server和mysql。
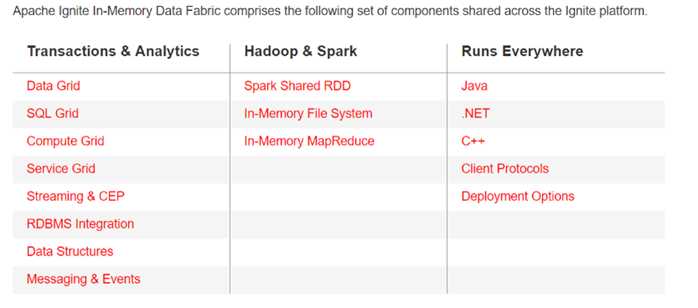
汇总一下,Apache Ignite的功能特性:
- 分布式键值存储:Ignite数据网格是一个内存内的键值存储,分布式的分区化的哈希,集群中每个节点都持有所有数据的一部分,这意味着集群内节点越多,就可以缓存的数据越多。 Ignite通过可插拔的哈选算法来决定数据的位置,每个客户端都可以通过插入一个自定义的哈希函数来决定一个键属于那个节点,并不需要任何特殊的映射服务或者命名节点。
- 内存优化:Ignite在内存中支持2种模式的数据缓存,堆内和堆外。当缓存数据占用很大的堆,超过了Java主堆空间时,堆外存储可以克服JVM垃圾回收(gc)导致的长时间暂停,但数据仍然在内存内。
- SQL查询:Ignite支持使用标准的SQL语法(ANSI 99)来查询缓存,可以使用任何的SQL函数,包括聚合和分组。
- 分布式关联:Ignite支持分布式的SQL关联和跨缓存的关联。
- ACID事务:Ignite提供了一个完全符合ACID的分布式事务来保证一致性。 支持乐观和悲观的并发模型以及读提交、可复制读和序列化的隔离级别。 Ignite的事务使用了二阶段提交协议,适当地也进行了很多一阶段提交的优化。
- 同写和同读:通写模式允许更新数据库中的数据,通读模式允许从数据库中读取数据。
- 数据库异步更新:Ignite提供了一个选项,通过后写缓存来异步地执行数据库更新
- 自动持久化:自动化地连接底层数据库并且生成XML的对象关系映射配置和Java领域模型POJO
- 数据库支持:Ignite可以自动地与外部数据库集成,包括RDBMS、NoSQL和HDFS。
从以上的Apache Ignite的特性看,它就是一个关系型的内存数据库。貌似在这个领域,Apache Ignite做的非常好。这一点非常符合我们技术选型的需要!一句话:
可以像操作数据库一样,操作内存缓存!
3. FastDB
FastDb是高效的关系型内存数据库系统,具备实时能力及便利的C++接口。FastDB针对应用程序通过控制读访问模式作了优化。通过降低数据传输的开销和非常有效的锁机制提供了高速的查询。对每一个使用数据库的应用数据库文件被影射到虚拟内存空间中。因此查询在应用的上下文中执行而不需要切换上下文以及数据传输。Fastdb中并发访问数据库的同步机制通过原子指令实现,几乎不增加查询的开销。
FastDB的特点:
- FastDB不支持client-server架构因而所有使用FastDB的应用程序必须运行在同一主机上;
- fastdb假定整个数据库存在于RAM中,并且依据这个假定优化了查询算法和接口。
- fastdb没有数据库缓冲管理开销,不需要在数据库文件和缓冲池之间传输数据。
- 整个fastdb的搜索算法和结构是建立在假定所有的数据都存在于内存中的,因此数据换出的效率不会很高。
- Fastdb支持事务、在线备份以及系统崩溃后的自动恢复。
- fastdb是一个面向应用的数据库,数据库表通过应用程序的类信息来构造。
缺点:
- FastDB在接口上仅支持C++,GitHub有个人版的C# SDK https://github.com/gavioto/fastdb/tree/master/CSharp
- 有限的SQL语法支持
- 个人版开源系统,没有商业支持,未经生产环境验证
4. Redis&Memcached
Redis和Memcached,从本质上看,都属于Key-Value内存数据库,Redis无论从稳定性、性能和功能上都要强于MemCached。
NoSQL结构设计,不支持关系型数据结构。
Redis我们已经大规模应用了,本次技术选型的重要在于关系型内存数据库上,所以,Redis和MemCached不作深入研究和讨论。
初步的选型总结:
从需求和功能满足度上看:Apache Ignite 最满足我们的需求,从Apache Ignite的特性看,它就是一个关系型的内存数据库。貌似在这个领域,Apache Ignite做的非常好。这一点非常符合我们技术选型的需要!一句话:
可以像操作数据库一样,操作内存缓存!
先放出两张图给大家:
以上是关于内存数据库技术选型的主要内容,如果未能解决你的问题,请参考以下文章