分析一套源代码的代码规范和风格并讨论如何改进优化代码
Posted fmyao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析一套源代码的代码规范和风格并讨论如何改进优化代码相关的知识,希望对你有一定的参考价值。
我的工程实践选题是《视频序列中人员检测与身份推断的系统设计》,毋庸置疑,在这个系统开发的过程中,大头是人脸识别。因此我在github上找到了一套名为face_recognition的源代码,希望学习它的具体算法实现。
这套代码主要实现的是人物脸部定位、人物脸部识别和人脸中关键部位的识别几个功能,这么说可能会有些抽象,好在项目的说明文档中的两张图还是解释得很清晰的,这里分享给大家:
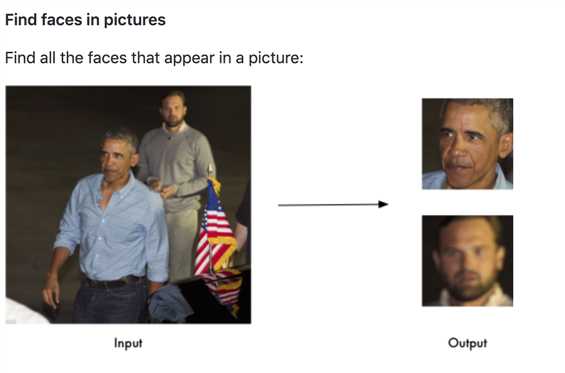

既然是想要学习,自然不是把这套代码克隆到的本地就结束了,读代码是克隆之后的第一步。众所周知,代码规范对于软件的开发而言太重要了,不管是团队之间的合作、团队成员离职后工作交接的速度,都与代码规范息息相关,在Martin的《Clean Code》一书中写到,一个程序员读与写的时间比超过10:1,足可以看出,一套代码的优雅可读性有多么的重要。
一、分析其在源代码目录结构、文件名/类名/函数名/变量名等命名、接口定义规范和单元测试组织形式等方面的做法和特点
那么下面,我们就来分析一下这个face_recognition系统的代码规范吧,今天,我们都是处女座的程序员~~
首先查看项目目录:
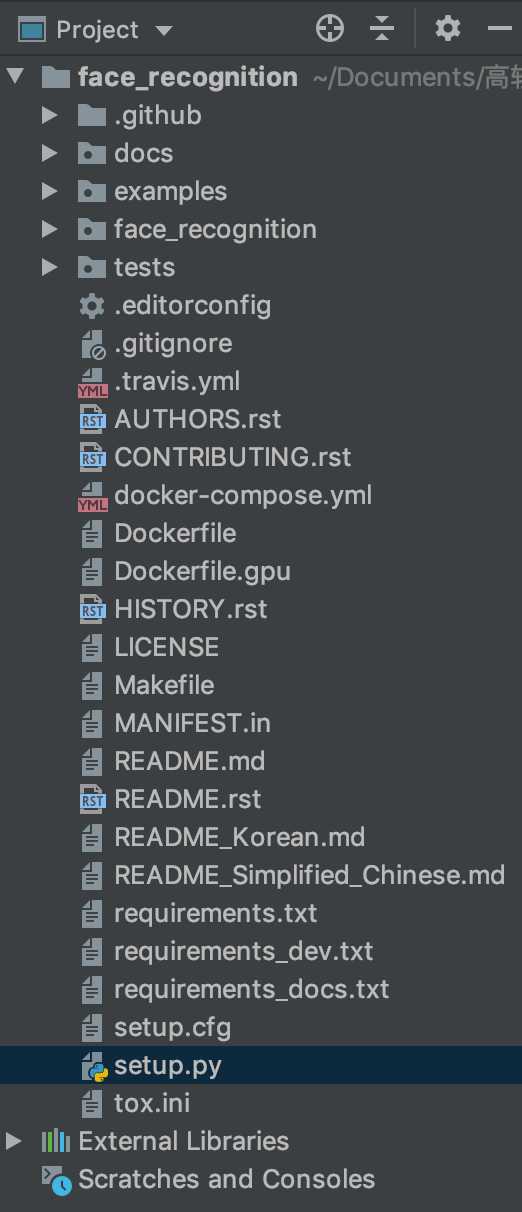
可以看到开发者主要将代码分为了几个模块:
1、docs 存放相关的说明文件
2、examples 存放各个子算法的实现方式和其对应的测试图片
3、face_recognition 存放主要的人脸识别模块的代码
4、test 存放的是测试测试代码和测试图片数据
5、跟目录下的其他文件基本是相关的配置文件
下面来分析文件和接口和变量,它们的命名没有采用传统的驼峰式命名,而是用下划线作为了一个分割,下面截取一个文件内部的代码
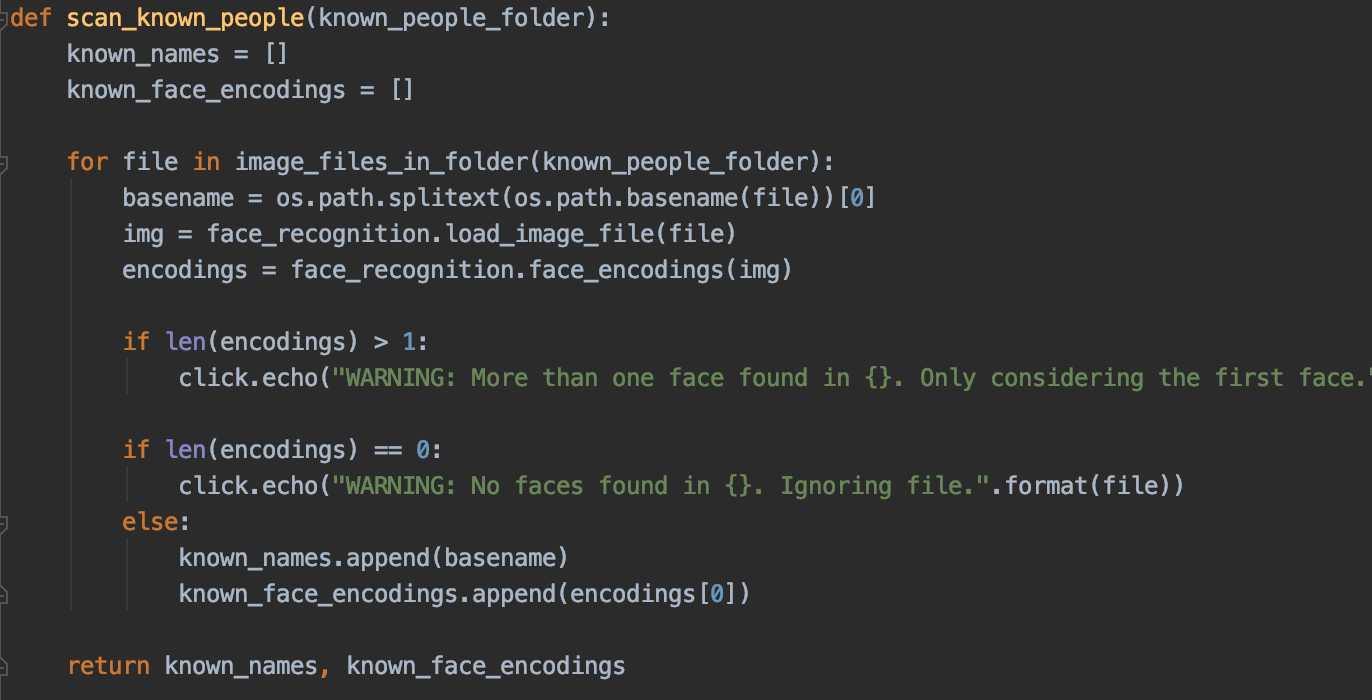
可以看到,变量命名清晰可懂,但是通篇基本上是没有书写足够的注释的。
至于说单元测试:
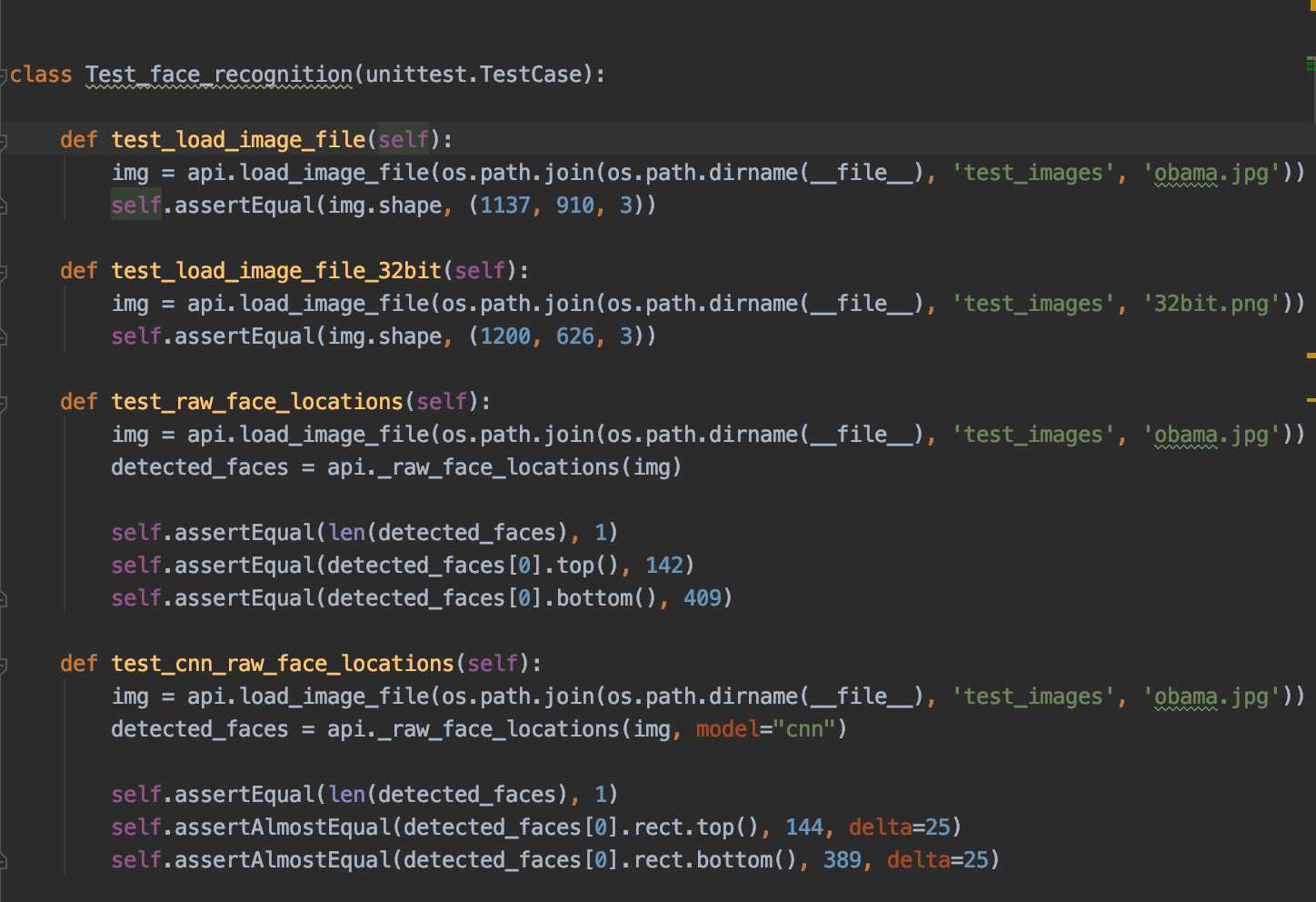
可以看到测试代码中更多的是对整个人脸识别算法的测试,和我们所了解的单元测试从性质上说还是有很大的不同,这个项目在单元测试这块是缺失的。
二、列举哪些做法符合代码规范和风格一般要求
首先从文件目录来看,把功能有区分度的代码打包分块,在命名文件名、接口和变量的时候力求做到简单明晰,命名名副其实,不说废话,都是符合代码规范的做法。
代码格式统一,一眼看上去也让人觉得很舒服,也是值得称赞的一点。
三、列举哪些做法有悖于“代码的简洁、清晰、无歧义”的基本原则,及如何进一步优化改进
其实当我们看到文件目录的时候,就会发现这个项目其实存放还是比较混乱的,子算法的测试代码和程序单独放在一起,主算法的测试代码又在根目录下建了文件夹,根目录下有一些文档和docs里面的文档命名几乎一致,让人分不出区别来,等等问题都需要解决。
关于缺少注释的问题,如果代码清晰可懂,确实是不需要过多的注释,但是对于todo注释和阐述注释,这一块还是有缺失的。
四、总结同类编程语言或项目在代码规范和风格的一般要求。
1、首先最基础的肯定是格式规范了,符号前后的空格、缩进都需要统一起来,垂直对齐与水平对齐可是一个处女座的基本素养
2、函数尽可能的短小,一个函数实现一个功能,只做一件事
3、函数尽量避免三个以上的参数,这样不仅在函数的调用时候让人为难,还不利于测试用例的编写
4、关于注释在第三点时就讲到了,代码清晰可懂,是不需要多余的注释的,好的注释是你想办法不去写的注释。所以,不要写废话的注释,不要喃喃自语,对于暂时用不到的代码,直接删掉就好,不要用注释把它注掉。这个会导致的问题是,有些人注释之后就忘记去做一个删除,而你的团队成员并不能确定这段代码是不是你所需要的而不敢删除,如果代码一旦被废弃,可能会一直保留下来。要知道,现在的git版本管理已经非常的全面了,我们丝毫不用担心删除了代码就会丢掉它,所以放心大胆地把你摇摆不定的代码删掉吧。
5、在遇到错误的时候更多地进行异常的抛出而非使用错误码
6、单元测试要具有可读性,一个测试需要一个断言等等
我想如果说代码风格仅仅是代码的格式,那我们对它的定义也太狭隘了一些,它涉及到的内容真的很多,更多的时候,我认为一个人的代码风格也是他代码功底的重要的组成部分。
以上是关于分析一套源代码的代码规范和风格并讨论如何改进优化代码的主要内容,如果未能解决你的问题,请参考以下文章