Update:sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
Posted mediocreworld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Update:sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作相关的知识,希望对你有一定的参考价值。
8. Dataset (DataFrame) 的基础操作
这一章节主要目的是介绍 Dataset 的基础操作, 当然, DataFrame 就是 Dataset, 所以这些操作大部分也适用于 DataFrame
-
有类型的转换操作
-
无类型的转换操作
-
基础
Action -
空值如何处理
-
统计操作
8.1. 有类型操作
| 分类 | 算子 | 解释 |
|---|---|---|
|
转换 |
|
通过 |
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
过滤 |
|
|
|
聚合 |
|
其实这也印证了分组后必须聚合的道理 |
|
切分 |
|
|
|
|
|
|
|
排序 |
|
|
|
|
其实 |
|
|
分区 |
|
减少分区, 此算子和 |
|
|
|
|
|
去重 |
|
使用 |
|
|
当  所以, 使用 |
|
|
集合操作 |
|
|
|
|
求得两个集合的交集 |
|
|
|
求得两个集合的并集 |
|
|
|
限制结果集数量 |
8.2. 无类型转换
| 分类 | 算子 | 解释 |
|---|---|---|
|
选择 |
|
|
|
|
在 |
|
|
|
通过 |
|
|
|
修改列名 |
|
|
剪除 |
drop |
剪掉某个列 |
|
聚合 |
groupBy |
按照给定的行进行分组 |
8.5. Column 对象
Column 表示了 Dataset 中的一个列, 并且可以持有一个表达式, 这个表达式作用于每一条数据, 对每条数据都生成一个值, 之所以有单独这样的一个章节是因为列的操作属于细节, 但是又比较常见, 会在很多算子中配合出现
| 分类 | 操作 | 解释 |
|---|---|---|
|
创建 |
|
单引号 |
|
|
同理, |
|
|
|
|
|
|
|
|
|
|
|
前面的 |
|
|
|
可以通过
|
|
|
别名和转换 |
|
|
|
|
通过 |
|
|
添加列 |
|
通过 |
|
操作 |
|
通过 |
|
|
通过 |
|
|
|
在排序的时候, 可以通过 |
9. 缺失值处理
-
DataFrame中什么时候会有无效值 -
DataFrame如何处理无效的值 -
DataFrame如何处理null
- 缺失值的处理思路
-
如果想探究如何处理无效值, 首先要知道无效值从哪来, 从而分析可能产生的无效值有哪些类型, 在分别去看如何处理无效值
- 什么是缺失值
-
一个值本身的含义是这个值不存在则称之为缺失值, 也就是说这个值本身代表着缺失, 或者这个值本身无意义, 比如说
null, 比如说空字符串
关于数据的分析其实就是统计分析的概念, 如果这样的话, 当数据集中存在缺失值, 则无法进行统计和分析, 对很多操作都有影响
- 缺失值如何产生的
-

Spark 大多时候处理的数据来自于业务系统中, 业务系统中可能会因为各种原因, 产生一些异常的数据
例如说因为前后端的判断失误, 提交了一些非法参数. 再例如说因为业务系统修改
mysql表结构产生的一些空值数据等. 总之在业务系统中出现缺失值其实是非常常见的一件事, 所以大数据系统就一定要考虑这件事. - 缺失值的类型
-
常见的缺失值有两种
-
null,NaN等特殊类型的值, 某些语言中null可以理解是一个对象, 但是代表没有对象,NaN是一个数字, 可以代表不是数字针对这一类的缺失值,
Spark提供了一个名为DataFrameNaFunctions特殊类型来操作和处理 -
"Null","NA"," "等解析为字符串的类型, 但是其实并不是常规字符串数据针对这类字符串, 需要对数据集进行采样, 观察异常数据, 总结经验, 各个击破
-
DataFrameNaFunctions- 如何使用
SparkSQL处理null和NaN? - 如何使用
SparkSQL处理异常字符串 ?
10. 聚合
-
groupBy -
rollup -
cube -
pivot -
RelationalGroupedDataset上的聚合操作
groupBy- 多维聚合
rollup操作符- 使用
rollup完成pm值的统计 cubeSparkSQL中支持的SQL语句实现cube功能RelationalGroupedDataset
11. 连接
-
无类型连接
join -
连接类型
Join Types
- 无类型连接算子
join的API -
- Step 1: 什么是连接
-
按照 PostgreSQL 的文档中所说, 只要能在一个查询中, 同一时间并发的访问多条数据, 就叫做连接.
做到这件事有两种方式
-
一种是把两张表在逻辑上连接起来, 一条语句中同时访问两张表
select * from user join address on user.address_id = address.id -
还有一种方式就是表连接自己, 一条语句也能访问自己中的多条数据
select * from user u1 join (select * from user) u2 on u1.id = u2.id
-
- Step 2:
join算子的使用非常简单, 大致的调用方式如下 -
join(right: Dataset[_], joinExprs: Column, joinType: String): DataFrame - Step 3: 简单连接案例
-
表结构如下
+---+------+------+ +---+---------+ | id| name|cityId| | id| name| +---+------+------+ +---+---------+ | 0| Lucy| 0| | 0| Beijing| | 1| Lily| 0| | 1| Shanghai| | 2| Tim| 2| | 2|Guangzhou| | 3|Danial| 0| +---+---------+ +---+------+------+如果希望对这两张表进行连接, 首先应该注意的是可以连接的字段, 比如说此处的左侧表
cityId和右侧表id就是可以连接的字段, 使用join算子就可以将两个表连接起来, 进行统一的查询val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 0)) .toDF("id", "name", "cityId") val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou")) .toDF("id", "name") person.join(cities, person.col("cityId") === cities.col("id")) .select(person.col("id"), person.col("name"), cities.col("name") as "city") .show() /** * 执行结果: * * +---+------+---------+ * | id| name| city| * +---+------+---------+ * | 0| Lucy| Beijing| * | 1| Lily| Beijing| * | 2| Tim|Guangzhou| * | 3|Danial| Beijing| * +---+------+---------+ */ - Step 4: 什么是连接?
-
现在两个表连接得到了如下的表
+---+------+---------+ | id| name| city| +---+------+---------+ | 0| Lucy| Beijing| | 1| Lily| Beijing| | 2| Tim|Guangzhou| | 3|Danial| Beijing| +---+------+---------+通过对这张表的查询, 这个查询是作用于两张表的, 所以是同一时间访问了多条数据
spark.sql("select name from user_city where city = ‘Beijing‘").show() /** * 执行结果 * * +------+ * | name| * +------+ * | Lucy| * | Lily| * |Danial| * +------+ */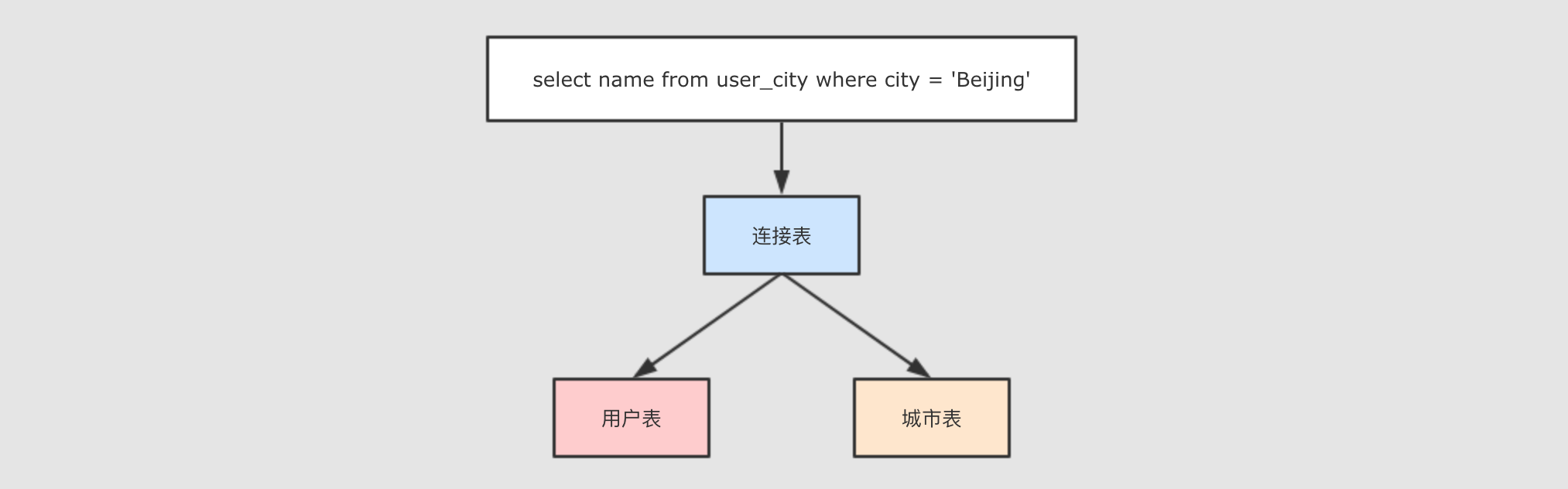
- 连接类型
-
如果要运行如下代码, 需要先进行数据准备
private val spark = SparkSession.builder() .master("local[6]") .appName("aggregation") .getOrCreate() import spark.implicits._ val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 3)) .toDF("id", "name", "cityId") person.createOrReplaceTempView("person") val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou")) .toDF("id", "name") cities.createOrReplaceTempView("cities")连接类型 类型字段 解释 交叉连接
cross- 解释
-
交叉连接就是笛卡尔积, 就是两个表中所有的数据两两结对
交叉连接是一个非常重的操作, 在生产中, 尽量不要将两个大数据集交叉连接, 如果一定要交叉连接, 也需要在交叉连接后进行过滤, 优化器会进行优化
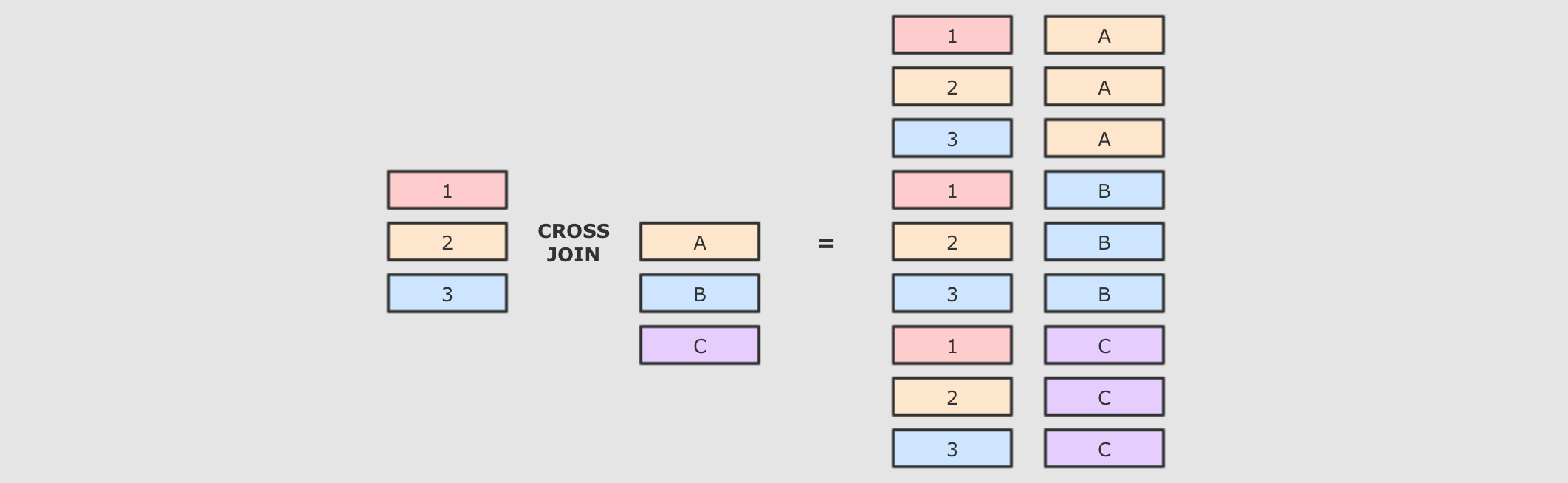
SQL语句-
select * from person cross join cities Dataset操作-
person.crossJoin(cities) .where(person.col("cityId") === cities.col("id")) .show()
内连接
inner- 解释
-
内连接就是按照条件找到两个数据集关联的数据, 并且在生成的结果集中只存在能关联到的数据

SQL语句-
select * from person inner join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities, joinExprs = person("cityId") === cities("id"), joinType = "inner") .show()
全外连接
outer,full,fullouter- 解释
-
内连接和外连接的最大区别, 就是内连接的结果集中只有可以连接上的数据, 而外连接可以包含没有连接上的数据, 根据情况的不同, 外连接又可以分为很多种, 比如所有的没连接上的数据都放入结果集, 就叫做全外连接

SQL语句-
select * from person full outer join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities, joinExprs = person("cityId") === cities("id"), joinType = "full") // "outer", "full", "full_outer" .show()
左外连接
leftouter,left- 解释
-
左外连接是全外连接的一个子集, 全外连接中包含左右两边数据集没有连接上的数据, 而左外连接只包含左边数据集中没有连接上的数据

SQL语句-
select * from person left join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities, joinExprs = person("cityId") === cities("id"), joinType = "left") // leftouter, left .show()
LeftAntileftanti- 解释
-
LeftAnti是一种特殊的连接形式, 和左外连接类似, 但是其结果集中没有右侧的数据, 只包含左边集合中没连接上的数据
SQL语句-
select * from person left anti join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities, joinExprs = person("cityId") === cities("id"), joinType = "left_anti") .show()
LeftSemileftsemi- 解释
-
和
LeftAnti恰好相反,LeftSemi的结果集也没有右侧集合的数据, 但是只包含左侧集合中连接上的数据
SQL语句-
select * from person left semi join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities, joinExprs = person("cityId") === cities("id"), joinType = "left_semi") .show()
右外连接
rightouter,right- 解释
-
右外连接和左外连接刚好相反, 左外是包含左侧未连接的数据, 和两个数据集中连接上的数据, 而右外是包含右侧未连接的数据, 和两个数据集中连接上的数据

SQL语句-
select * from person right join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities, joinExprs = person("cityId") === cities("id"), joinType = "right") // rightouter, right .show()
- [扩展] 广播连接
-
- Step 1: 正常情况下的
Join过程 -
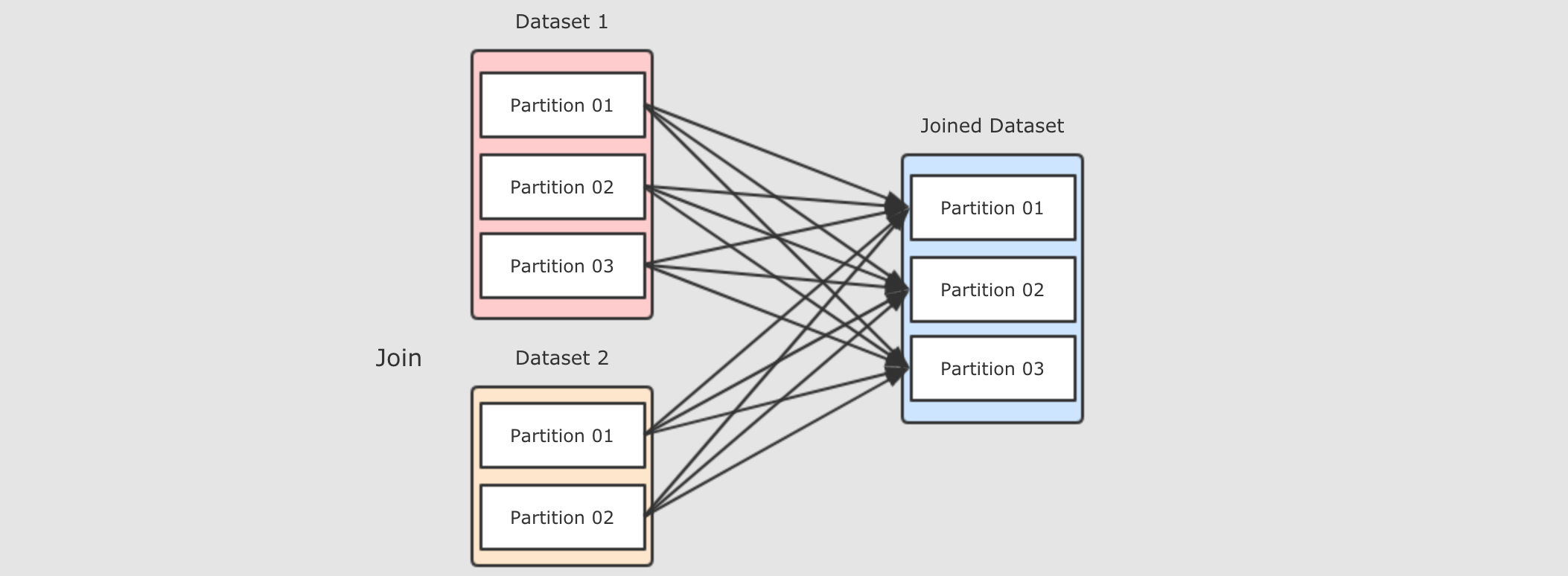
Join会在集群中分发两个数据集, 两个数据集都要复制到Reducer端, 是一个非常复杂和标准的ShuffleDependency, 有什么可以优化效率吗? - Step 2:
Map端Join -
前面图中看的过程, 之所以说它效率很低, 原因是需要在集群中进行数据拷贝, 如果能减少数据拷贝, 就能减少开销
如果能够只分发一个较小的数据集呢?
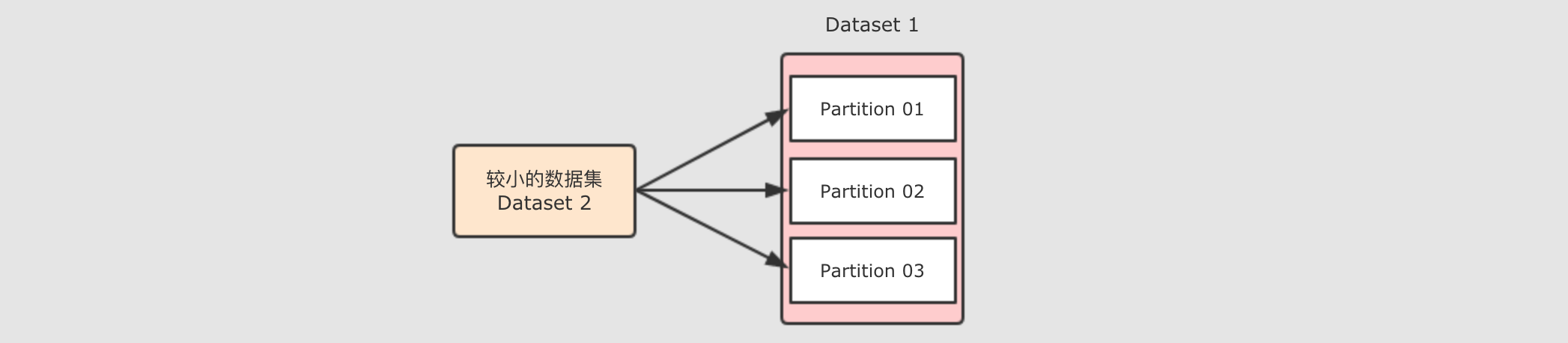
可以将小数据集收集起来, 分发给每一个
Executor, 然后在需要Join的时候, 让较大的数据集在Map端直接获取小数据集, 从而进行Join, 这种方式是不需要进行Shuffle的, 所以称之为Map端Join - Step 3:
Map端Join的常规实现 -
如果使用
RDD的话, 该如何实现Map端Join呢?val personRDD = spark.sparkContext.parallelize(Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 3))) val citiesRDD = spark.sparkContext.parallelize(Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou"))) val citiesBroadcast = spark.sparkContext.broadcast(citiesRDD.collectAsMap()) val result = personRDD.mapPartitions( iter => val citiesMap = citiesBroadcast.value // 使用列表生成式 yield 生成列表 val result = for (person <- iter if citiesMap.contains(person._3)) yield (person._1, person._2, citiesMap(person._3)) result ).collect() result.foreach(println(_)) - Step 4: 使用
Dataset实现Join的时候会自动进行Map端Join -
自动进行
Map端Join需要依赖一个系统参数spark.sql.autoBroadcastJoinThreshold, 当数据集小于这个参数的大小时, 会自动进行Map端Join如下, 开启自动
Joinprintln(spark.conf.get("spark.sql.autoBroadcastJoinThreshold").toInt / 1024 / 1024) println(person.crossJoin(cities).queryExecution.sparkPlan.numberedTreeString)当关闭这个参数的时候, 则不会自动 Map 端 Join 了
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1) println(person.crossJoin(cities).queryExecution.sparkPlan.numberedTreeString) - Step 5: 也可以使用函数强制开启 Map 端 Join
-
在使用 Dataset 的 join 时, 可以使用 broadcast 函数来实现 Map 端 Join
import org.apache.spark.sql.functions._ spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1) println(person.crossJoin(broadcast(cities)).queryExecution.sparkPlan.numberedTreeString)即使是使用 SQL 也可以使用特殊的语法开启
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1) val resultDF = spark.sql( """ |select /*+ MAPJOIN (rt) */ * from person cross join cities rt """.stripMargin) println(resultDF.queryExecution.sparkPlan.numberedTreeString)
- Step 1: 正常情况下的
以上是关于Update:sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作的主要内容,如果未能解决你的问题,请参考以下文章