pandas 模块
Posted zhangchaocoming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas 模块相关的知识,希望对你有一定的参考价值。
[TOC]
pandas 模块
1.pandas生成表格
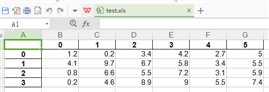
# test.csv文件原数据
1.2,0.2,3.4,4.2,2.7,5.0
4.1,9.7,6.7,5.8,3.4,5.5
0.8,6.6,5.5,7.2,3.1,5.9
0.2,4.6,8.9,9.0,5.5,7.4
import pandas as pd
df=pd.read_csv(‘test.csv‘,header=None)
df.to_excel(‘test.xls‘)
2.生成数组
import numpy as np
index= pd.date_range(‘2019-01-31‘,periods=6,freq=‘M‘)
# print(index)
columns=[‘c1‘,‘c2‘,‘c3‘,‘c4‘]
# print(columns)
val= np.random.randn(6,4)
# print(val)
df=pd.DataFrame(index=index,columns=columns,data=val)
print(df)
# 生成的数组
c1 c2 c3 c4
2019-01-31 -0.868071 -0.160563 -0.093496 -0.901875
2019-02-28 1.165258 -0.099220 -0.317978 -1.493482
2019-03-31 0.078065 -1.145294 1.456669 0.856255
2019-04-30 0.272448 0.563404 0.833652 -0.005343
2019-05-31 -0.787750 0.417897 0.559839 -0.581065
2019-06-30 -0.126699 1.475188 0.200398 -0.697084
3.操作文件
保存文件
import pandas as pd
import numpy as np
index= pd.date_range(‘2019-01-31‘,periods=6,freq=‘M‘)
# print(index)
np.random.seed(10)
columns=[‘c1‘,‘c2‘,‘c3‘,‘c4‘]
# print(columns)
val= np.random.randn(6,4)
# print(val)
df=pd.DataFrame(index=index,columns=columns,data=val)
# print(df)
# 保存文件
df.to_excel(‘date_c.xls‘)
读出文件
# 读出文件
# 不指定index_col自动生成从0开始的行索引,指定index_col=[0]表示零列索引开始, 即没索引,以第一列日期为索引;指定几就以第几列为索引
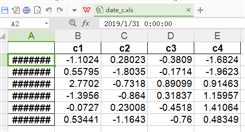
df1=pd.read_excel(‘date_c.xls‘,index_col=[0])
print(df1)
‘‘‘
c1 c2 c3 c4
2019-01-31 0.000000 0.000000 0.000000 0.000000
2019-02-28 0.557948 -1.803463 -0.171438 -1.962274
2019-03-31 2.770204 -0.731753 0.890994 0.914631
2019-04-30 -1.395630 -0.864024 0.318371 1.159572
2019-05-31 -0.072750 0.230076 -0.451781 1.410644
2019-06-30 0.534407 -1.164283 -0.760032 0.483490
‘‘‘
行索引index和列索引columns和元素values
df1=pd.read_excel(‘date_c.xls‘,index_col=[0]) # 读出Excel表格
print(df1.index) # 打印索引(行)
print(df1.columns) # 打印列索引
print(df1.values) # 以列表套列表的形式分行打印所有的值
‘‘‘
DatetimeIndex([‘2019-01-31‘, ‘2019-02-28‘, ‘2019-03-31‘, ‘2019-04-30‘,
‘2019-05-31‘, ‘2019-06-30‘],
dtype=‘datetime64[ns]‘, freq=None)
Index([‘c1‘, ‘c2‘, ‘c3‘, ‘c4‘], dtype=‘object‘)
[[-1.10237008 0.28023149 -0.38087073 -1.68236505]
[ 0.55794826 -1.80346251 -0.17143782 -1.96227377]
[ 2.7702038 -0.73175303 0.8909936 0.91463091]
[-1.39562998 -0.86402444 0.31837052 1.15957249]
[-0.07274987 0.23007624 -0.45178069 1.4106437 ]
[ 0.53440726 -1.16428321 -0.76003191 0.48348979]]
‘‘‘
对文件数据读改
按照列索引取值
print(df1[[‘c1‘,‘c2‘]]) # 按照列索引取值,取出c1和c2列的数据
‘‘‘
c1 c2
2019-01-31 -1.102370 0.280231
2019-02-28 0.557948 -1.803463
2019-03-31 2.770204 -0.731753
2019-04-30 -1.395630 -0.864024
2019-05-31 -0.072750 0.230076
2019-06-30 0.534407 -1.164283
‘‘‘
按照行索引取值
print(df1.loc[‘2019-01-31‘]) # 按照索引取值(按照行索引取出所在行的数据)
‘‘‘
c1 -1.102370
c2 0.280231
c3 -0.380871
c4 -1.682365
Name: 2019-01-31 00:00:00, dtype: float64
‘‘‘
切片取值
print(df1.loc[‘2019-01-31‘:‘2019-05-31‘]) # 按照索引切片(指的是行索引)在此表示取1-6月份的数据
‘‘‘
c1 c2 c3 c4
2019-01-31 -1.102370 0.280231 -0.380871 -1.682365
2019-02-28 0.557948 -1.803463 -0.171438 -1.962274
2019-03-31 2.770204 -0.731753 0.890994 0.914631
2019-04-30 -1.395630 -0.864024 0.318371 1.159572
2019-05-31 -0.072750 0.230076 -0.451781 1.410644
‘‘‘
取单个元素
print(df1.iloc[0,0]) # 零行零列,表示取出第一行第一个元素。np.random.seed(10)限制元素的变化
‘‘‘
-1.1023700810399333
‘‘‘
# 修改元素
df1.iloc[0,:] = 0 # 表示第零行所有元素都修改成零
print(df1)
‘‘‘
c1 c2 c3 c4
2019-01-31 0.000000 0.000000 0.000000 0.000000
2019-02-28 0.557948 -1.803463 -0.171438 -1.962274
2019-03-31 2.770204 -0.731753 0.890994 0.914631
2019-04-30 -1.395630 -0.864024 0.318371 1.159572
2019-05-31 -0.072750 0.230076 -0.451781 1.410644
2019-06-30 0.534407 -1.164283 -0.760032 0.483490
‘‘‘
以上是关于pandas 模块的主要内容,如果未能解决你的问题,请参考以下文章