大数据--sqoop数据导入导出
Posted jeff190812
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据--sqoop数据导入导出相关的知识,希望对你有一定的参考价值。
1、在mysql中创建表student
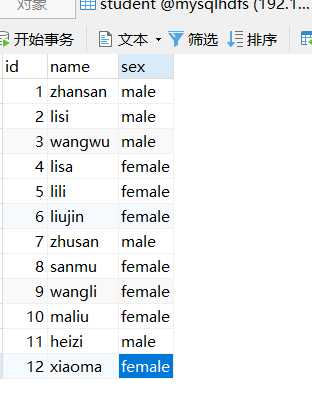
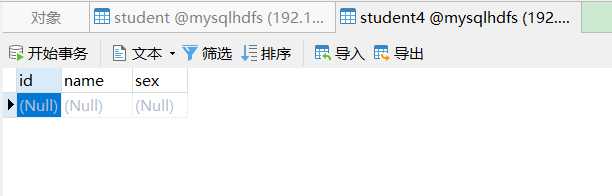
2、在MySQL中创建表student4
3、在hive中创建表student3
------------------------------------------------------------------------------
hive (default)> create table student3(id int,name string,sex string)
> row format delimited fields terminated by ‘\\t‘;
OK
Time taken: 0.064 seconds
---------------------------------------------------------------------------------------
4、使用sqoop将MySQL里面的student表的数据迁移到hive中,男性数据(male)迁移到student1,女性数据(female)迁移到student2中
--------------------------------------------------------------------------------------
sqoop import --connect "jdbc:mysql://bigdata113:3306/mysqlhdfs?useSSL=false" --username root --password 000000 --num-mappers 1 --hive-import --fields-terminated-by "\\t" --hive-overwrite --hive-table student1 --table student --where "sex=‘male‘"
hive (default)> select * from student1;
OK
student1.id student1.name student1.sex
1 zhansan male
2 lisi male
3 wangwu male
7 zhusan male
11 heizi male
Time taken: 0.06 seconds, Fetched: 5 row(s)
--------------------------------------------------------------
sqoop import --connect "jdbc:mysql://bigdata113:3306/mysqlhdfs?useSSL=false" --username root --password 000000 --num-mappers 1 --hive-import --fields-terminated-by "\\t" --hive-overwrite --hive-table student2 --table student --where "sex=‘female‘"
hive (default)> select * from student2;
OK
student2.id student2.name student2.sex
4 lisa female
5 lili female
6 liujin female
8 sanmu female
9 wangli female
10 maliu female
12 xiaoma female
Time taken: 0.072 seconds, Fetched: 7 row(s)
---------------------------------------------------------------
5、在hive中将student1中的男性数据的id在6以下的数据插入student3表中
--------------------------------------------------------------
hive (default)> insert overwrite table student3 select id,name,sex from student1 where id < 6;
Query ID = root_20191005170844_905a4958-9ecc-4dbb-9d00-1892dc5bdd04
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there‘s no reduce operator
Starting Job = job_1570262298038_0007, Tracking URL = http://bigdata112:8088/proxy/application_1570262298038_0007/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1570262298038_0007
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-10-05 17:08:53,588 Stage-1 map = 0%, reduce = 0%
2019-10-05 17:08:59,078 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.87 sec
MapReduce Total cumulative CPU time: 870 msec
Ended Job = job_1570262298038_0007
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://mycluster/user/hive/warehouse/student3/.hive-staging_hive_2019-10-05_17-08-44_914_826287410471570054-1/-ext-10000
Loading data to table default.student3
Table default.student3 stats: [numFiles=1, numRows=3, totalSize=41, rawDataSize=38]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 0.87 sec HDFS Read: 3822 HDFS Write: 113 SUCCESS
Total MapReduce CPU Time Spent: 870 msec
OK
id name sex
Time taken: 16.548 seconds
hive (default)> select * from student3;
OK
student3.id student3.name student3.sex
1 zhansan male
2 lisi male
3 wangwu male
Time taken: 0.051 seconds, Fetched: 3 row(s)
-----------------------------------------------------------------
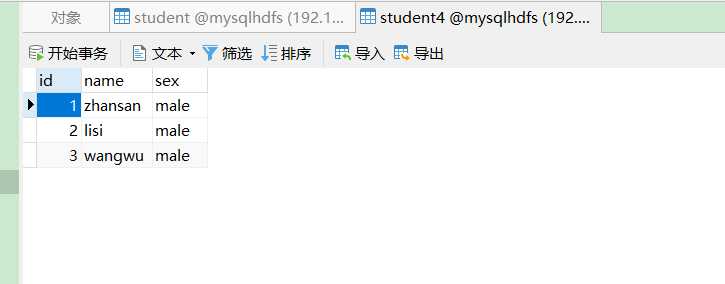
6、使用sqoop将hive中的student3中的数据迁移到MySQL中的表student4中
-----------------------------------------------------------------
[root@bigdata113 ~]# sqoop export --connect "jdbc:mysql://bigdata113:3306/mysqlhdfs?useSSL=false" --username root --password 000000 --export-dir /user/hive/warehouse/student3 --table student4 --num-mappers 1 --input-fields-terminated-by "\\t"
以上是关于大数据--sqoop数据导入导出的主要内容,如果未能解决你的问题,请参考以下文章