动态字体加密分析
Posted youxiu123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动态字体加密分析相关的知识,希望对你有一定的参考价值。
动态字体反爬
字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的。
现在貌似不少网站都有采用这种反爬机制,我们通过猫眼的实际情况来解释一下。
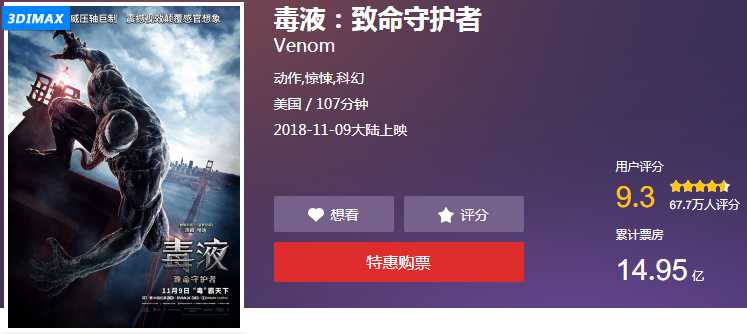
下图的是猫眼网页上的显示:
检查元素看一下
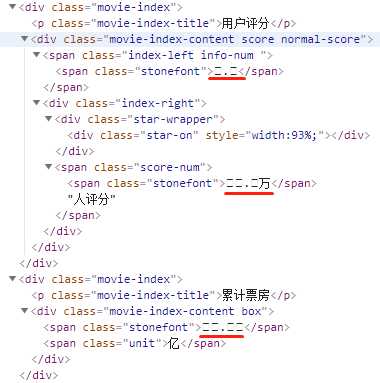
这是什么鬼,关键信息全是乱码。
熟悉 CSS 的同学会知道,CSS 中有一个 @font-face,它允许网页开发者为其网页指定在线字体。原本是用来消除对用户电脑字体的依赖,现在有了新作用——反爬。
汉字光常用字就有好几千,如果全部放到自定义的字体中,那么字体文件就会变得很大,必然影响网页的加载速度,因此一般网站会选取关键内容加以保护,如上图,知道了等于不知道。
这里的乱码是由于 unicode 编码导致的,查看源文件可以看到具体的编码信息。
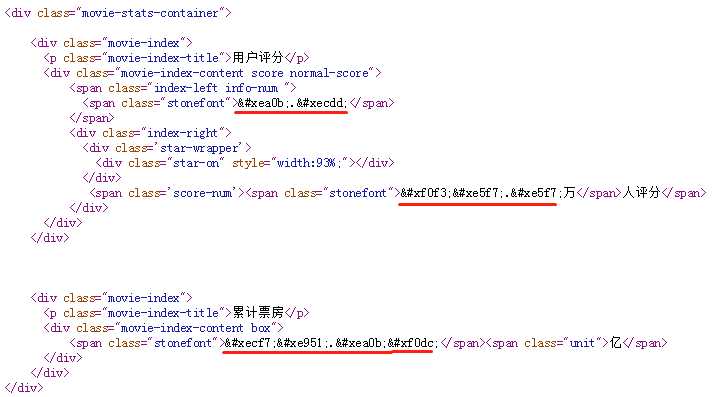
搜索 stonefont,找到 @font-face 的定义:

这里的 .woff 文件就是字体文件,我们将其下载下来,利用 http://fontstore.baidu.com/static/editor/index.html 网页将其打开,显示如下:

网页源码中显示的  跟这里显示的是不是有点像?事实上确实如此,去掉开头的 &#x 和结尾的 ; 后,剩余的4个16进制显示的数字加上 uni 就是字体文件中的编码。所以  对应的就是数字“9”。
知道了原理,我们来看下如何实现。
处理字体文件,我们需要用到 FontTools 库。
先将字体文件转换为 xml 文件看下:
from fontTools.ttLib import TTFont font = TTFont(‘bb70be69aaed960fa6ec3549342b87d82084.woff‘) font.saveXML(‘bb70be69aaed960fa6ec3549342b87d82084.xml‘)
打开 xml 文件
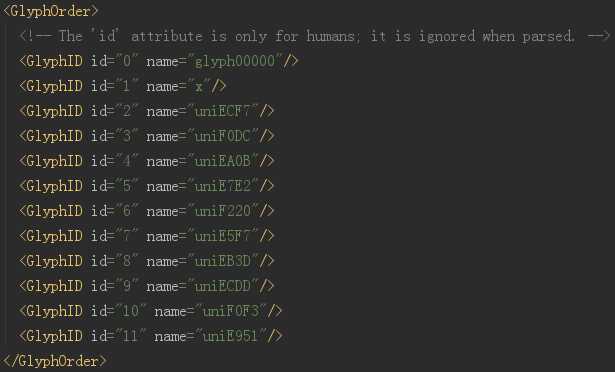
开头显示的就是全部的编码,这里的 id 仅仅是编号而已,千万别当成是对应的真实值。实际上,整个字体文件中,没有任何地方是说明 EA0B 对应的真实值是啥的。
看到下面
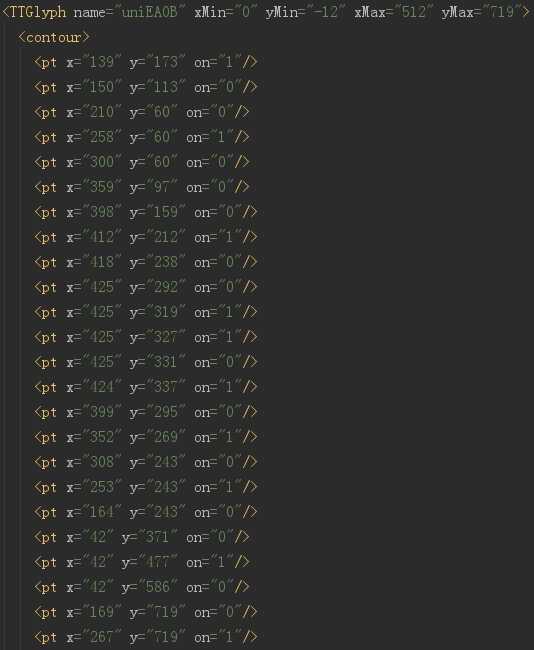
这里就是每个字对应的字体信息,计算机显示的时候,根本不需要知道这个字是啥,只需要知道哪个像素是黑的,哪个像素是白的就可以了。
猫眼的字体文件是动态加载的,每次刷新都会变,虽然字体中定义的只有 0-9 这9个数字,但是编码和顺序都是会变的。就是说,这个字体文件中“EA0B”代表“9”,在别的文件中就不是了。
但是,有一样是不变的,就是这个字的形状,也就是上图中定义的这些点。
我们先随便下载一个字体文件,命名为 base.woff,然后利用 fontstore 网站查看编码和实际值的对应关系,手工做成字典并保存下来。爬虫爬取的时候,下载字体文件,根据网页源码中的编码,在字体文件中找到“字形”,再循环跟 base.woff 文件中的“字形”做比较,“字形”一样那就说明是同一个字了。在 base.woff 中找到“字形”后,获取“字形”的编码,而之前我们已经手工做好了编码跟值的映射表,由此就可以得到我们实际想要的值了。
这里的前提是每个字体文件中所定义的“字形”都是一样的(猫眼目前是这样的,以后也许还会更改策略),如果更复杂一点,每个字体中的“字形”都加一点点的随机形变,那这个方法就没有用了,只能祭出杀手锏“OCR”了。
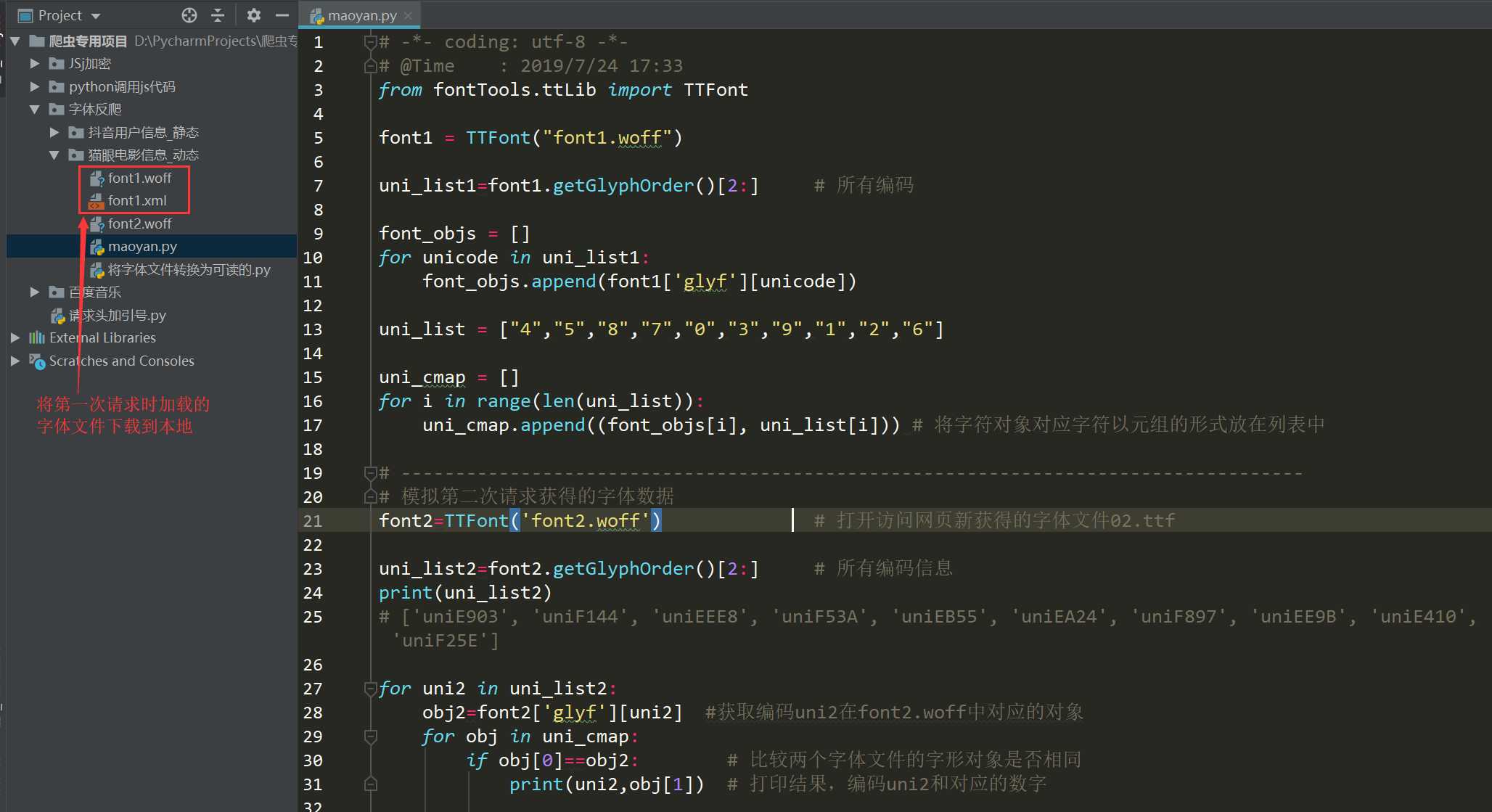
- 第一次请求将字体文件下载到本地,手动写出映射关系 - 第二次请求网页时只需要比较两个文件的字形是否相同

from fontTools.ttLib import TTFont
font1 = TTFont("font1.woff")
uni_list1=font1.getGlyphOrder()[2:] # 所有编码
font_objs = []
for unicode in uni_list1:
font_objs.append(font1[‘glyf‘][unicode])
uni_list = ["4","5","8","7","0","3","9","1","2","6"]
uni_cmap = []
for i in range(len(uni_list)):
uni_cmap.append((font_objs[i], uni_list[i])) # 将字符对象对应字符以元组的形式放在列表中
# -----------------------------------------------------------------------------------
# 模拟第二次请求获得的字体数据
font2=TTFont(‘font2.woff‘) # 打开访问网页新获得的字体文件02.ttf
uni_list2=font2.getGlyphOrder()[2:] # 所有编码信息
print(uni_list2)
# [‘uniE903‘, ‘uniF144‘, ‘uniEEE8‘, ‘uniF53A‘, ‘uniEB55‘, ‘uniEA24‘, ‘uniF897‘, ‘uniEE9B‘, ‘uniE410‘, ‘uniF25E‘]
for uni2 in uni_list2:
obj2=font2[‘glyf‘][uni2] #获取编码uni2在font2.woff中对应的对象
for obj in uni_cmap:
if obj[0]==obj2: # 比较两个字体文件的字形对象是否相同
print(uni2,obj[1]) # 打印结果,编码uni2和对应的数字
实战演示


# -*- coding: utf-8 -*- # @Time : 2019/8/2 14:40 import os import re import requests from fontTools.ttLib import TTFont # 将字体转换为xml文件 font = TTFont(‘font_template.woff‘) # font.saveXML(‘font_template.xml‘) # 转换xml文件需将此注释打开 # 获取字体文件的unicode编码 uni_list = font.getGlyphOrder()[2:] font_list = [‘7‘,‘5‘,‘0‘,‘2‘,‘6‘,‘8‘,‘1‘,‘9‘,‘4‘,‘3‘] # 取出每个unicode所对应的字形对象 font_objs = [] for i in uni_list: font_objs.append(font["glyf"][i]) # 将每个数字和它对应的字形对象以元组的形式放在列表中[字形对象永远不会变] uni_cmap = [] for i in range(len(uni_list)): uni_cmap.append((font_objs[i],font_list[i])) # print(uni_cmap) # 字体映射返回映射结果 def font_map(font_name,font_url): # 下载每个页面的字体文件 response = requests.get(font_url).content with open(font_name,"wb") as fp: fp.write(response) # 打开字体文件 font_new = TTFont(font_name) # 获取所有unicode编码信息 uni_new_list =font_new.getGlyphOrder()[2:] font_lis = [] for new_uni in uni_new_list: # 获取字体对应的字型对象 obj_uni = font_new["glyf"][new_uni] # 循环我们之前保存的映射关系uni_cmap[("字形对象",数字),] for obj in uni_cmap: # 判断新下载的字形对象与uni_cmap中的字形对象是否相同 if obj[0] == obj_uni: new_uni = re.sub("uni", "&#x", new_uni, count=1) + ";" font_lis.append(new_uni.lower():int(obj[1])) # 将每次下载的字体文件删除 os.remove(font_name) return font_lis 字体映射
# 字体替换 def font_replace(font_res,response): ret = response # 这里注意我们在字体替换的时候一定是所有字体替换完成在将整张html页面返回 for font_dic in font_res: for key,value in font_dic.items(): if key in ret: ret = ret.replace(key,str(value)) return ret html页面字体替换
# 字体下载[下载每个页面的字体文件] font_url = ‘http:‘ + re.findall("<style>.*?@font-face.*?\\),.*?\\(‘(.*?)‘\\) format.*?</style>", res, re.S)[0] font_name = font_url.split("/")[-1]
以上是关于动态字体加密分析的主要内容,如果未能解决你的问题,请参考以下文章