服务器端的GPU使用
Posted zhuchengchao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务器端的GPU使用相关的知识,希望对你有一定的参考价值。
服务器端的GPU使用
查看GPU信息
查看nvidia GPU信息:
# 输入指令 lspci | grep -i nvidia # 结果如下: # 04:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1) # 05:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1) # 08:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1) # 09:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1) # 84:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1) # 85:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1) # 88:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1) # 89:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1)输出结果
04:00.0,可用于后续查看详细的信息查看指定显卡的详细信息:
# 输入指令: lspci -v -s 04:00.0 # 输出结果: # 04:00.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1) # Subsystem: NVIDIA Corporation Device 1214 # Flags: bus master, fast devsel, latency 0, IRQ 26, NUMA node 0 # Memory at c4000000 (32-bit, non-prefetchable) [size=16M] # Memory at 27800000000 (64-bit, prefetchable) [size=16G] # Memory at 27c00000000 (64-bit, prefetchable) [size=32M] # Capabilities: <access denied> # Kernel driver in use: nvidia # Kernel modules: nvidiafb, nouveau, nvidia_384_drm, nvidia_384
查看GPU的使用信息
nvidia-smi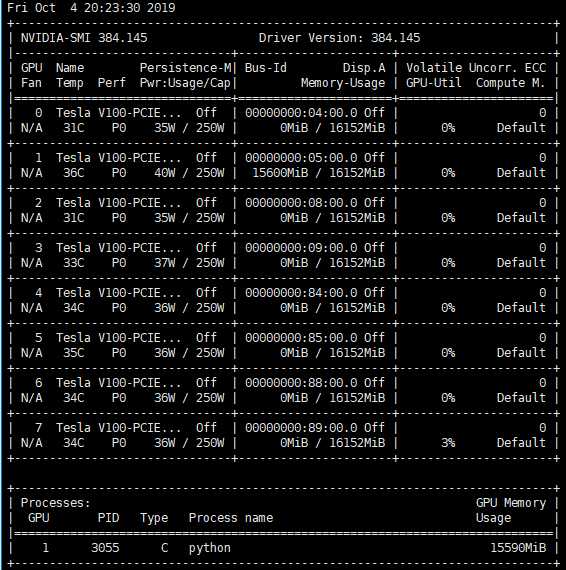
其主要看
Memory-Usage栏,避免使用了其他人已经占用了显卡一般使用如下指令,周期性查看显卡的使用情况:
watch -n 10 nvidia-smi每10s刷新一下显示
指定GPU进行训练
在查看了GPU的信息后,在训练是指定空闲的GPU进行训练。
在终端执行时指定GPU
CUDA_VISIBLE_DEVICES=0 python3 ***.py # 指定GPU集群中第一块GPU使用,其他的屏蔽掉 # CUDA_VISIBLE_DEVICES=1 Only device 1 will be seen # CUDA_VISIBLE_DEVICES=0,1 Devices 0 and 1 will be visible # CUDA_VISIBLE_DEVICES="" No GPU will be visible在配置文件头上指定GPU,此方法和上述方法类似,以下举个例子:
- 创建
.sh文件; - 通过
chmod +x ***.sh给文件加入可执行的属性; - 在文件中写入:
#! /bin/bash CUDA_VISIBLE_DEVICES=1 python model_main.py --model_dir=training/model --pipeline_config_path=training/pipeline.config --num_train_steps=25000- 之后在执行时,通过
bash ***.sh运行即可。
- 创建
在Python代码中指定
import os os.environ["CUDA_VISIBLE_DEVICES"] = "0" #指定第一块gpu在tensorflow中指定GPU的使用
# allow_soft_placement=True : 如果你指定的设备不存在,允许TF自动分配设备
# log_device_placement=True : 是否打印设备分配日志
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
# 限制GPU资源的使用:两者选其一即可
# 方式一:限制GPU使用率
config.gpu_options.per_process_gpu_memory_fraction = 0.4 #占用40%显存
# 方式二:动态申请显存
config.gpu_options.allow_growth = True
sess = tf.Session(config=config) 参考:
https://blog.csdn.net/dcrmg/article/details/78146797?locationNum=5&fps=1
https://blog.csdn.net/pursuit_zhangyu/article/details/81077931
https://www.jianshu.com/p/5d47f152ff62
以上是关于服务器端的GPU使用的主要内容,如果未能解决你的问题,请参考以下文章