hive基础知识四
Posted lojun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive基础知识四相关的知识,希望对你有一定的参考价值。
1.1 数据的压缩说明
-
压缩模式评价
-
可使用以下三种标准对压缩方式进行评价
-
1、压缩比:压缩比越高,压缩后文件越小,所以压缩比越高越好
-
2、压缩时间:越快越好
-
3、已经压缩的格式文件是否可以再分割:可以分割的格式允许单一文件由多个Mapper程序处理,可以更好的并行化
-
-
-
常见压缩格式
| 压缩方式 | 压缩比 | 压缩速度 | 解压缩速度 | 是否可分割 |
|---|---|---|---|---|
| gzip | 13.4% | 21 MB/s | 118 MB/s | 否 |
| bzip2 | 13.2% | 2.4MB/s | 9.5MB/s | 是 |
| lzo | 20.5% | 135 MB/s | 410 MB/s | 是 |
| snappy | 22.2% | 172 MB/s | 409 MB/s | 否 |
-
Hadoop编码/解码器方式
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| BZip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compress.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
1.2 数据压缩使用
-
Hive表中间数据压缩(map端)
#设置为true为激活中间数据压缩功能,默认是false,没有开启 set hive.exec.compress.intermediate=true; #设置中间数据的压缩算法 set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;
-
Hive表最终输出结果压缩(reduce端)
set hive.exec.compress.output=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
2. hive表的文件存储格式
2.1 文件存储格式说明
-
Hive支持的存储数的格式主要有:textFile、sequencefile、orc、parquet。
-
其中textFile为默认格式,建表时默认为这个格式,导入数据时会直接把本地文件数据文件拷贝到hdfs上不进行处理。
注意:sequencefile、orc、parquet格式的表不能直接从本地文件导入数据,数据要先导入到TextFile格式的表中,然后再从textFile表中用insert导入到sequencefile、orc、parquet表中。
-
textFile 和 sequencefile的存储格式都是基于行存储的;
-
orc 和 parquet 是基于列式存储的。
2.2 文件存储格式使用对比
具体操作和文件存储格式对比使用详细见 《Hive 主流文件存储格式对比.md》
3、hive的函数
3.1 系统内置函数
-
1、查看系统自带的函数
show functions;
-
2、显示自带的函数的用法
-
语法结构
-
desc function 函数名;
-
desc function max;
-
3.2 自定义函数
-
Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展
-
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)
-
根据用户自定义函数类别分为以下三种:
-
1、UDF(User-Defined-Function)
-
一进一出
-
-
2、UDAF(User-Defined Aggregation Function)
-
聚合函数,多进一出
-
类似于count/max/min
-
-
-
3、UDTF(User-Defined Table-Generating Functions)
-
一进多出
-
-
-
官网地址
3.3 自定义UDF函数编程步骤
-
1、定义一个类继承org.apache.hadoop.hive.ql.UDF
-
2、需要实现evaluate函数;evaluate函数支持重载;
-
3、将程序打成jar包上传到linux服务器
-
4、在hive的命令行窗口创建函数
-
a) 添加 jar包
-
add jar xxxxx.jar (linux上jar包的路径)
-
-
b) 创建function
create [temporary] function [dbname.]function_name AS class_name;
-
-
5、hive命令行中删除函数
Drop [temporary] function [if exists] [dbname.]function_name;
-
6、注意事项
-
UDF必须要有返回类型,可以返回null,但是返回类型不能为void;
-
3.4 自定义UDF函数案例实战
-
1、需求
-
将输入的小写单词转化为大写
-
-
2、代码开发
-
1、创建maven工程
-
2、添加依赖
<dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.4</version> </dependency> </dependencies>
-
3、代码
package com.lowi.udf; import org.apache.hadoop.hive.ql.exec.UDF; //todo:自定义udf函数,实现小写转大写 public class MyUDF extends UDF //实现evaluate方法 public String evaluate(String word) if(word ==null) return null; return word.toUpperCase();
-
-
3、打成jar包上传到linux服务器上 /home/hadoop/hive_udf.jar
-
4、将jar包添加到hive的classpath
add jar /home/hadoop/hive_udf.jar;
-
5、创建临时函数与开发好的java class关联
create temporary function toUpper as "com.lowi.udf.MyUDF";
-
6、在sql语句中使用自定义UDF函数
select toUpper("abcdDEF") from student limit 1;

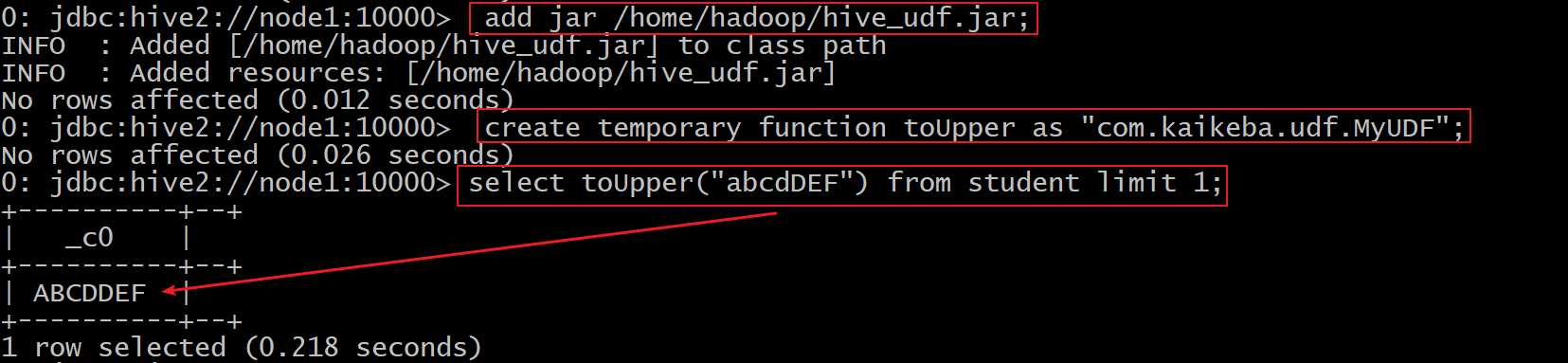
-
7、删除自定义UDF函数
drop function toUpper;
-
8、UDF函数永久使用
-
1、把自定义函数的jar上传到hdfs中
hdfs dfs -put hive_udf.jar /jars
-
2、创建永久函数
create function toUpper as ‘com.lowi.udf.MyUDF‘ using jar ‘hdfs://node1:9000/jars/hive_udf.jar‘;
-
3、在sql语句中使用自定义UDF函数
select toUpper("abcdDEF") from student limit 1;
-
4、hive客户端jdbc操作
4.1 引入依赖
<dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency> </dependencies>
4.2 代码开发
package com.lowi.jdbc; import java.sql.*; public class HiveJdbc private static String url="jdbc:hive2://node1:10000/default"; public static void main(String[] args) throws SQLException //获取数据库连接 Connection connection = DriverManager.getConnection(url, "root","123456"); //定义查询的sql语句 String sql="select * from employee"; try PreparedStatement ps = connection.prepareStatement(sql); ResultSet rs = ps.executeQuery(); while (rs.next()) //获取empid字段 int empid = rs.getInt(1); //获取deptid字段 int deptid = rs.getInt(2); //获取sex字段 String sex = rs.getString(3); //获取salary字段 double salary = rs.getDouble(4); System.out.println(empid+"\\t"+deptid+"\\t"+sex+"\\t"+salary); catch (SQLException e) e.printStackTrace();
5. hive的SerDe
5.1 hive的SerDe是什么
? Serde是 Serializer/Deserializer的简写。hive使用Serde进行行对象的序列与反序列化。最后实现把文件内容映射到 hive 表中的字段数据类型。
? 为了更好的阐述使用 SerDe 的场景,我们需要了解一下 Hive 是如何读数据的(类似于 HDFS 中数据的读写操作):
HDFS files –> InputFileFormat –> <key, value> –> Deserializer –> Row object ? Row object –> Serializer –> <key, value> –> OutputFileFormat –> HDFS files
5.2 hive的SerDe 类型
-
Hive 中内置org.apache.hadoop.hive.serde2 库,内部封装了很多不同的SerDe类型。
-
hive创建表时, 通过自定义的SerDe或使用Hive内置的SerDe类型指定数据的序列化和反序列化方式。
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
-
如上创建表语句, 使用row format 参数说明SerDe的类型。
-
可以创建表时使用用户自定义的Serde或者native Serde, 如果 ROW FORMAT没有指定或者指定了 ROW FORMAT DELIMITED就会使用native Serde。
-
-
Avro (Hive 0.9.1 and later)
-
ORC (Hive 0.11 and later)
-
RegEx
-
Thrift
-
Parquet (Hive 0.13 and later)
-
CSV (Hive 0.14 and later)
-
MultiDelimitSerDe
-
5.3 企业实战
5.3.1 通过MultiDelimitSerDe 解决多字符分割场景
-
1、创建表
create table t1 (id String, name string) row format serde ‘org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe‘ WITH SERDEPROPERTIES ("field.delim"="##");
-
2、准备数据 t1.txt
1##xiaoming 2##xiaowang 3##xiaozhang
-
3、加载数据
load data local inpath ‘/home/hadoop/t1.txt‘ into table t1;
-
4、查询数据
0: jdbc:hive2://node1:10000> select * from t1; +--------+------------+--+ | t1.id | t1.name | +--------+------------+--+ | 1 | xiaoming | | 2 | xiaowang | | 3 | xiaozhang | +--------+------------+--+
5.3.2 通过RegexSerDe 解决多字符分割场景
-
1、创建表
create table t2(id int, name string) row format serde ‘org.apache.hadoop.hive.serde2.RegexSerDe‘ WITH SERDEPROPERTIES ("input.regex" = "^(.*)\\\\#\\\\#(.*)$");
-
2、准备数据 t1.txt
1##xiaoming 2##xiaowang 3##xiaozhang
-
3、加载数据
load data local inpath ‘/home/hadoop/t1.txt‘ into table t2;
-
4、查询数据
0: jdbc:hive2://node1:10000> select * from t2; +--------+------------+--+ | t2.id | t2.name | +--------+------------+--+ | 1 | xiaoming | | 2 | xiaowang | | 3 | xiaozhang | +--------+------------+--+
5.3.3 通过JsonSerDe格式存储text文件
-
1、创建表
CREATE TABLE t3(id int, name string) ROW FORMAT SERDE ‘org.apache.hive.hcatalog.data.JsonSerDe‘ STORED AS TEXTFILE;
-
2、准备数据 json.txt
"id":1001,"name":"xiaoming" "id":1002,"name":"xiaowang" "id":1003,"name":"xiaozhang"
-
3、加载数据
load data local inpath ‘/home/hadoop/json.txt‘ into table t3;
-
4、查询数据
0: jdbc:hive2://node1:10000> select * from t3; +--------+------------+--+ | t3.id | t3.name | +--------+------------+--+ | 1001 | xiaoming | | 1002 | xiaowang | | 1003 | xiaozhang | +--------+------------+--+
5.3.4 使用 json函数 操作json格式数据
-
1、创建表
CREATE TABLE t4(jsoncontext string) STORED AS TEXTFILE;
-
2、准备数据 json.txt
"id":1001,"name":"xiaoming" "id":1002,"name":"xiaowang" "id":1003,"name":"xiaozhang"
-
3、加载数据
load data local inpath ‘/home/hadoop/json.txt‘ into table t4;
-
4、查询数据
0: jdbc:hive2://node1:10000> select * from t4; +---------------------------------+--+ | t4.jsoncontext | +---------------------------------+--+ | "id":1001,"name":"xiaoming" | | "id":1002,"name":"xiaowang" | | "id":1003,"name":"xiaozhang" | +---------------------------------+--+
-
5、json函数操作
-
get_json_object(string json_string, string path)
-
返回值: string
-
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
--查询表中的name字段 select get_json_object(jsoncontext,"$.name") as name from t4; +------------+--+ | name | +------------+--+ | xiaoming | | xiaowang | | xiaozhang | +------------+--+
-
-
json_tuple(jsonStr, k1, k2, ...)
-
返回值是一个元组
-
说明:解析jsonStr字符串中的k1、k2...字段,可以在一行中解析多个字段
select json_tuple(jsoncontext,"id","name") as (id,name) from t4;
+-------+------------+--+
| id | name |
+-------+------------+--+
| 1001 | xiaoming |
| 1002 | xiaowang |
| 1003 | xiaozhang |
+-------+------------+--+
-
-
6. hive的企业级调优
6.1 Fetch抓取
-
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算
-
例如:select * from employee;
-
在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台
-
-
在hive-default.xml.template文件中 hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
-
案例实操
-
把 hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序
set hive.fetch.task.conversion=none; select * from employee; select sex from employee; select sex from employee limit 3;
-
把hive.fetch.task.conversion设置成more,然后执行查询语句,如下查询方式都不会执行mapreduce程序。
set hive.fetch.task.conversion=more; select * from employee; select sex from employee; select sex from employee limit 3;
-
6.2 本地模式
-
在Hive客户端测试时,默认情况下是启用hadoop的job模式,把任务提交到集群中运行,这样会导致计算非常缓慢;
-
Hive可以通过本地模式在单台机器上处理任务。对于小数据集,执行时间可以明显被缩短。
-
案例实操
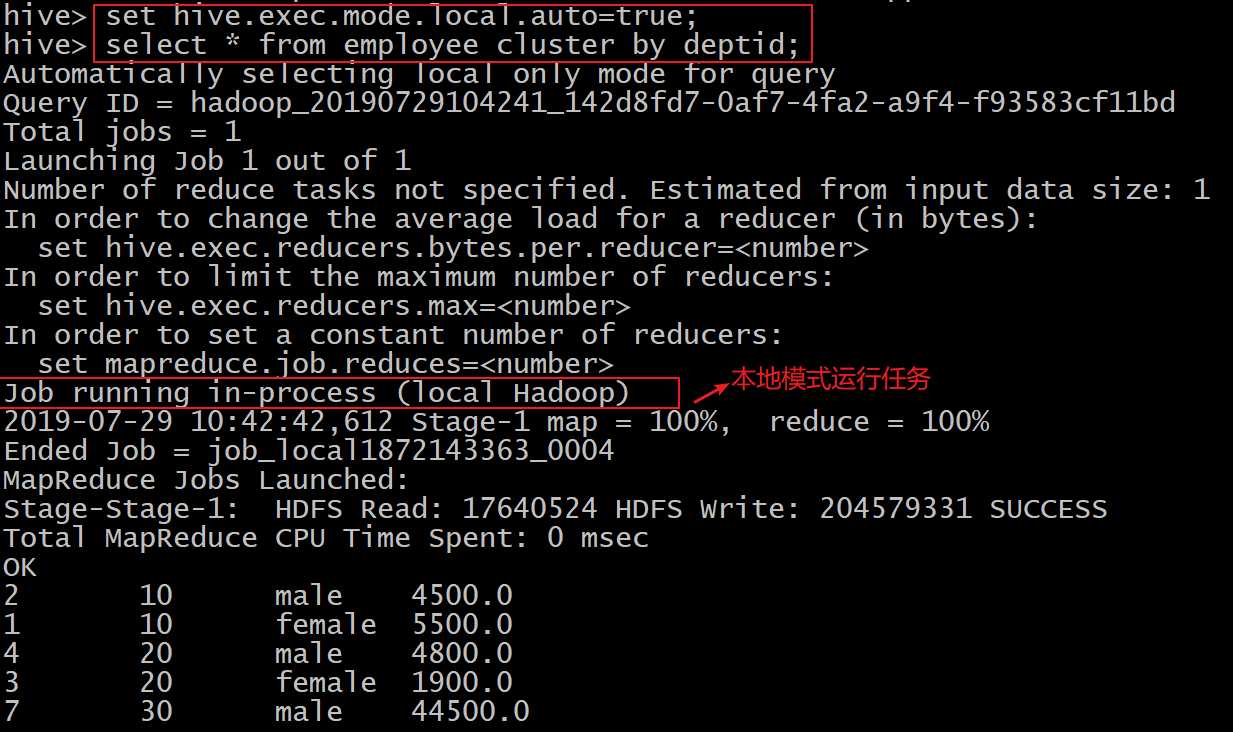
--开启本地模式,并执行查询语句 set hive.exec.mode.local.auto=true; //开启本地mr ? --设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式, --默认为134217728,即128M set hive.exec.mode.local.auto.inputbytes.max=50000000; ? --设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式, --默认为4 set hive.exec.mode.local.auto.input.files.max=5; ? --执行查询的sql语句 select * from employee cluster by deptid;
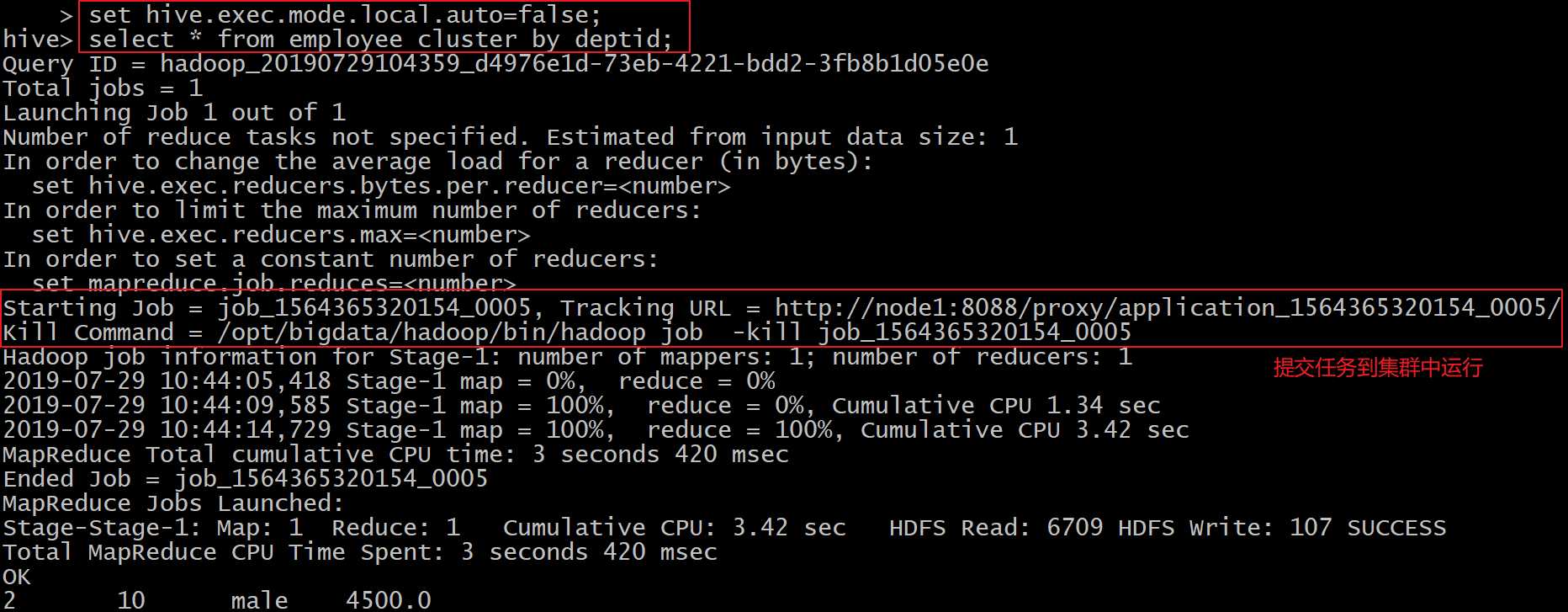
--关闭本地运行模式
set hive.exec.mode.local.auto=false;
select * from employee cluster by deptid;
集群模式:
本地模式:
6.3 表的优化
6.3.1 小表、大表 join
-
将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。
注意:实际测试发现,新版的hive已经对小表 join 大表和大表 join 小表进行了优化。小表放在左边和右边已经没有明显区别。
6.3.2 大表 join 大表
-
1.空 key 过滤
-
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。
-
此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。
-
-
2、空 key 转换
-
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在 join 的结果中,此时我们可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的 reducer 上。
-
6.3.3 map join
-
如果不指定MapJoin 或者不符合 MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存,在map端进行join,避免reducer处理。
-
1、开启MapJoin参数设置
--默认为true set hive.auto.convert.join = true;
-
2、大表小表的阈值设置(默认25M以下是小表)
set hive.mapjoin.smalltable.filesize=25000000;
-
3、MapJoin工作机制
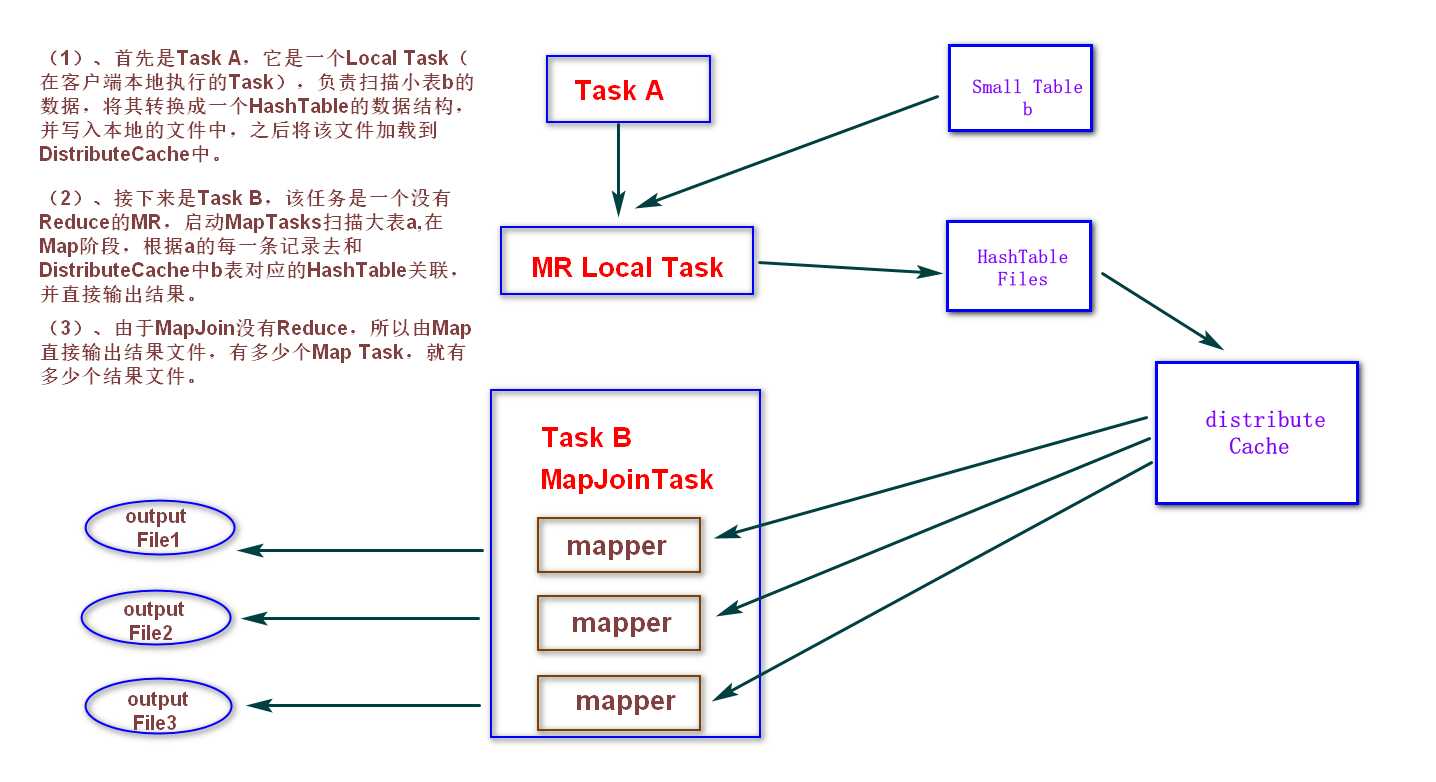
6.3.4 group By
-
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。
-
并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
-
开启Map端聚合参数设置
--是否在Map端进行聚合,默认为True set hive.map.aggr = true; --在Map端进行聚合操作的条目数目 set hive.groupby.mapaggr.checkinterval = 100000; --有数据倾斜的时候进行负载均衡(默认是false) set hive.groupby.skewindata = true;
当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
6.3.5 count(distinct)
-
数据量小的时候无所谓,数据量大的情况下,由于count distinct 操作需要用一个reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般count distinct使用先group by 再count的方式完成。
--每个reduce任务处理的数据量 默认256000000(256M) set hive.exec.reducers.bytes.per.reducer=32123456; select count(distinct ip ) from log_text; 转换成 select count(ip) from (select ip from log_text group by ip) t; 虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
6.3.6 笛卡尔积
-
尽量避免笛卡尔积,即避免join的时候不加on条件,或者无效的on条件
-
Hive只能使用1个reducer来完成笛卡尔积。
6.4 使用分区剪裁、列剪裁
-
尽可能早地过滤掉尽可能多的数据量,避免大量数据流入外层SQL。
-
列剪裁
-
只获取需要的列的数据,减少数据输入。
-
-
分区裁剪
-
分区在hive实质上是目录,分区裁剪可以方便直接地过滤掉大部分数据。
-
尽量使用分区过滤,少用select *
-
6.5 并行执行
-
把一个sql语句中没有相互依赖的阶段并行去运行。提高集群资源利用率
--开启并行执行 set hive.exec.parallel=true; --同一个sql允许最大并行度,默认为8。 set hive.exec.parallel.thread.number=16;
6.6 严格模式
-
Hive提供了一个严格模式,可以防止用户执行那些可能意想不到的不好的影响的查询。
-
通过设置属性hive.mapred.mode值为默认是非严格模式nonstrict 。开启严格模式需要修改hive.mapred.mode值为strict,开启严格模式可以禁止3种类型的查询。
--设置非严格模式(默认) set hive.mapred.mode=nonstrict; ? --设置严格模式 set hive.mapred.mode=strict;
-
(1)对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行
--设置严格模式下 执行sql语句报错; 非严格模式下是可以的 select * from order_partition; ? 异常信息:Error: Error while compiling statement: FAILED: SemanticException [Error 10041]: No partition predicate found for Alias "order_partition" Table "order_partition"
-
(2)对于使用了order by语句的查询,要求必须使用limit语句
--设置严格模式下 执行sql语句报错; 非严格模式下是可以的 select * from order_partition where month=‘2019-03‘ order by order_price; ? 异常信息:Error: Error while compiling statement: FAILED: SemanticException 1:61 In strict mode, if ORDER BY is specified, LIMIT must also be specified. Error encountered near token ‘order_price‘
-
(3)限制笛卡尔积的查询
-
严格模式下,避免出现笛卡尔积的查询
-
6.7 JVM重用
-
JVM重用是Hadoop调优参数的内容,其对Hive的性能具有非常大的影响,特别是对于很难避免小文件的场景或task特别多的场景,这类场景大多数执行时间都很短。
-
JVM重用可以使得JVM实例在同一个job中重新使用N次。减少进程的启动和销毁时间。
-- 设置jvm重用个数 set mapred.job.reuse.jvm.num.tasks=5;
6.8 推测执行
-
Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。(集群资源充裕的情况下可以考虑)
--开启推测执行机制 set hive.mapred.reduce.tasks.speculative.execution=true;
6.9 压缩
-
Hive表中间数据压缩
#设置为true为激活中间数据压缩功能,默认是false,没有开启 set hive.exec.compress.intermediate=true; #设置中间数据的压缩算法 set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;
-
Hive表最终输出结果压缩
set hive.exec.compress.output=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
6.10 数据倾斜
6.10.1 合理设置Map数
-
1) 通常情况下,作业会通过input的目录产生一个或者多个map任务。
主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小。
-
2) 是不是map数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,
而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。 -
3) 是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。 针对上面的问题2和3,我们需要采取两种方式来解决:即减少map数和增加map数;
6.10.2 小文件合并
-
在map执行前合并小文件,减少map数:
-
CombineHiveInputFormat 具有对小文件进行合并的功能(系统默认的格式)
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
6.10.3 复杂文件增加Map数
-
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
-
增加map的方法为
-
根据 computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))公式
-
调整maxSize最大值。让maxSize最大值低于blocksize就可以增加map的个数。
mapreduce.input.fileinputformat.split.minsize=1 //默认值为1 mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue //默认值Long.MAXValue因此,默认情况下,切片大小=blocksize maxsize(切片最大值): 参数如果调到比blocksize小,则会让切片变小,而且就等于配置的这个参数的值。 minsize(切片最小值): 参数调的比blockSize大,则可以让切片变得比blocksize还大。
-
例如
--设置maxsize大小为10M,也就是说一个block的大小为10M set mapreduce.input.fileinputformat.split.maxsize=10485760;
-
6.10.4 合理设置Reduce数
-
1、调整reduce个数方法一
-
1)每个Reduce处理的数据量默认是256MB
set hive.exec.reducers.bytes.per.reducer=256000000;
-
2) 每个任务最大的reduce数,默认为1009
set hive.exec.reducers.max=1009;
-
3) 计算reducer数的公式
N=min(参数2,总输入数据量/参数1)
-
-
2、调整reduce个数方法二
--设置每一个job中reduce个数 set mapreduce.job.reduces=3;
-
3、reduce个数并不是越多越好
-
过多的启动和初始化reduce也会消耗时间和资源;
-
同时过多的reduce会生成很多个文件,也有可能出现小文件问题
-
五、hive sql经典面试题--级联求和
-
1、需求
访客 月份 访问次数 A 2015-01 5 A 2015-01 15 B 2015-01 5 A 2015-01 8 B 2015-01 25 A 2015-01 5 A 2015-02 4 A 2015-02 6 B 2015-02 10 B 2015-02 5 …… …… …… - 2、需要输出报表
| 访客 | 月份 | 月访问总计 | 累计访问总计 |
|---|---|---|---|
| A | 2015-01 | 33 | 33 |
| A | 2015-02 | 10 | 43 |
| ……. | ……. | ……. | ……. |
| B | 2015-01 | 30 | 30 |
| B | 2015-02 | 15 | 45 |
| ……. | ……. | ……. | ……. |
-
3、实现步骤
-
3.1 创建一个表
create table t_access_times(username string,month string,salary int) row format delimited fields terminated by ‘,‘;
-
3.2 准备数据 access.log
A,2015-01,5 A,2015-01,15 B,2015-01,5 A,2015-01,8 B,2015-01,25 A,2015-01,5 A,2015-02,4 A,2015-02,6 B,2015-02,10 B,2015-02,5
-
3.3 加载数据到表中
load data local inpath ‘/home/hadoop/access.log‘ into table t_access_times;
-
3.4 第一步,先求个用户的月总金额
select username,month,sum(salary) as salary from t_access_times group by username,month; ? +-----------+----------+---------+--+ | username | month | salary | +-----------+----------+---------+--+ | A | 2015-01 | 33 | | A | 2015-02 | 10 | | B | 2015-01 | 30 | | B | 2015-02 | 15 | +-----------+----------+---------+--+
-
3.5 第二步,将月总金额表 自己连接自己(自join)
select A.*,B.* FROM (select username,month,sum(salary) as salary from t_access_times group by username,month) A inner join (select username,month,sum(salary) as salary from t_access_times group by username,month) B on A.username=B.username where B.month <= A.month +-------------+----------+-----------+-------------+----------+-------- | a.username | a.month | a.salary | b.username | b.month | b.salary | +-------------+----------+-----------+-------------+----------+-------- | A | 2015-01 | 33 | A | 2015-01 | 33 | | A | 2015-01 | 33 | A | 2015-02 | 10 | | A | 2015-02 | 10 | A | 2015-01 | 33 | | A | 2015-02 | 10 | A | 2015-02 | 10 | | B | 2015-01 | 30 | B | 2015-01 | 30 | | B | 2015-01 | 30 | B | 2015-02 | 15 | | B | 2015-02 | 15 | B | 2015-01 | 30 | | B | 2015-02 | 15 | B | 2015-02 | 15 | +-------------+----------+-----------+-------------+----------+--------
-
3.6 第三步,从上一步的结果中进行分组查询,分组的字段是a.username a.month求月累计值: 将b.month <= a.month的所有b.salary求和即可
--最终的sql语句: ? select A.username,A.month,max(A.salary) as salary,sum(B.salary) as accumulate from (select username,month,sum(salary) as salary from t_access_times group by username,month) A inner join (select username,month,sum(salary) as salary from t_access_times group by username,month) B on A.username=B.username where B.month <= A.month group by A.username,A.month order by A.username,A.month; ? --最终结果为: +-------------+----------+---------+-------------+--+ | a.username | a.month | salary | accumulate | +-------------+----------+---------+-------------+--+ | A | 2015-01 | 33 | 33 | | A | 2015-02 | 10 | 43 | | B | 2015-01 | 30 | 30 | | B | 2015-02 | 15 | 45 | +-------------+----------+---------+-------------+--+
-
以上是关于hive基础知识四的主要内容,如果未能解决你的问题,请参考以下文章