爬取定向网页大学排名
Posted ww123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取定向网页大学排名相关的知识,希望对你有一定的参考价值。
网页链接:
http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
效果:
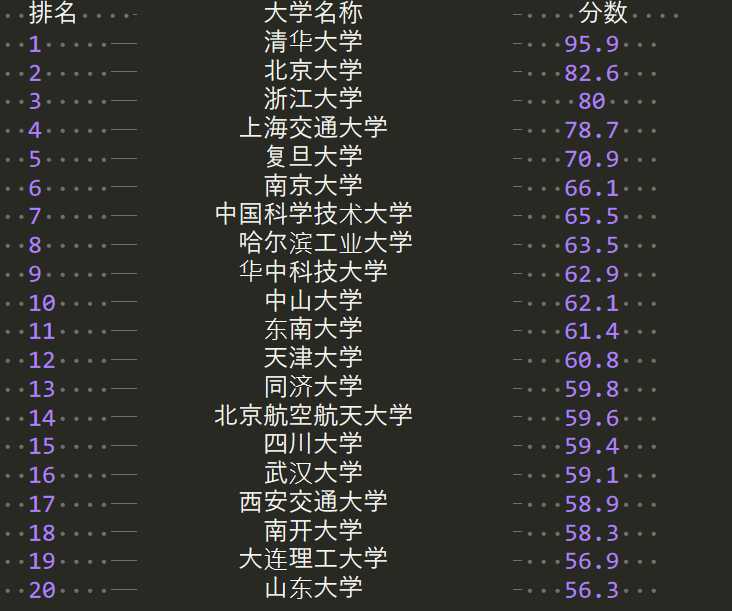
# coding=utf-8 import requests from bs4 import BeautifulSoup import bs4 def gethtml(url): try: r=requests.get(url,timeout=30) #获取请求 r.raise_for_status #请求状态 r.encoding=r.apparent_encoding #编码 return r.text except: return "" def getUnlist(unifo,html): soup=BeautifulSoup(html,"html.parser") for tr in soup.find(‘tbody‘).find_all(‘tr‘): #找到tbody内的所有tr tds=tr.find_all(‘td‘) unifo.append([tds[0].string,tds[1].string,tds[3].string]) def printUnlist(unifo,num): tplt="0:^10\\t1:3^15\\t2:^10" print(tplt.format("排名","大学名称","分数",chr(12288))) #用中文字符补全 for i in range(num): t=unifo[i] print(tplt.format(t[0],t[1],t[2],chr(12288))) def main(): url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" html=getHTML(url) unifo=[] getUnlist(unifo,html) printUnlist(unifo,20) main()
以上是关于爬取定向网页大学排名的主要内容,如果未能解决你的问题,请参考以下文章