Spark: 安装与配置
Posted momoyan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark: 安装与配置相关的知识,希望对你有一定的参考价值。
参见 HDP2.4安装(五):集群及组件安装 ,安装配置的spark版本为1.6, 在已安装HBase、hadoop集群的基础上通过 ambari 自动安装Spark集群,基于hadoop yarn 的运行模式。
目录:
- Spark集群安装
- 参数配置
- 测试验证
Spark集群安装:
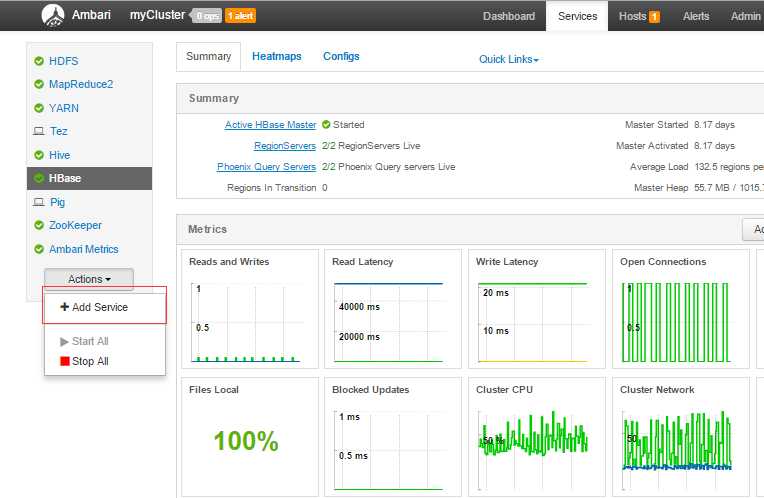
- 在ambari -service 界面选择 “add Service",如图:
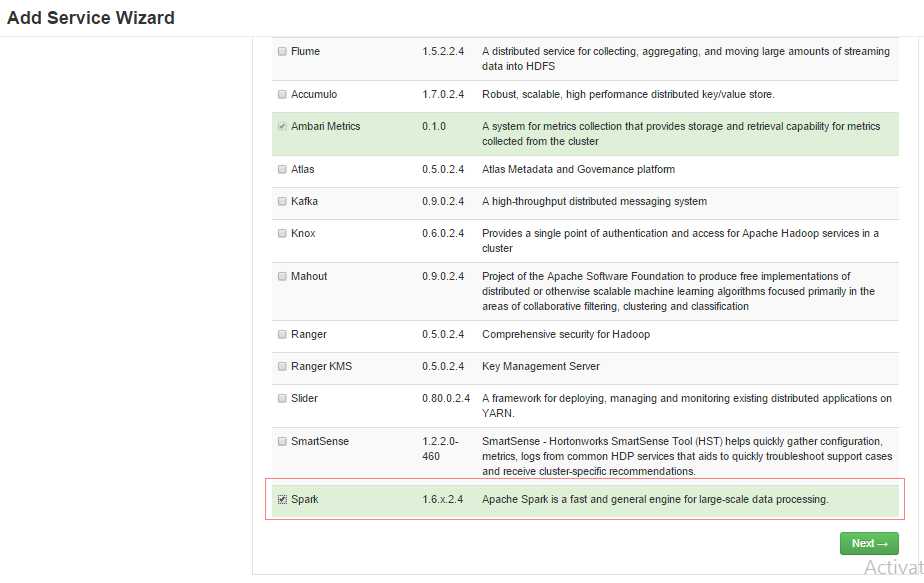
- 在弹出界面选中spark服务,如图:
- "下一步”,分配host节点,因为前期我们已经安装了hadoop 和hbase集群,按向导分配 spark history Server即可
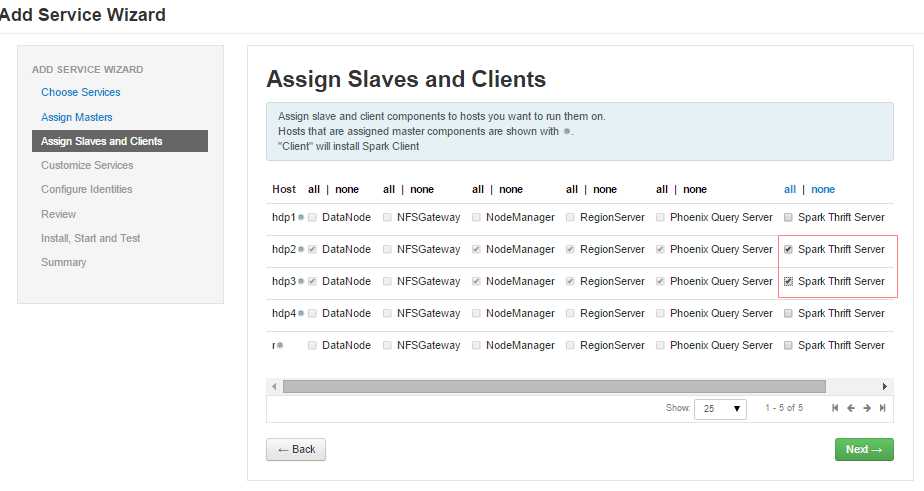
- 分配client,如下图:
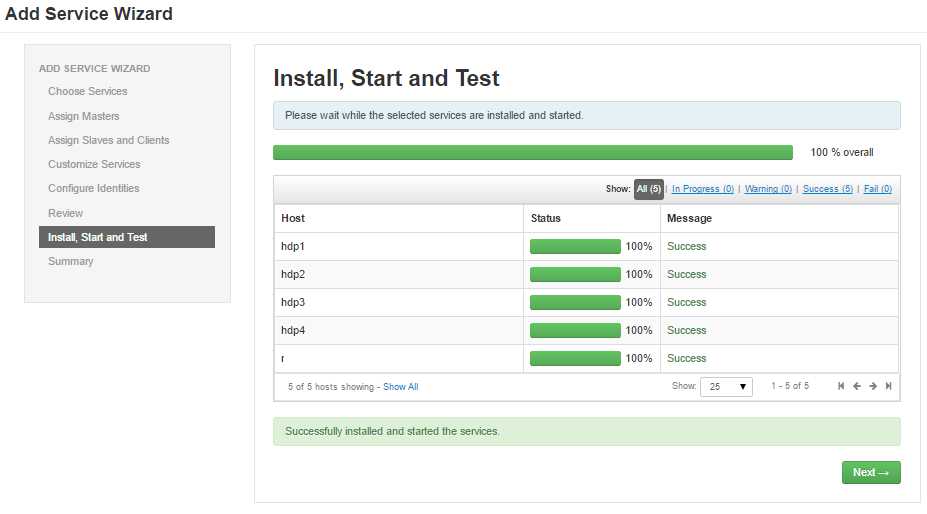
- 发布安装,如下正确状态
参数配置:
- 安装完成后,重启hdfs 和 yarn
- 查看 spark服务,spark thrift server 未正常启动,日志如下:
 View Code
View Code -
解决方案:调整yarn相关参数配置 yarn.nodemanager.resource.memory-mb、yarn.scheduler.maximum-allocation-mb
-
yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,我本机的hdp2-3内存为4G,默认设置的值是512M,调整为如下图大小
-
yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
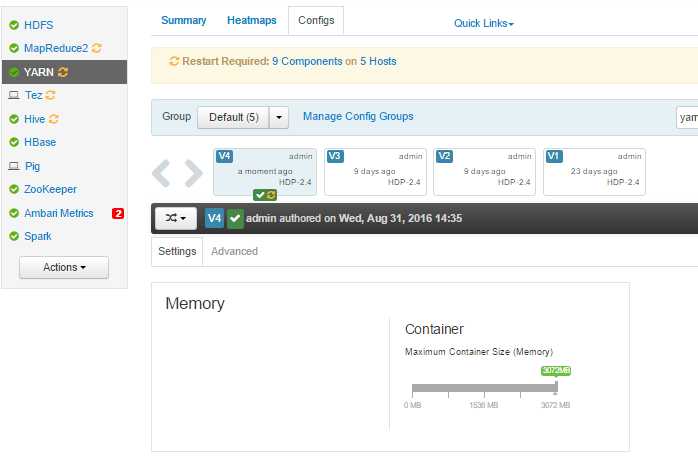
-
保存配置,重启依赖该配置的服务,正常后如下图:
-
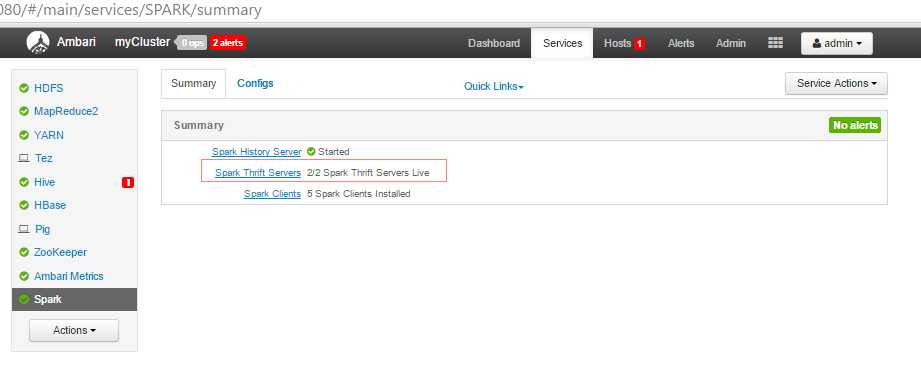
测试验证:
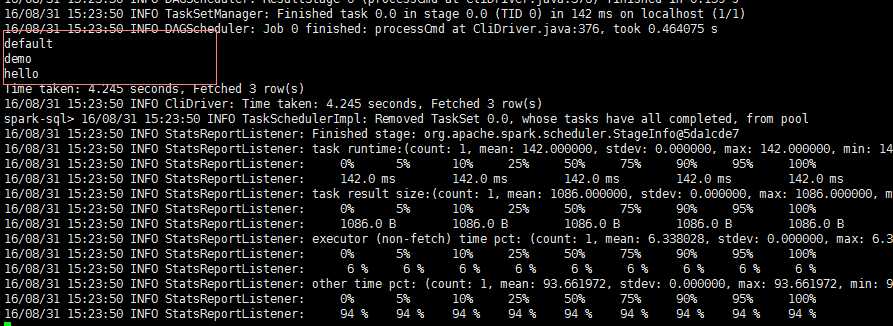
- 在任一安装spark client机器(hdp4),将目录切换至 spark 安装目录的 bin目录下
- 命令: ./spark-sql
- sql命令: show database; 如下图
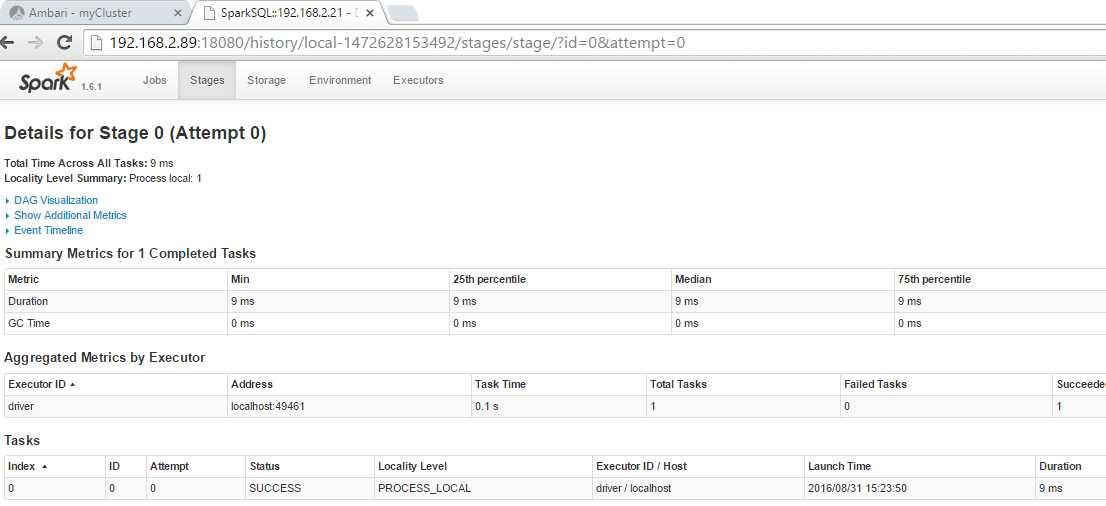
- 查看历史记录,如下:
以上是关于Spark: 安装与配置的主要内容,如果未能解决你的问题,请参考以下文章