SQL中 left join 的底层原理
Posted hider
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL中 left join 的底层原理相关的知识,希望对你有一定的参考价值。
介绍
left join的实现效果就是保留左表的全部信息,将右表往左表上拼接,如果拼不上则为NULL。
除了left join以外,还有inner join、outer join、right join等,文章不介绍其他连接的具体效果,主要讲解join的底层原理是如何实现的?具体效果是怎样呈现的?
只有懂得了底层原理,才能更好的写出性能优越的SQL脚本,提高SQL的执行速度。
join主要有3种方式,具体为:
- Nested Loop -- 嵌套循环,细分为以下3种连接方式:
- Simple Nested-Loop Join
- Index Nested-Loop Join
- Block Nested-Loop Join
- Hash Join
- Merge Join
其他概念:
驱动表(也叫外表)和被驱动表(也叫非驱动表,还可以叫匹配表,亦可叫内表),简单来说,驱动表就是主表,left join 中的左表就是驱动表,right join 中的右表是驱动表。
一个是驱动表,那另一个就只能是非驱动表,在 join 的过程中,其实就是从驱动表里面依次(注意理解这里面的依次)取出每一个值,然后去非驱动表里面进行匹配。
Simple Nested-Loop Join
Simple Nested-Loop Join是这三种方法里面最简单,最好理解,也是最符合大家认知的一种连接方式。
现在有两张表 table A和table B,我们让table A left join table B,观察是怎样进行匹配的。
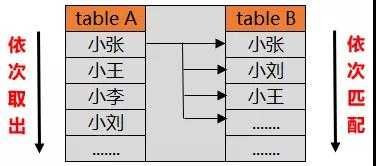
从驱动表table A中依次取出每一个值,然后去非驱动表table B中进行从上往下依次匹配,将值返回。
利用这种方式进行匹配,总共需要执行10×10=100次查询。
Index Nested-Loop Join
利用索引进行匹配,Index要求非驱动表上具有索引,有了索引以后可以减少匹配次数,提高查询效率。
数据库中索引一般采用B+树的存储结构,可以提高效率。
如果索引是主键的话,效率会更高,因为主键必须是唯一的。所以如果被驱动表是用主键去连接,只会出现多对一或者一对一的情况,而不会出现多对多和一对多的情况。
Block Nested-Loop Join
理想情况下,用索引匹配是最高效的一种方式,但是在现实工作中,并不是所有的列都是索引列,这个时候就需要用到 Block Nested-Loop Join 方法了,这种方法与第一种方法比较类似,唯一的区别就是会把驱动表中 left join 涉及到的所有列(不止是用来on的列,还有select部分的列)先取出来放到一个缓存区域,然后再去和非驱动表进行匹配,这种方法和第一种方法相比所需要的匹配次数是一样的,差别就在于驱动表的列数不同,也就是数据量的多少不同。
所以虽然匹配次数没有减少,但是总体的查询性能还是有提升的。
参考链接:SQL底层原理
以上是关于SQL中 left join 的底层原理的主要内容,如果未能解决你的问题,请参考以下文章