[论文理解] Learning Efficient Convolutional Networks through Network Slimming
Posted aoru45
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[论文理解] Learning Efficient Convolutional Networks through Network Slimming相关的知识,希望对你有一定的参考价值。
Learning Efficient Convolutional Networks through Network Slimming
简介
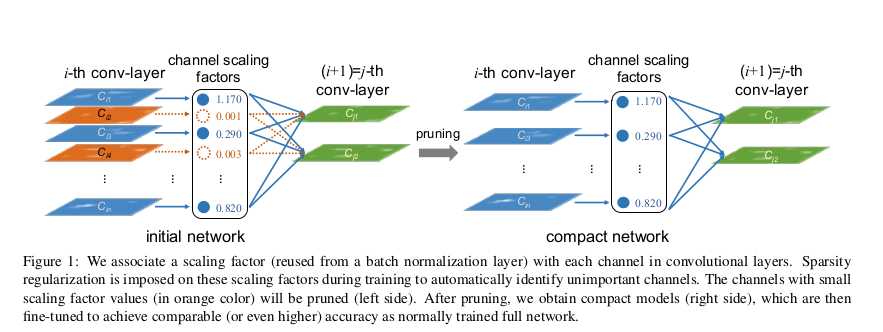
这是我看的第一篇模型压缩方面的论文,应该也算比较出名的一篇吧,因为很早就对模型压缩比较感兴趣,所以抽了个时间看了一篇,代码也自己实现了一下,觉得还是挺容易的。这篇文章就模型压缩问题提出了一种剪枝针对BN层的剪枝方法,作者通过利用BN层的权重来评估输入channel的score,通过对score进行threshold过滤到score低的channel,在连接的时候这些score太小的channel的神经元就不参与连接,然后逐层剪枝,就达到了压缩效果。
就我个人而言,现在常用的attention mechanism我认为可以用来评估channel的score可以做一做文章,但是肯定是针对特定任务而言的,后面我会自己做一做实验,利用attention机制来模型剪枝。
方法
本文的方法如图所示,即
- 给定要保留层的比例,记下所有BN层大于该比例的权重
- 对模型先进行BN层的剪枝,即丢弃小于上面权重比例的参数
- 对模型进行卷积层剪枝(因为通常是卷积层后+BN,所以知道由前后的BN层可以知道卷积层权重size),对卷积层的size做匹配前后BN的对应channel元素丢弃的剪枝。
- 对FC层进行剪枝
感觉说不太清楚,但是一看代码就全懂了。。
代码
'''
这是对vgg的剪枝例子,文章中说了对其他网络的slimming例子
'''
import os
import argparse
import numpy as np
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import datasets, transforms
from torchvision.models import vgg19
from models import *
# Prune settings
parser = argparse.ArgumentParser(description='PyTorch Slimming CIFAR prune')
parser.add_argument('--dataset', type=str, default='cifar100',
help='training dataset (default: cifar10)')
parser.add_argument('--test-batch-size', type=int, default=256, metavar='N',
help='input batch size for testing (default: 256)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--depth', type=int, default=19,
help='depth of the vgg')
parser.add_argument('--percent', type=float, default=0.5,
help='scale sparse rate (default: 0.5)')
parser.add_argument('--model', default='', type=str, metavar='PATH',
help='path to the model (default: none)')
parser.add_argument('--save', default='', type=str, metavar='PATH',
help='path to save pruned model (default: none)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
if not os.path.exists(args.save):
os.makedirs(args.save)
model = vgg19(dataset=args.dataset, depth=args.depth)
if args.cuda:
model.cuda()
if args.model:
if os.path.isfile(args.model):
print("=> loading checkpoint ''".format(args.model))
checkpoint = torch.load(args.model)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
print("=> loaded checkpoint '' (epoch ) Prec1: :f"
.format(args.model, checkpoint['epoch'], best_prec1))
else:
print("=> no checkpoint found at ''".format(args.resume))
print(model)
total = 0
for m in model.modules():# 遍历vgg的每个module
if isinstance(m, nn.BatchNorm2d): # 如果发现BN层
total += m.weight.data.shape[0] # BN层的特征数目,total就是所有BN层的特征数目总和
bn = torch.zeros(total)
index = 0
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
size = m.weight.data.shape[0]
bn[index:(index+size)] = m.weight.data.abs().clone()
index += size # 把所有BN层的权重给CLONE下来
y, i = torch.sort(bn) # 这些权重排序
thre_index = int(total * args.percent) # 要保留的数量
thre = y[thre_index] # 最小的权重值
pruned = 0
cfg = []
cfg_mask = []
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):
weight_copy = m.weight.data.abs().clone()
mask = weight_copy.gt(thre).float().cuda()# 小于权重thre的为0,大于的为1
pruned = pruned + mask.shape[0] - torch.sum(mask) # 被剪枝的权重的总数
m.weight.data.mul_(mask) # 权重对应相乘
m.bias.data.mul_(mask) # 偏置也对应相乘
cfg.append(int(torch.sum(mask))) #第几个batchnorm保留多少。
cfg_mask.append(mask.clone()) # 第几个batchnorm 保留的weight
print('layer index: :d \\t total channel: :d \\t remaining channel: :d'.
format(k, mask.shape[0], int(torch.sum(mask))))
elif isinstance(m, nn.MaxPool2d):
cfg.append('M')
pruned_ratio = pruned/total # 剪枝比例
print('Pre-processing Successful!')
# simple test model after Pre-processing prune (simple set BN scales to zeros)
def test(model):
kwargs = 'num_workers': 1, 'pin_memory': True if args.cuda else
if args.dataset == 'cifar10':
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('./data.cifar10', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
elif args.dataset == 'cifar100':
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR100('./data.cifar100', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
else:
raise ValueError("No valid dataset is given.")
model.eval()
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
print('\\nTest set: Accuracy: / (:.1f%)\\n'.format(
correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
acc = test(model)
# Make real prune
print(cfg)
newmodel = vgg(dataset=args.dataset, cfg=cfg)
if args.cuda:
newmodel.cuda()
# torch.nelement() 可以统计张量的个数
num_parameters = sum([param.nelement() for param in newmodel.parameters()]) # 元素个数,比如对于张量shape为(20,3,3,3),那么他的元素个数就是四者乘积也就是20*27 = 540
# 可以用来统计参数量 嘿嘿
savepath = os.path.join(args.save, "prune.txt")
with open(savepath, "w") as fp:
fp.write("Configuration: \\n"+str(cfg)+"\\n")
fp.write("Number of parameters: \\n"+str(num_parameters)+"\\n")
fp.write("Test accuracy: \\n"+str(acc))
layer_id_in_cfg = 0 # 第几层
start_mask = torch.ones(3)
end_mask = cfg_mask[layer_id_in_cfg] #
for [m0, m1] in zip(model.modules(), newmodel.modules()):
if isinstance(m0, nn.BatchNorm2d):
# np.where 返回的是所有满足条件的数的索引,有多少个满足条件的数就有多少个索引,绝对的索引
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy()))) # 大于0的所有数据的索引,squeeze变成向量
if idx1.size == 1: # 只有一个要变成数组的1个
idx1 = np.resize(idx1,(1,))
m1.weight.data = m0.weight.data[idx1.tolist()].clone() # 用经过剪枝的替换原来的
m1.bias.data = m0.bias.data[idx1.tolist()].clone()
m1.running_mean = m0.running_mean[idx1.tolist()].clone()
m1.running_var = m0.running_var[idx1.tolist()].clone()
layer_id_in_cfg += 1 # 下一层
start_mask = end_mask.clone() # 当前在处理的层的mask
if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC
end_mask = cfg_mask[layer_id_in_cfg]
elif isinstance(m0, nn.Conv2d): # 对卷积层进行剪枝
# 卷积后面会接bn
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: :d, Out shape :d.'.format(idx0.size, idx1.size))
if idx0.size == 1:
idx0 = np.resize(idx0, (1,))
if idx1.size == 1:
idx1 = np.resize(idx1, (1,))
w1 = m0.weight.data[:, idx0.tolist(), :, :].clone() # 这个剪枝牛B了。。
w1 = w1[idx1.tolist(), :, :, :].clone() # 最终的权重矩阵
m1.weight.data = w1.clone()
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
if idx0.size == 1:
idx0 = np.resize(idx0, (1,))
m1.weight.data = m0.weight.data[:, idx0].clone()
m1.bias.data = m0.bias.data.clone()
torch.save('cfg': cfg, 'state_dict': newmodel.state_dict(), os.path.join(args.save, 'pruned.pth.tar'))
print(newmodel)
model = newmodel
test(model)
以上是关于[论文理解] Learning Efficient Convolutional Networks through Network Slimming的主要内容,如果未能解决你的问题,请参考以下文章