Node.js开发者最常范的10个错误
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Node.js开发者最常范的10个错误相关的知识,希望对你有一定的参考价值。

目录
- 前言
- 1 不使用开发工具
- 2 阻塞event loop
- 3 频繁调用回调函数
- 4 圣诞树结构的回调(回调的地狱)
- 5 创建一个大而完整的应用程序
- 6 缺少日志
- 7 没有测试
- 8 不使用静态分析工具
- 9 没有监视与性能分析
- 10 使用console.log来debug
前言
随着一些大公司如Walmart,PayPal等开始采用Node.js,在过去的几年里,Node.js有了快速的增长。越来越多的人开始选择Node并发布modules到NPM,其发展的速度远超其它开发语言。不过对于Node的理念你可能需要一些时间去适应,尤其是那些刚从其它编程语言转型过来的开发人员。
在本文中我将谈一谈Node开发者们最常范的一些错误以及如何来避免这些错误。有关示例的源代码,你可以从github上获取到。
1 不使用开发工具
- 自动重启工具nodemon或supervisor
- 浏览器内的live reload工具(当静态资源或views视图发生改变时自动reload页面)
与其它编程语言如php或Ruby不同,当你修改了源代码后,Node需要重新启动才能使修改生效。在创建Web应用程序时还有一件事会使你放慢脚步,那就是当修改静态资源时刷新浏览器页面。当然你可以不厌其烦地手动来做这些事情,不过这里会有一些更好的解决办法。
1.1 自动重启工具
我们中的大部分人可能都是这样编写和调试代码的,在编辑器中保存代码,然后在控制台按CTRL+C键停止应用,随后通过向上键找到之前执行过的启动命令,按回车来重新启动应用。不过,通过使用下面这些工具可以自动完成应用的重启并简化开发流程:
这些工具可以监视代码文件的修改并自动重启服务。下面以nodemon为例来说说如何使用这些工具。首先通过npm进行全局安装:
npm i nodemon -g
然后,在终端通过nodemon代替node命令来启动应用:
# node server.js $ nodemon server.js 14 Nov 21:23:23 - [nodemon] v1.2.1 14 Nov 21:23:23 - [nodemon] to restart at any time, enter `rs` 14 Nov 21:23:23 - [nodemon] watching: *.* 14 Nov 21:23:23 - [nodemon] starting `node server.js` 14 Nov 21:24:14 - [nodemon] restarting due to changes... 14 Nov 21:24:14 - [nodemon] starting `node server.js`
对nodemon或node-supervisor来说,在所有已有的选项中,最牛逼的莫过于可以指定忽略的文件或文件夹。
1.2 浏览器自动刷新工具
除了上面介绍的自动重启工具外,还有其它的工具可以帮助你加快web应用程序的开发。livereload工具允许浏览器在监测到程序变动后自动刷新页面,而不用手动进行刷新。
其工作的基本原理和上面介绍的相似,只是它监测特定文件夹内的修改然后自动刷新浏览器,而不是重启整个服务。自动刷新需要依赖于在页面中注入脚本或者通过浏览器插件来实现。
这里我不去介绍如何使用livereload,相反,我将介绍如何通过Node来创建一个相似的工具,它将具有下面这些功能:
- 监视文件夹中的文件修改
- 通过server-sent events向所有已连接的客户端发送消息,并且
- 触发一个page reload
首先我们需要通过NPM来安装项目需要的所有依赖项:
- express - 创建一个示例web应用程序
- watch - 监视文件修改
- sendevent - sever-sent events (SSE),或者也可以使用websockets来实现
- uglify-js - 用于压缩客户端javascript文件
- ejs - 视图模板
接下来我将创建一个简单的Express server在前端页面中渲染home视图:
var express = require(‘express‘); var app = express(); var ejs = require(‘ejs‘); var path = require(‘path‘); var PORT = process.env.PORT || 1337; // view engine setup app.engine(‘html‘, ejs.renderFile); app.set(‘views‘, path.join(__dirname, ‘views‘)); app.set(‘view engine‘, ‘html‘); // serve an empty page that just loads the browserify bundle app.get(‘/‘, function(req, res) { res.render(‘home‘); }); app.listen(PORT); console.log(‘server started on port %s‘, PORT);
因为使用的是Express,所以我们可以将浏览器自动刷新工具做成一个Express的中间件。这个中间件会attach到SSE endpoint,并会在客户端脚本中创建一个view helper。中间件function的参数是Express的app,以及需要被监视的文件夹。于是,我们将下面的代码加到server.js中,放到view setup之前:
var reloadify = require(‘./lib/reloadify‘); reloadify(app, __dirname + ‘/views‘);
现在/views文件夹中的文件被监视。整个中间件看起来像下面这样:
var sendevent = require(‘sendevent‘); var watch = require(‘watch‘); var uglify = require(‘uglify-js‘); var fs = require(‘fs‘); var ENV = process.env.NODE_ENV || ‘development‘; // create && minify static JS code to be included in the page var polyfill = fs.readFileSync(__dirname + ‘/assets/eventsource-polyfill.js‘, ‘utf8‘); var clientScript = fs.readFileSync(__dirname + ‘/assets/client-script.js‘, ‘utf8‘); var script = uglify.minify(polyfill + clientScript, { fromString: true }).code; function reloadify(app, dir) { if (ENV !== ‘development‘) { app.locals.watchScript = ‘‘; return; } // create a middlware that handles requests to `/eventstream` var events = sendevent(‘/eventstream‘); app.use(events); watch.watchTree(dir, function (f, curr, prev) { events.broadcast({ msg: ‘reload‘ }); }); // assign the script to a local var so it‘s accessible in the view app.locals.watchScript = ‘<script>‘ + script + ‘</script>‘; } module.exports = reloadify;
你也许已经注意到了,如果运行环境没有被设置成‘development‘,那么这个中间件什么也不会做。这意味着我们不得不在产品环境中将该代码删掉。
前端JS脚本文件非常简单,它只负责监听SSE的消息并在需要的时候重新加载页面:
(function() { function subscribe(url, callback) { var source = new window.EventSource(url); source.onmessage = function(e) { callback(e.data); }; source.onerror = function(e) { if (source.readyState == window.EventSource.CLOSED) return; console.log(‘sse error‘, e); }; return source.close.bind(source); }; subscribe(‘/eventstream‘, function(data) { if (data && /reload/.test(data)) { window.location.reload(); } }); }());
文件eventsourfe-polyfill.js可以从Remy Sharp‘s polyfill for SSE找到。最后非常重要的一点是将生成的脚本通过下面的方式添加到前端页面/views/homt.html中:
... <%- watchScript %> ...
现在,当你每次对home.html页面做修改时,浏览器都将从服务器重新加载该页面(http://localhost:1337/)。
2 阻塞event loop
由于Node.js是单线程运行的,所有对event loop的阻塞都将使整个程序被阻塞。这意味着如果你有一个上千个客户端访问的web server,并且程序发生了event loop阻塞,那么所有的客户端都将处于等待状态而无法获得服务器应答。
这里有一些例子,你可能会在不经意中使用它们而产生event loop阻塞:
- 使用JSON.parse()函数解析一个非常大的json
- 尝试在后台对一个非常大的文件进行语法高亮显示(如使用Ace或者highlight.js)
- 一次性输出一个大的内容(例如从child process输出git log命令的结果)
问题是你会不经意中做了上述的事情,毕竟将一个拥有15Mb左右大小的内容输出并不会经常发生,对吗?这足以让攻击者发现并最终使你的整个服务器受到DDOS攻击而崩溃掉。
幸运的是你可以通过监视event loop的延迟来检测异常。我们可以通过一些特定的解决方案例如StrongOps来实现,或者也可以通过一些开源的modules来实现,如blocked。
这些工具的工作原理是精确地跟踪每次interval之间所花费的时间然后报告。时间差是通过这样的方式来计算的:先记录下interval过程中A点和B点的准确时间,然后用B点的时间减去A点的时间,再减去interval运行间隔的时间。
下面的例子充分说明了如何来实现这一点,它是这么做的:
- 获取当前时间和以参数传入的时间变量之间的高精度时间值(high-resolution)
- 确定在正常情况下interval的event loop的延迟时间
- 将延迟时间显示成绿色,如果超过阀值则显示为红色
- 然后看实际运行的情况,每300毫秒执行一次大的运算
下面是上述示例的源代码:
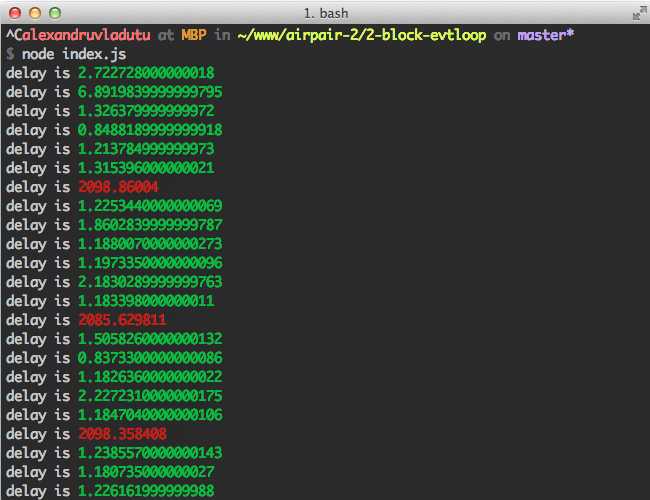
var getHrDiffTime = function(time) { // ts = [seconds, nanoseconds] var ts = process.hrtime(time); // convert seconds to miliseconds and nanoseconds to miliseconds as well return (ts[0] * 1000) + (ts[1] / 1000000); }; var outputDelay = function(interval, maxDelay) { maxDelay = maxDelay || 100; var before = process.hrtime(); setTimeout(function() { var delay = getHrDiffTime(before) - interval; if (delay < maxDelay) { console.log(‘delay is %s‘, chalk.green(delay)); } else { console.log(‘delay is %s‘, chalk.red(delay)); } outputDelay(interval, maxDelay); }, interval); }; outputDelay(300); // heavy stuff happening every 2 seconds here setInterval(function compute() { var sum = 0; for (var i = 0; i <= 999999999; i++) { sum += i * 2 - (i + 1); } }, 2000);
运行上面的代码需要安装chalk。运行之后你应该会在终端看到如下图所示的结果:
前面已经说过,开源modules也使用了相似的方式来实现对应的功能,因此可以放心使用它们:
- https://github.com/hapijs/heavy/blob/bbc98a5d7c4bddaab94d442210ca694c7cd75bde/lib/index.js#L70
- https://github.com/tj/node-blocked/blob/master/index.js#L2-L14
通过使用这种技术进行性能分析,你可以精确地找出代码中的哪部分会导致延迟。
3 频繁调用回调函数
很多时候当你保存文件然后重新启动Node web app时它就很快地崩掉了。最有可能出现的原因就是调用了两次回调函数,这意味着你很可能在第一次调用之后忘记return了。
我们创建一个例子来重现一下这种情况。我将创建一个简单的包含基本验证功能的代理server。要使用它你需要安装request这个依赖包,运行程序然后访问(如http://localhost:1337/?url=http://www.google.com/)。下面是这个例子的源代码:
var request = require(‘request‘); var http = require(‘http‘); var url = require(‘url‘); var PORT = process.env.PORT || 1337; var expression = /[[email protected]:%_\+.~#?&//=]{2,256}\.[a-z]{2,4}\b(\/[[email protected]:%_\+.~#?&//=]*)?/gi; var isUrl = new RegExp(expression); var respond = function(err, params) { var res = params.res; var body = params.body; var proxyUrl = params.proxyUrl; res.setHeader(‘Content-type‘, ‘text/html; charset=utf-8‘); if (err) { console.error(err); res.end(‘An error occured. Please make sure the domain exists.‘); } else { res.end(body); } }; http.createServer(function(req, res) { var queryParams = url.parse(req.url, true).query; var proxyUrl = queryParams.url; if (!proxyUrl || (!isUrl.test(proxyUrl))) { res.writeHead(200, { ‘Content-Type‘: ‘text/html‘ }); res.write("Please provide a correct URL param. For ex: "); res.end("<a href=‘http://localhost:1337/?url=http://www.google.com/‘>http://localhost:1337/?url=http://www.google.com/</a>"); } else { // ------------------------ // Proxying happens here // TO BE CONTINUED // ------------------------ } }).listen(PORT);
除代理本身外,上面的代码几乎包含了所有需要的部分。再仔细看看下面的内容:
request(proxyUrl, function(err, r, body) { if (err) { respond(err, { res: res, proxyUrl: proxyUrl }); } respond(null, { res: res, body: body, proxyUrl: proxyUrl }); });
在回调函数中,我们有错误处理的逻辑,但是在调用respond函数后忘记停止整个运行流程了。这意味着如果我们访问一个无法host的站点,respond函数将会被调用两次,我们会在终端收到下面的错误信息:
Error: Can‘t set headers after they are sent. at ServerResponse.OutgoingMessage.setHeader (http.js:691:11) at respond (/Users/alexandruvladutu/www/airpair-2/3-multi-callback/proxy-server.js:18:7) This can be avoided either by using the `return` statement or by wrapping the ‘success‘ callback in the `else` statement:
request(.., function(..params) { if (err) { return respond(err, ..); } respond(..); }); // OR: request(.., function(..params) { if (err) { respond(err, ..); } else { respond(..); } });
4 圣诞树结构的回调(回调的地狱)
有些人总是拿地狱般的回调参数来抨击Node,认为在Node中回调嵌套是无法避免的。但其实并非如此。这里有许多解决方法,可以使你的代码看起来非常规整:
- 使用流程控制模块如async
- 使用Promises
- 使用Generators
我们来创建一个例子,然后重构它以使用async模块。这个app是一个简单的前端资源分析工具,它完成下面这些工作:
- 检查HTML代码中有多少scripts,stylesheets,images的引用
- 将检查的结果输出到终端
- 检查每一个资源的content-length并将结果输出到终端
除async模块外,你需要安装下面这些npm包:
var URL = process.env.URL; var assert = require(‘assert‘); var url = require(‘url‘); var request = require(‘request‘); var cheerio = require(‘cheerio‘); var once = require(‘once‘); var isUrl = new RegExp(/[[email protected]:%_\+.~#?&//=]{2,256}\.[a-z]{2,4}\b(\/[[email protected]:%_\+.~#?&//=]*)?/gi); assert(isUrl.test(URL), ‘must provide a correct URL env variable‘); request({ url: URL, gzip: true }, function(err, res, body) { if (err) { throw err; } if (res.statusCode !== 200) { return console.error(‘Bad server response‘, res.statusCode); } var $ = cheerio.load(body); var resources = []; $(‘script‘).each(function(index, el) { var src = $(this).attr(‘src‘); if (src) { resources.push(src); } }); // ..... // similar code for stylesheets and images // checkout the github repo for the full version var counter = resources.length; var next = once(function(err, result) { if (err) { throw err; } var size = (result.size / 1024 / 1024).toFixed(2); console.log(‘There are ~ %s resources with a size of %s Mb.‘, result.length, size); }); var totalSize = 0; resources.forEach(function(relative) { var resourceUrl = url.resolve(URL, relative); request({ url: resourceUrl, gzip: true }, function(err, res, body) { if (err) { return next(err); } if (res.statusCode !== 200) { return next(new Error(resourceUrl + ‘ responded with a bad code ‘ + res.statusCode)); } if (res.headers[‘content-length‘]) { totalSize += parseInt(res.headers[‘content-length‘], 10); } else { totalSize += Buffer.byteLength(body, ‘utf8‘); } if (!--counter) { next(null, { length: resources.length, size: totalSize }); } }); }); });
上面的代码看起来还不是特别糟糕,不过你还可以嵌套更深的回调函数。从底部的代码中你应该能识别出什么是圣诞树结构了,其代码的缩进看起来像这个样子:
if (!--counter) { next(null, { length: resources.length, size: totalSize }); } }); }); });
要运行上面的代码,在终端输入下面的命令:
$ URL=https://bbc.co.uk/ node before.js # Sample output: # There are ~ 24 resources with a size of 0.09 Mb.
使用async进行部分重构之后,我们的代码看起来像下面这样:
var async = require(‘async‘); var rootHtml = ‘‘; var resources = []; var totalSize = 0; var handleBadResponse = function(err, url, statusCode, cb) { if (!err && (statusCode !== 200)) { err = new Error(URL + ‘ responded with a bad code ‘ + res.statusCode); } if (err) { cb(err); return true; } return false; }; async.series([ function getRootHtml(cb) { request({ url: URL, gzip: true }, function(err, res, body) { if (handleBadResponse(err, URL, res.statusCode, cb)) { return; } rootHtml = body; cb(); }); }, function aggregateResources(cb) { var $ = cheerio.load(rootHtml); $(‘script‘).each(function(index, el) { var src = $(this).attr(‘src‘); if (src) { resources.push(src); } }); // similar code for stylesheets && images; check the full source for more setImmediate(cb); }, function calculateSize(cb) { async.each(resources, function(relativeUrl, next) { var resourceUrl = url.resolve(URL, relativeUrl); request({ url: resourceUrl, gzip: true }, function(err, res, body) { if (handleBadResponse(err, resourceUrl, res.statusCode, cb)) { return; } if (res.headers[‘content-length‘]) { totalSize += parseInt(res.headers[‘content-length‘], 10); } else { totalSize += Buffer.byteLength(body, ‘utf8‘); } next(); }); }, cb); } ], function(err) { if (err) { throw err; } var size = (totalSize / 1024 / 1024).toFixed(2); console.log(‘There are ~ %s resources with a size of %s Mb.‘, resources.length, size); });
5 创建一个大而完整的应用程序
一些初入Node的开发人员往往会将其它语言的一些思维模式融入进来,从而写出不同风格的代码。例如将所有的代码写到一个文件里,而不是将它们分散到自己的模块中再发布到NPM等。
就拿我们之前的例子来说,我们将所有的内容都放在一个文件里,这使得代码很难被测试和读懂。不过别担心,我们会重构代码使其看起来漂亮并且更加模块化。当然,这也将有效地避免回调地狱。
如果我们将URL validator,response handler,request功能块以及resource处理程序抽出来放到它们自己的模块中,我们的主程序看起来会像下面这样:
// ... var handleBadResponse = require(‘./lib/bad-response-handler‘); var isValidUrl = require(‘./lib/url-validator‘); var extractResources = require(‘./lib/resource-extractor‘); var request = require(‘./lib/requester‘); // ... async.series([ function getRootHtml(cb) { request(URL, function(err, data) { if (err) { return cb(err); } rootHtml = data.body; cb(null, 123); }); }, function aggregateResources(cb) { resources = extractResources(rootHtml); setImmediate(cb); }, function calculateSize(cb) { async.each(resources, function(relativeUrl, next) { var resourceUrl = url.resolve(URL, relativeUrl); request(resourceUrl, function(err, data) { if (err) { return next(err); } if (data.res.headers[‘content-length‘]) { totalSize += parseInt(data.res.headers[‘content-length‘], 10); } else { totalSize += Buffer.byteLength(data.body, ‘utf8‘); } next(); }); }, cb); } ], function(err) { if (err) { throw err; } var size = (totalSize / 1024 / 1024).toFixed(2); console.log(‘\nThere are ~ %s resources with a size of %s Mb.‘, resources.length, size); });
而request功能块则看起来像这样:
var handleBadResponse = require(‘./bad-response-handler‘); var request = require(‘request‘); module.exports = function getSiteData(url, callback) { request({ url: url, gzip: true, // lying a bit headers: { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36‘ } }, function(err, res, body) { if (handleBadResponse(err, url, res && res.statusCode, callback)) { return; } callback(null, { body: body, res: res }); }); };
完整的例子可以从github repo中找到。
现在就简单了,代码更加易读,我们也可以开始为我们的app添加测试用例了。当然,我们还可以继续重构代码将获取response长度的功能单独分离出来放到自己的模块中。
好的一点是Node鼓励大家编写小的模块并发布到NPM。在NPM中你可以找到各种各样的模块小到如在interval间生成随机数的模块。你应当努力使你的Node应用程序模块化,功能越简单越好。
6 缺少日志
很多Node教程都会展示示例代码,并在其中不同的地方包含console.log,这给许多Node开发人员留下了一个印象,即console.log就是在Node代码中实现日志功能。
在编写Node apps代码时你应当使用一些比console.log更好的工具来实现日志功能,因为这些工具:
- 对一些大而复杂的对象不需要使用util.inspect
- 内置序列化器,如对errors,request和response对象等进行序列化
- 支持多种不同的日志源
- 可自动包含hostname,process id,application name等
- 支持不同级别的日志(如debug,info,error,fatal等)
- 一些高级功能如日志文件自动滚动等
这些功能都可以免费使用,你可以在生产环境中使用日志模块如bunyan。如果将模块安装到全局,你还可以得到一个便利的CLI开发工具。
让我们来看看它的示例程序以了解如何使用它:
var http = require(‘http‘); var bunyan = require(‘bunyan‘); var log = bunyan.createLogger({ name: ‘myserver‘, serializers: { req: bunyan.stdSerializers.req, res: bunyan.stdSerializers.res } }); var server = http.createServer(function (req, res) { log.info({ req: req }, ‘start request‘); // <-- this is the guy we‘re testing res.writeHead(200, { ‘Content-Type‘: ‘text/plain‘ }); res.end(‘Hello World\n‘); log.info({ res: res }, ‘done response‘); // <-- this is the guy we‘re testing }); server.listen(1337, ‘127.0.0.1‘, function() { log.info(‘server listening‘); var options = { port: 1337, hostname: ‘127.0.0.1‘, path: ‘/path?q=1#anchor‘, headers: { ‘X-Hi‘: ‘Mom‘ } }; var req = http.request(options, function(res) { res.resume(); res.on(‘end‘, function() { process.exit(); }) }); req.write(‘hi from the client‘); req.end(); });
在终端运行,你会看到下面的输出内容:
$ node server.js {"name":"myserver","hostname":"MBP.local","pid":14304,"level":30,"msg":"server listening","time":"2014-11-16T11:30:13.263Z","v":0} {"name":"myserver","hostname":"MBP.local","pid":14304,"level":30,"req":{"method":"GET","url":"/path?q=1#anchor","headers":{"x-hi":"Mom","host":"127.0.0.1:1337","connection":"keep-alive"},"remoteAddress":"127.0.0.1","remotePort":61580},"msg":"start request","time":"2014-11-16T11:30:13.271Z","v":0} {"name":"myserver","hostname":"MBP.local","pid":14304,"level":30,"res":{"statusCode":200,"header":"HTTP/1.1 200 OK\r\nContent-Type: text/plain\r\nDate: Sun, 16 Nov 2014 11:30:13 GMT\r\nConnection: keep-alive\r\nTransfer-Encoding: chunked\r\n\r\n"},"msg":"done response","time":"2014-11-16T11:30:13.273Z","v":0}
开发过程中可将它作为一个CLI工具来使用:
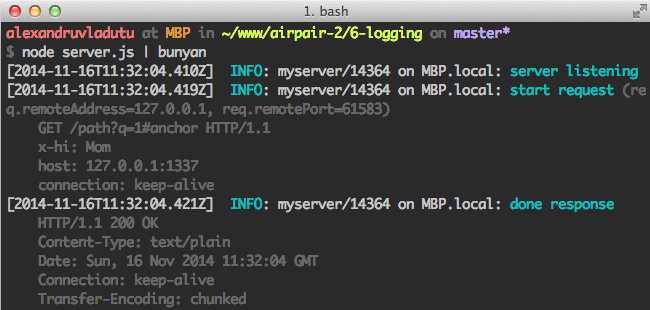
正如你所看到的,bunyan给你提供了有关当前进程的许多有用的信息,这些信息在产品环境中都十分重要。另外一个便利的功能是你可以将日志输出到一个或多个流中。
7 没有测试
没有提供测试的程序不是一个完整的程序。已经有这么多的工具可以帮助我们来进行测试,实在没有任何理由不编写测试用例了:
- 测试框架:mocha, jasmine, tape,还有许多其它框架
- Asertion(断言)模块:chai, should.js
- 模块mocks, spies, stubs或fake timers如sinon
- 代码覆盖工具:istanbul, blanket
作为NPM模块的约定,你需要在package.json中指定测试命令,如:
{ "name": "express", ... "scripts": { "test": "mocha --require test/support/env --reporter spec --bail --check-leaks test/ test/acceptance/", ... }
然后通过npm test来启动测试,你根本不用去管如何来调用测试框架。
另外一个你需要考虑的是在提交代码之前务必使所有的测试用例都通过,这只需要通过一行简单的命令就可以做到:
npm i pre-commit --save-dev
当然你也可以强制执行某个特定的code coverage级别的测试而拒绝提交那些不遵守该级别的代码。pre-commit模块作为一个pre-commit的hook程序可以自动地运行npm test。
如果你不确定如何来编写测试,可以通过一些在线教程或者在Github中看看那些流行的Node项目它们是如何做的:
8 不使用静态分析工具
为了不在生产环境中才发现问题,最好的办法是在开发过程中使用静态分析工具立即就发现这些问题。
例如,ESLint工具可以帮助我们解决许多问题:
- 可能的错误。如:禁止在条件表达式中使用赋值语句,禁止使用debugger
- 强制最佳体验。如:禁止声明多个相同名称的变量,禁止使用arguments.calle
- 找出潜在的安全问题,如使用eval()或不安全的正则表达式
- 侦测出可能存在的性能问题
- 执行一致的风格
有关ESLint更多的完整规则可以查看官方文档。如果想在实际项目中使用ESLint,你还应该看看它的配置文档。
有关如何配置ESLint,这里可以找到一些例子。
如果你想解析AST(抽象源树或抽象语法树)并自己创建静态分析工具,可以参考Esprima或Acorn。
9 没有监视与性能分析
如果Node应用程序没有监视与性能分析,你将对其运行情况一无所知。一些很重要的东西如event loop延迟,CPU负载,系统负载或内存使用量等你将无法得知。
这里有一些特定的服务可以帮助到你,可以从New Relic, StrongLoop以及Concurix, AppDynamics等了解到。
你也可以通过开源模块如look或结合不同的NPM包自己来实现。不管选择哪种方式,你都要确保始终都能监测到你的程序的运行状态,否则你可能会在半夜收到各种诡异的电话告诉你程序又出现这样或那样的问题。
10 使用console.log来debug
一旦程序出现错误,你可以简单地在代码中插入console.log来进行debug。问题解决之后删除console.log调试语句再继续。
问题是其他的开发人员(甚至是你自己)可能还会遇到一样的问题而再重复上面的操作。这就是为什么调试模块如debug存在的原因。你可以在代码中使用debug function来代替console.log语句,而且在调试完之后不用删除它们。
其他开发人员如果遇到问题需要调试代码,只需要通过DEBUG环境变量来启动程序即可。
这个小的module具有以下优点:
- 除非你通过DEBUG环境变量启动程序,否则它不会在控制台输出任何内容。
- 你可以有选择地对代码中的一部分进行调试(甚至可以通过通配符来指定内容)。
- 终端的输出内容有各种不同的颜色,看起来很舒服。
来看看官方给出的示例:
// app.js var debug = require(‘debug‘)(‘http‘) , http = require(‘http‘) , name = ‘My App‘; // fake app debug(‘booting %s‘, name); http.createServer(function(req, res){ debug(req.method + ‘ ‘ + req.url); res.end(‘hello\n‘); }).listen(3000, function(){ debug(‘listening‘); }); // fake worker of some kind require(‘./worker‘); <!--code lang=javascript linenums=true--> // worker.js var debug = require(‘debug‘)(‘worker‘); setInterval(function(){ debug(‘doing some work‘); }, 1000);
如果以node app.js来启动程序,不会输出任何内容。但是如果启动的时候带着DEBUG标记,那么:
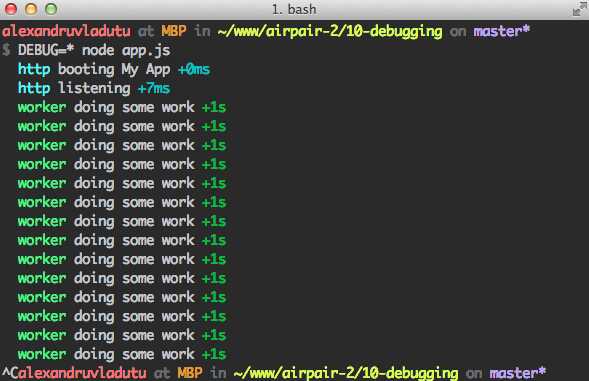
除了在应用程序中使用它们,你还可以在一些小的modules中使用它并发布到NPM。与其它一些复杂的logger不同,它只负责debugging而且还很好使。
原文地址:https://www.airpair.com/node.js/posts/top-10-mistakes-node-developers-make
以上是关于Node.js开发者最常范的10个错误的主要内容,如果未能解决你的问题,请参考以下文章