XCTF-web的writeup(1--4)
Posted helloctf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XCTF-web的writeup(1--4)相关的知识,希望对你有一定的参考价值。
1.view source
考点:view source 协议。该协议用于查看页面的源代码。早期基本上每个浏览器都支持这个协议。后来Microsoft考虑安全性,对于WindowsXP pack2以及更高版本以后IE就不再支持此协议。但是这个方法在FireFox和Chrome浏览器都还可以使用。 如果要在IE下查看源代码,只能使用查看中的"查看源代码"命令.
使用方法:1、在浏览器地址栏里输入:view souce:url
2、javascirpt用法:Window.location="view source:"+window.location
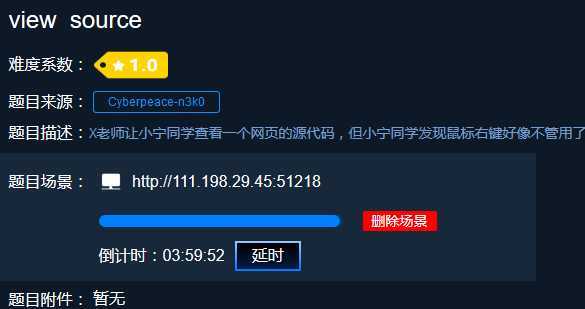
过程:我们在题目给出的地址前添加view source,即view-source:http://111.198.29.45:51218/即可得到flag
另一种方法:查看器查看页面源代码
知识盲区:为什么Microsoft不支持view-source协议。
2、get_post
考点:http中get和post两种提交方法。在客户机-服务器模式中最常用到两种提交方式,get从指定的资源中请求数据,post向指定的资源提交需要处理的数据,具体的知识点参见w3school. 友情链接:https://www.w3school.com.cn/tags/html_ref_httpmethods.asp
过程:1、查看题目给出的地址。
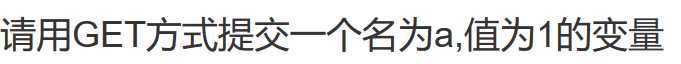
2、这里我们需要了解get提交的方式 -----> 网址?参数名=值&参数名=值,更为详细的知识参见https://zhidao.baidu.com/question/589265587.html


3、按照get的提交方式提交之后有提示需要使用Post的方法提交。post不同于get方法,为保证数据的私密性无法直接在地址栏填写参数,这里需要用到firefox的扩展插件hackbar
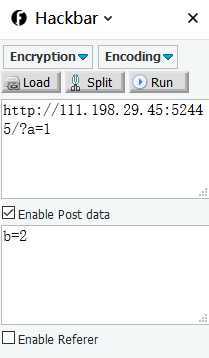
4、输入参数之后点击run 即可得到flag

知识盲区:1、get和post的区别。2、插件hackbar的使用。3、http协议
3、robots
考点:爬虫协议(robots协议)是网站和搜索引擎之间的协议,用来防止搜索引擎爬取那些不想被索引的页面或内容。禁止爬取的内容都被写在了robots.txt里面,robots.txt文件也是搜索引擎访问的第一个文件,更为详细的知识参见:https://www.xuewangzhan.net/zichu/483.html
过程:1、访问robots.txt文件
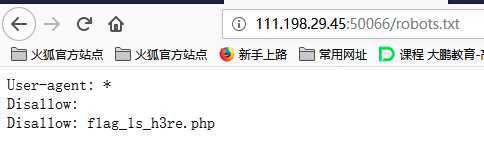
2、我们看到disallow里面有个php文件,在robots.txt文件里disallow代表着不能被爬取得内容,我们访问这个PHP文件。

知识盲区:1、什么是robots协议、2、robots协议的写法与属性。3、爬虫的基本知识
4、backup
考点:常见的文件扩展名。
过程:1、输入题目给出的地址。
2、按照我们常见的备份方法输入111.198.29.45:48995/index.php.bak,得到一份文件,打开得到flag
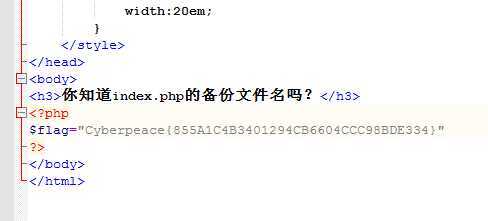
知识盲区:1、文件扩展名。
以上是关于XCTF-web的writeup(1--4)的主要内容,如果未能解决你的问题,请参考以下文章
xctf-WEB-新手练习区Exercise area-Writeup