解释器模式(Interpreter)
Posted epsilon1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解释器模式(Interpreter)相关的知识,希望对你有一定的参考价值。
一、模式动机
如果在系统中某一特定类型的问题发生的频率很高,此时可以考虑将这些问题的实例表述为一个语言中的句子,因此可以构建一个解释器,该解释器通过解释这些句子来解决这些问题。
解释器模式描述了如何构成一个简单的语言解释器,主要应用在使用面向对象语言开发的编译器中。
二、模式定义
解释器模式(Interpreter Pattern) :定义语言的文法,并且建立一个解释器来解释该语言中的句子,这里的“语言”意思是使用规定格式和语法的代码,它是一种类行为型模式。
三、模式结构
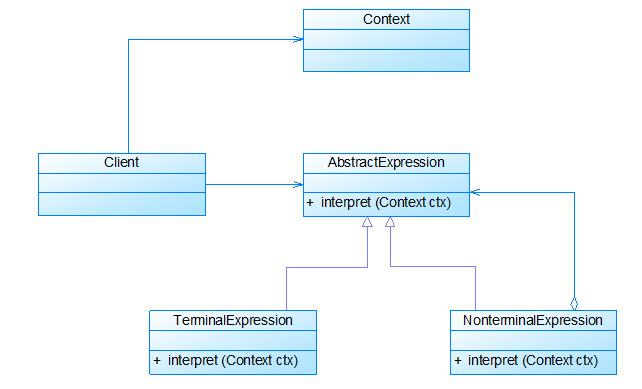
四、参与者
- AbstractExpression: 抽象表达式
- TerminalExpression: 终结符表达式
- NonterminalExpression: 非终结符表达式
- Context: 环境类
- Client: 客户类
五、示例代码
设计与实现一个四则算术运算解释器
- 可以分析任意+、-、*、/表达式,并计算其数值
- 输入表达式为一个字符串表达式
- 输出结果为双精度浮点数(Double)
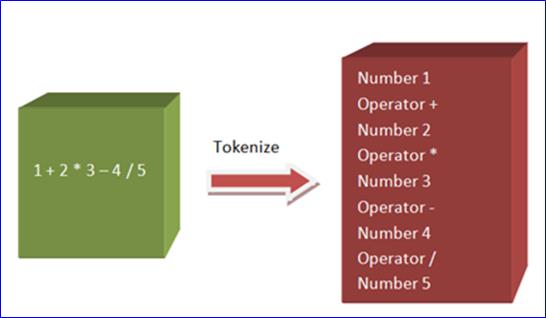
输入是一个用字符串表达的四则运算,比如 1 + 2 * 3 。目的是试图去理解这个字符串表达的运算指令,然后计算出结果 7。之所以是一个解释器 Interpreter,而不是一个编译器 Compiler,是因为程序是去理解指令并且执行指令,而不是把指令编译成机器代码来运行;后者是编译器的目标。
第一个部分,是截取输入字符串,然后返回单元指令。比如,对于指令 1 + 2 * 3 – 4 / 5,就需要被分解成如下所示的单元指令集:
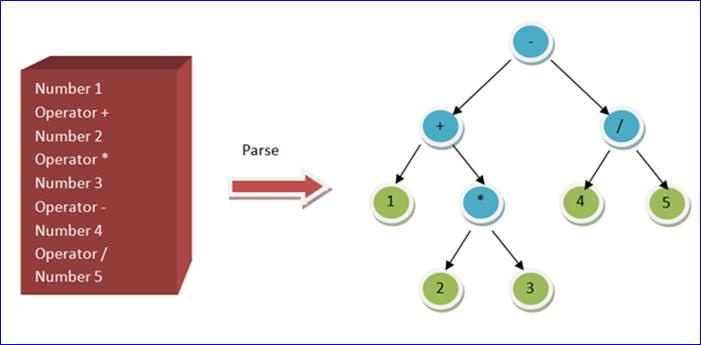
第二个部分,把单元指令集组成一个树结构,称之为Abstract Syntax Tree。按照将来需要解释的顺序,优先执行的指令放在树的叶的位置,最后执行的指令是树根Root。
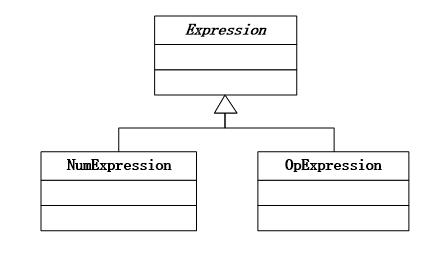
程序只有 2 种单元指令:操作数 NumExpression 和 运算符 OpExpression 。
定义了一个抽象类,叫做 Expression,然后NumExpression和 OpExpression 继承了该抽象类。
- 源代码
package design.pattern;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Scanner;
/**
* 运算符枚举类
*
* @author Administrator
*
*/
enum Op {
Plus('+'), Minus('-'), Multiply('*'), Divide('/');
char value;
Op(char value) {
this.value = value;
}
static Op getValue(char ch) {
switch (ch) {
case '+':
return Plus;
case '-':
return Minus;
case '*':
return Multiply;
case '/':
return Divide;
default:
return null;
}
}
}
/**
* 运算符优先级枚举类
*
* @author Administrator
*
*/
enum Prioirty {
Lv2(2), Lv1(1), Lv0(0);
int value;
Prioirty(int value) {
this.value = value;
}
int getValue() {
return value;
}
}
/**
* 抽象表达式
*
* @author Administrator
*
*/
abstract class Expression {
abstract public double interpreter(Syntax root);
}
/**
* 操作数表达式
*
* @author Administrator
*
*/
class NumExpression extends Expression {
private double value;
public NumExpression(double value) {
this.value = value;
}
public double getValue() {
return value;
}
public double interpreter(Syntax root) {
return ((NumExpression) (root.getExpression())).getValue();
}
public String toString() {
return String.valueOf(value);
}
}
/**
* 运算符表达式
*
* @author Administrator
*
*/
class OpExpression extends Expression {
private Op value;
public OpExpression() {
}
public OpExpression(Op value) {
this.value = value;
}
public Op getValue() {
return value;
}
public Prioirty getPrioirty() {
switch (this.value) {
case Plus:
case Minus:
return Prioirty.Lv1;
case Multiply:
case Divide:
return Prioirty.Lv2;
default:
return Prioirty.Lv0;
}
}
public double interpreter(Syntax root) {
double lvalue, rvalue;
if (root.getLeft() == null)
lvalue = 0;
else
lvalue = ((Expression) root.getLeft().getExpression()).interpreter(root.getLeft());
if (root.getRight() == null)
rvalue = 0;
else
rvalue = ((Expression) root.getRight().getExpression()).interpreter(root.getRight());
switch (((OpExpression) root.getExpression()).getValue()) {
case Plus:
return lvalue + rvalue;
case Minus:
return lvalue - rvalue;
case Multiply:
return lvalue * rvalue;
case Divide:
return lvalue / rvalue;
default:
return 0;
}
}
public String toString() {
return value.toString();
}
}
/**
* 解释器
*
* @author Administrator
*
*/
public class Interpreter {
private Expressionizer expressionizer = new Expressionizer();
public SyntaxTree eval(String expr) {
ArrayList<Expression> expressions = expressionizer.parse(expr);
SyntaxTree astree = new SyntaxTree();
for (Expression e : expressions) {
astree.append(e);
}
return astree;
}
public static void main(String[] args) {
System.out.println("请输入表达式");
Scanner scanner = new Scanner(System.in);
String exp = scanner.nextLine();
scanner.close();
Interpreter interpreter = new Interpreter();
// 构建语法树
SyntaxTree context = interpreter.eval(exp);
Expression EXP = new OpExpression();
// 解释语法树
double result = EXP.interpreter(context.getRoot());
System.out.println(result);
}
}
/**
* 语法树节点类
*
* @author Administrator
*
*/
class Syntax {
private Expression expression;
private Syntax left;
private Syntax right;
public Syntax(Expression Expression) {
this.expression = Expression;
this.left = null;
this.right = null;
}
public Expression getExpression() {
return expression;
}
public Syntax getLeft() {
return left;
}
public void setLeft(Syntax value) {
this.left = value;
}
public Syntax getRight() {
return right;
}
public void setRight(Syntax value) {
this.right = value;
}
}
class SyntaxTree {
private Syntax root;
private int count;
public SyntaxTree() {
this.root = null;
this.count = 0;
}
public Syntax getRoot() {
return root;
}
public int getCount() {
return count;
}
public void append(Expression expression) {
this.root = this.append(this.root, expression);
this.count++;
}
/**
* 添加表达式节点到语法树root中
*
* @param root
* 语法树根节点
* @param expression
* 表达式
* @return 语法树新的根节点
*/
private Syntax append(Syntax root, Expression expression) {
// 第一次添加节点
if (root == null) {
Syntax newNode = new Syntax(expression);
root = newNode;
return root;
}
// 添加操作数
if (expression instanceof NumExpression) {
// 如果根节点为运算符,则把操作数添加到右端,否则忽略
if (root.getExpression() instanceof OpExpression) {
// 如果右子树为空则直接添加为右节点
if (root.getRight() == null) {
Syntax newNode = new Syntax(expression);
root.setRight(newNode);
return root;
} else {
// 右子树不为空,作为新的语法树继续添加
root.setRight(this.append(root.getRight(), expression));
return root;
}
}
// 添加运算符
} else if (expression instanceof OpExpression) {
// 如果根节点为操作数,则新的运算符为根节点,操作数加到左端
if (root.getExpression() instanceof NumExpression) {
Syntax newRoot = new Syntax(expression);
newRoot.setLeft(root);
root = newRoot;
return newRoot;
// 如果根节点为运算符,则根据优先级添加新的运算符到语法树
} else if (root.getExpression() instanceof OpExpression) {
OpExpression expression1 = (OpExpression) expression;
OpExpression expression2 = (OpExpression) root.getExpression();
// 新的运算符优先级低于根节点,则将新运算符作为根节点,旧的根加到左端
if (expression1.getPrioirty().getValue() <= expression2.getPrioirty().getValue()) {
Syntax newRoot = new Syntax(expression1);
newRoot.setLeft(root);
root = newRoot;
return newRoot;
} else {
// 新的运算符优先级高于根节点,需要优先运算,则添加到根节点的右子树
root.setRight(append(root.getRight(), expression));
return root;
}
}
}
return root;
}
}
class Expressionizer {
private static Character[] Ops = { '+', '-', '*', '/' };
// private static Character[] Spaces = { ' ', '\\0', '\\t', '\\n', '\\r' };
String getStringRepresentation(ArrayList<Character> list) {
StringBuilder builder = new StringBuilder(list.size());
for (Character ch : list) {
builder.append(ch);
}
return builder.toString();
}
/**
* 将字符串转化为表达式序列
*
*/
public ArrayList<Expression> parse(String value) {
ArrayList<Expression> list = new ArrayList<Expression>();
ArrayList<Character> buff = new ArrayList<>();
for (int i = 0; i < value.length(); i++) {
char ch = value.charAt(i);
if (ch >= '0' && ch <= '9') {
buff.add(ch);
} else if (ch == '.') {
buff.add('.');
} else {
OpExpression expression = null;
// 查找运算符是否在Ops表中
if (Arrays.asList(Ops).indexOf(ch) >= 0) {
expression = new OpExpression(Op.getValue(ch));
}
// 当前表达式为运算符,则buff中存放的数字字符序列为一个单独的操作数
if (buff.size() > 0) {
double num = Double.parseDouble(getStringRepresentation(buff));
Expression expression1 = new NumExpression(num);
list.add(expression1);
buff.clear();
}
if (expression != null) {
list.add(expression);
}
}
}
// 最后留下的一个数字
if (buff.size() > 0) {
double num = Double.parseDouble(getStringRepresentation(buff));
Expression Expression1 = new NumExpression(num);
list.add(Expression1);
buff.clear();
}
// for (Expression c : list)
// System.out.println(c);
return list;
}
}
- 分析
从最简单的情况开始考虑:分析 1 + 2 + 3 + 4
首先,AST 树是空的, Root = NULL。
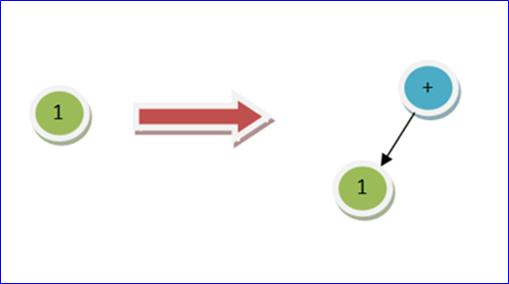
当把 NumExpression 1 插入树的时候,设置该 Expression 为根。
当把 OpExpression + 插入树的时候,需要挪动把 + 设置成根:
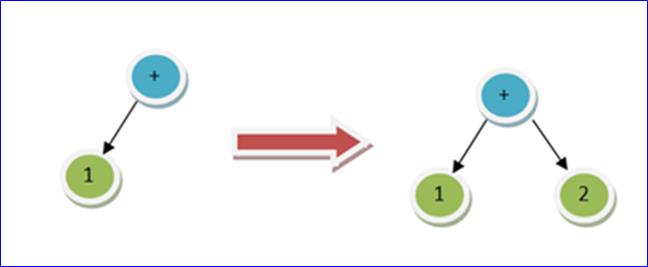
当把 NumExpression 2 插入树的时候,就把数字 2 插入树的右侧:
当把 OpExpression + 插入树的时候(同级别的操作符,顺序是左到右),我们就需要把最新的 OpExpression 设置成根,当前树设置成新根的左侧:
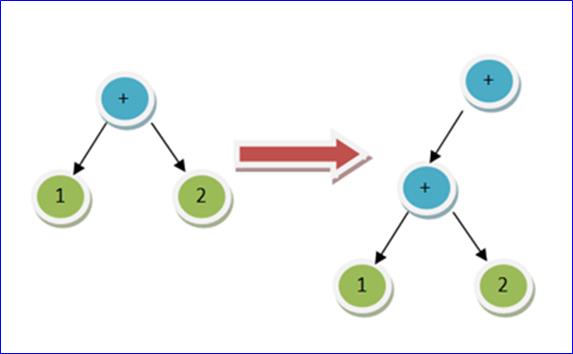
我们可以得出一个很重要的法则:插入一个新的操作符进入 AST 树的时候,若是树的根是一个操作符,并且和此新操作符同级,运算顺序是由左至右的话,那么新的操作符会成为新的树的根,现有的树会成为新树的左子树。
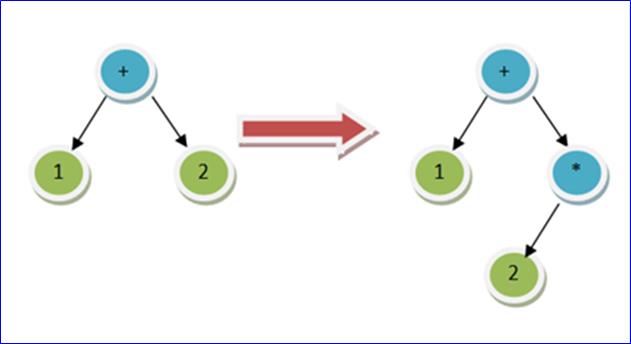
假设要插入的操作符不是 +,而是一个优先权比较高的 * 呢?也就是,若是 1 + 2 * 3 的话,AST 会是什么样子?
这种情况下,乘法运算符必须移动到树的右子树上,并且成为右子树的根。原右子树会成为新的右子树的左子树。
六、模式分析
解释器模式描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子。
文法规则实例
expression ::= value | symbol
symbol ::= expression ‘+’ expression | expression ‘-‘
value ::= an integer //一个整数值
在文法规则定义中可以使用一些符号来表示不同的含义,如使用“|”表示或,使用“{”和“}”表示组合,使用“*”表示出现0次或多次等。抽象语法树
除了使用文法规则来定义一个语言,在解释器模式中还可以通过一种称之为抽象语法树(Abstract Syntax Tree, AST)的图形方式来直观地表示语言的构成,每一棵抽象语法树对应一个语言实例。
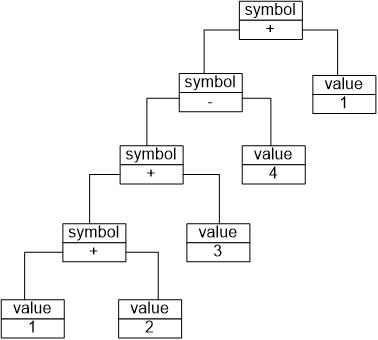
抽象语法树描述了如何构成一个复杂的句子,通过对抽象语法树的分析,可以识别出语言中的终结符和非终结符类。
在解释器模式中,每一种终结符和非终结符都有一个具体类与之对应,正因为使用类来表示每一个语法规则,使得系统具有较好的扩展性和灵活性。
优点
- 易于改变和扩展文法。
- 易于实现文法。
- 增加了新的解释表达式的方式。
缺点
- 对于复杂文法难以维护。
- 执行效率较低。
- 应用场景很有限。
模式使用
- 可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
- 一些重复出现的问题可以用一种简单的语言来进行表达。
- 文法较为简单。
- 效率不是关键问题。
模式应用
- 解释器模式在使用面向对象语言实现的编译器中得到了广泛的应用,如Smalltalk语言的编译器。
- 目前有一些基于Java抽象语法树的源代码处理工具,如在Eclipse中就提供了Eclipse AST,它是Eclipse JDT的一个重要组成部分,用来表示Java语言的语法结构,用户可以通过扩展其功能,创建自己的文法规则。
- 可以使用解释器模式,通过C++、Java、C#等面向对象语言开发简单的编译器,如数学表达式解析器、正则表达式解析器等,用于增强这些语言的功能,使之增加一些新的文法规则,用于解释一些特定类型的语句。
- 在实际项目开发中如果需要解析数学公式,无须再运用解释器模式进行设计,可以直接使用一些第三方解析工具包,它们可以统称为数学表达式解析器(Math Expression Parser, MEP),如Expression4J、Jep、JbcParser、Symja、Math Expression String Parser(MESP)等来取代解释器模式,它们可以方便地解释一些较为复杂的文法,功能强大,且使用简单,效率较好。
七、模式总结
解释器模式定义语言的文法,并且建立一个解释器来解释该语言中的句子,这里的“语言”意思是使用规定格式和语法的代码,它是一种类行为型模式。
解释器模式主要包含如下四个角色
- 在抽象表达式中声明了抽象的解释操作,它是所有的终结符表达式和非终结符表达式的公共父类;
- 终结符表达式是抽象表达式的子类,它实现了与文法中的终结符相关联的解释操作;
- 非终结符表达式也是抽象表达式的子类,它实现了文法中非终结符的解释操作;
- 环境类又称为上下文类,它用于存储解释器之外的一些全局信息。
对于一个简单的语言可以使用一些文法规则来进行定义,还可以通过抽象语法树的图形方式来直观地表示语言的构成,每一棵抽象语法树对应一个语言实例。
解释器模式的主要优点
- 易于改变和扩展文法
- 易于实现文法并增加了新的解释表达式的方式
其主要缺点是对于复杂文法难以维护,执行效率较低且应用场景很有限。
解释器模式适用情况包括
- 可以将一个需要解释执行的语言中的句子表示为一个抽象语法树;
- 一些重复出现的问题可以用一种简单的语言来进行表达;
- 文法较为简单且效率不是关键问题。
以上是关于解释器模式(Interpreter)的主要内容,如果未能解决你的问题,请参考以下文章
设计模式---领域规则模式之解析器模式(Interpreter)