充气娃娃什么感觉?
Posted huiyichanmian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了充气娃娃什么感觉?相关的知识,希望对你有一定的参考价值。
ps:本文参考“裸睡的猪”公众号。
本文中所用的到第三方库有:
requests jieba numpy Pillow wordcloud matplotlib
前言:
基于很多人没有体验过充气娃娃是什么感觉,但是又很好奇,所以希望通过爬虫+数据分析的方式直观而真实的告诉大家(下图为成品图)

一、技术方案
1、分析狗东评论数据的请求url
2、使用requests库来抓取评论内容
3、使用词云做数据展示
二、技术实现
1、分析并获取商品评论的接口
第一步:打开狗东的商品页,搜索你想研究的商品。我们这里直接搜索“充气娃娃”,然后进入第一个店铺。
第二步:我们在页面中鼠标右键选择检查(或F12)调出浏览器的调试窗口。
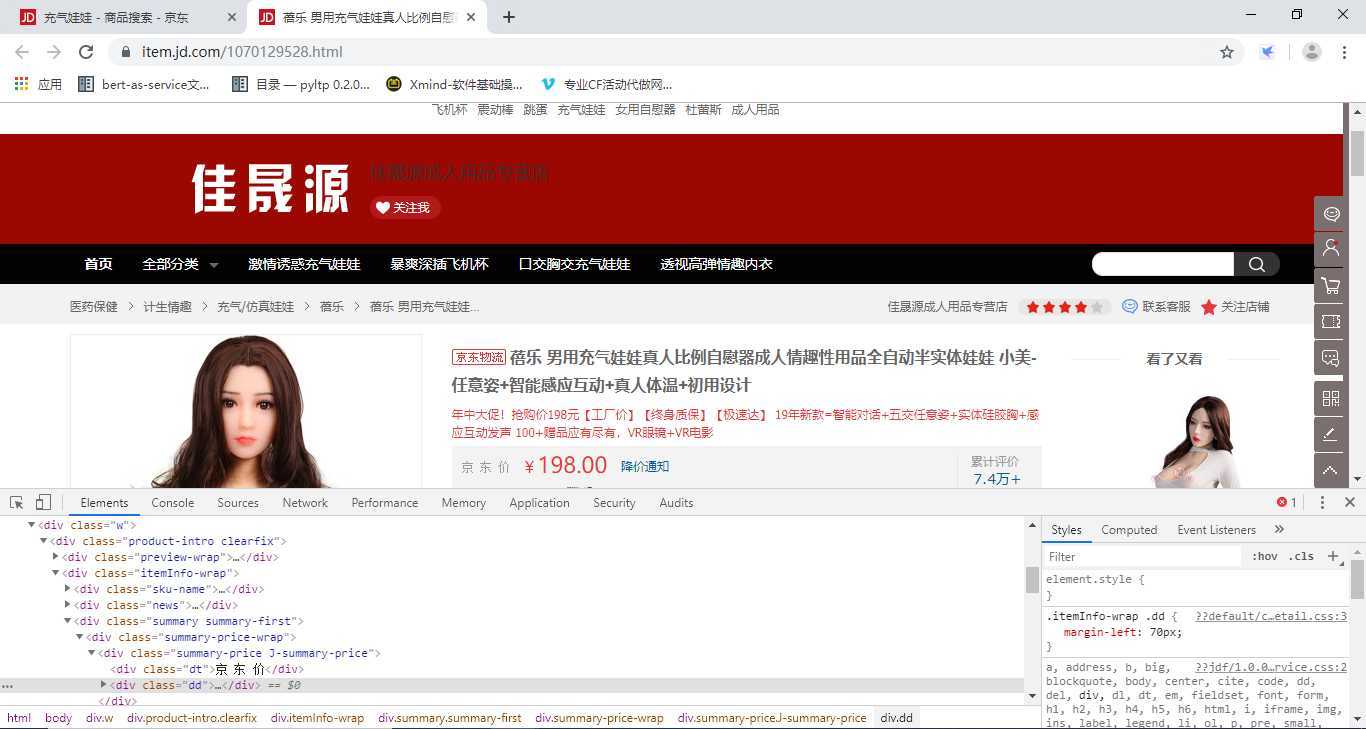
第三步:调出浏览器后点击评论按钮使其加载数据,然后我们点击network查看数据。
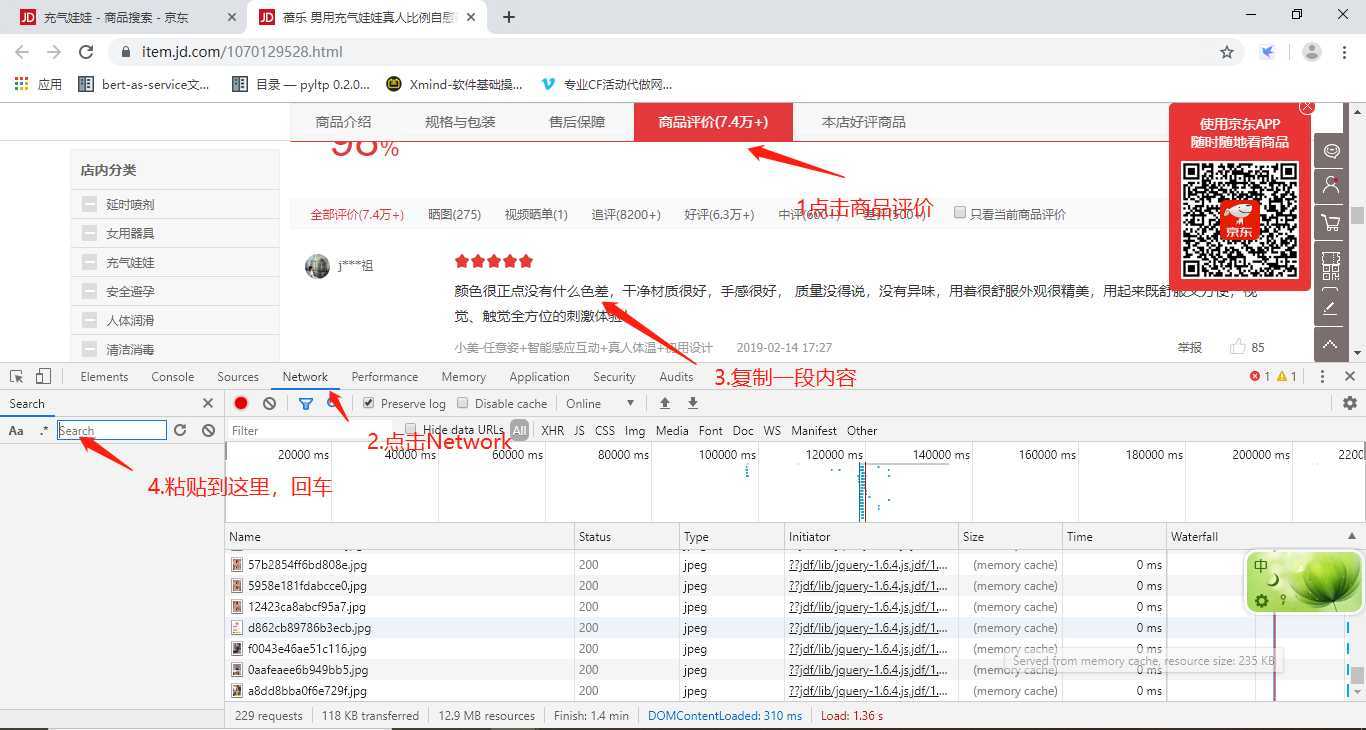
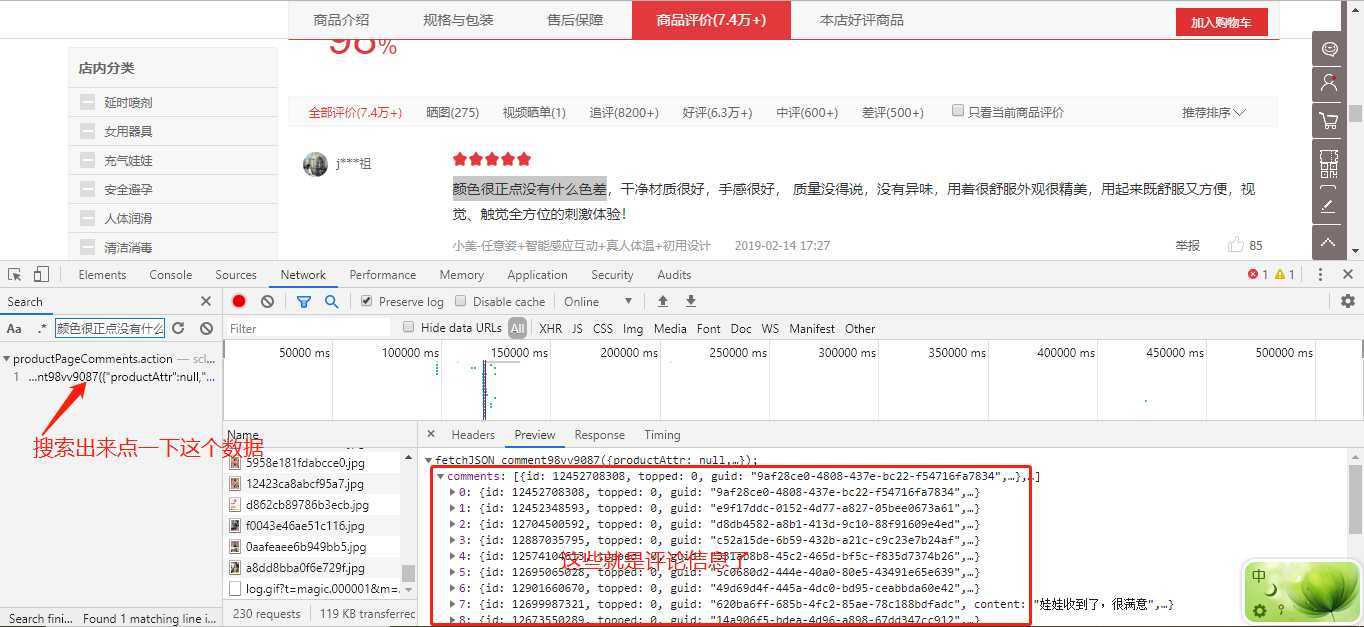
第四部:点击Headers,获取评论的接口
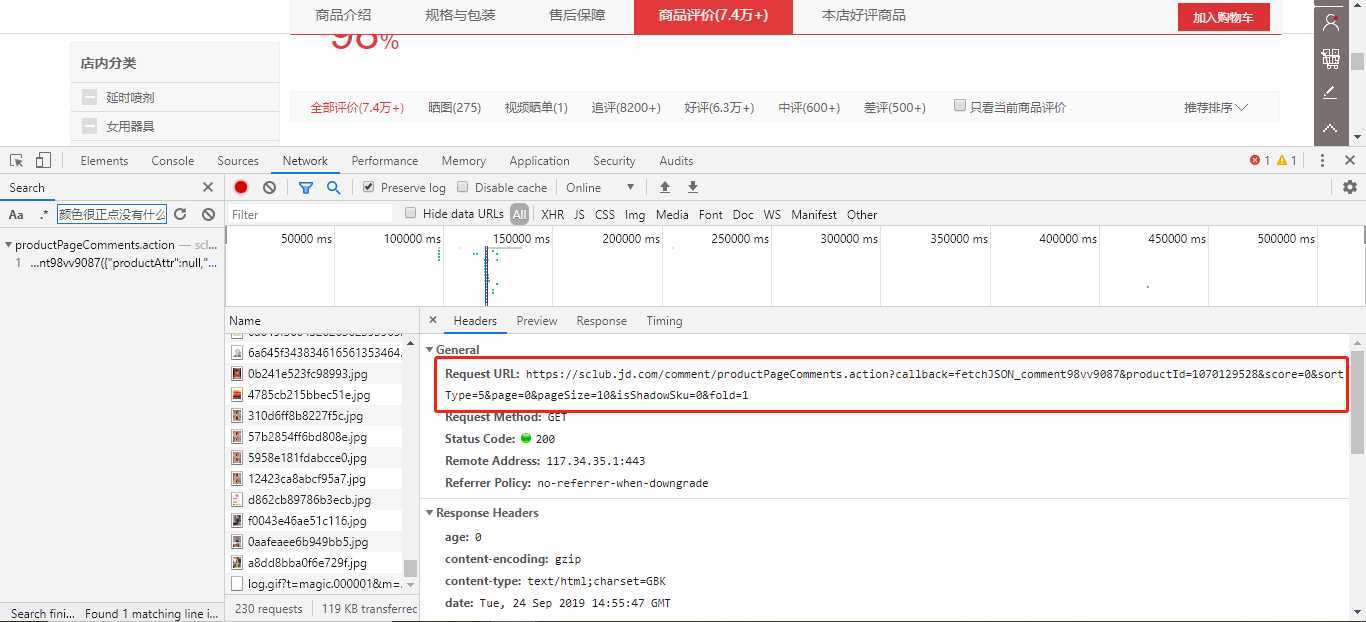
经过上面的步骤,我们就轻松的获取到了评论的请求接口。
2、爬取数据
拿到评论数据接口url之后,我们就可以开始写代码抓取数据了。一般我们会先尝试抓取一条数据,成功之后,我们再去分析如何实现大量抓取。
import requests def spider_comment(): """爬取狗东评论数据""" kv = ‘Referer‘: ‘https://item.jd.com/1070129528.html‘, ‘Sec-Fetch-Mode‘: ‘no-cors‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36‘ url = ‘https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv9087&productId=1070129528&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1‘ try: result = requests.get(url, headers=kv) result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except print(result.text) except Exception as e: print(e) if __name__ == ‘__main__‘: spider_comment()
获取到如图数据:

3、数据提取
我们对爬取的数据分析发现,此数据为jsonp跨域请求返回的json结果,所以我们只要把前面的fetchJSON_comment98vv9087(和最后的)去掉就拿到json数据了。
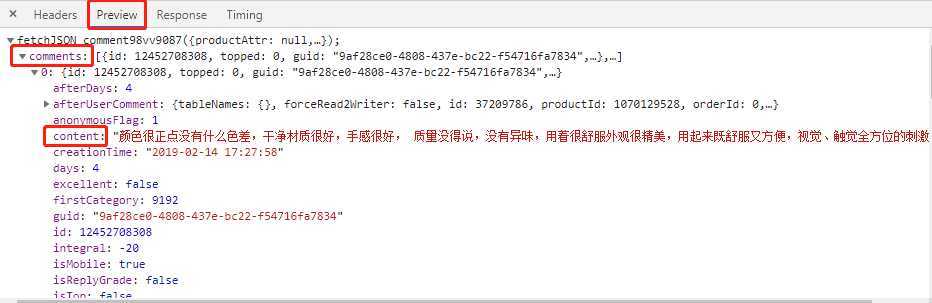
将json数据复制到json格式化工具中或者在Chrome浏览器调试窗口点击Preview也可以看到,json数据中有一个key为comments的值便是我们想要的评论数据。
我们再对comments值进行分析发现是一个有多条数据的列表,而列表里的每一项就是每个评论对象,包含了评论的内容,时间,id,评价来源等等信息,而其中的content字段便是我们在页面看到的用户评价内容。
import json import requests def spider_comment(): """爬取狗东评论数据""" kv = ‘Referer‘: ‘https://item.jd.com/1070129528.html‘, ‘Sec-Fetch-Mode‘: ‘no-cors‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36‘ url = ‘https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv9087&productId=1070129528&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1‘ try: result = requests.get(url, headers=kv) result.raise_for_status() result_json_str = result.text[26:-2] # json字符串 result_dict = json.loads(result_json_str) # 将json转换为字典 result_json_comments = result_dict[‘comments‘] # 经过分析,发现评论都在‘comments‘,返回列表套字典 for i in result_json_comments: # 真正的评论在‘content print(i[‘content‘]) except Exception as e: print(e) if __name__ == ‘__main__‘: spider_comment()
4.数据保存
数据提取后我们需要将他们保存起来,一般保存数据的格式主要有:文件、数据库、内存这三大类。今天我们就将数据保存为txt文件格式,因为操作文件相对简单同时也能满足我们的后续数据分析的需求。
import json
import os
import random
import time
import requests
comment_file_path = ‘jd_comment.txt‘
def spider_comment():
"""爬取狗东评论数据"""
kv = ‘Referer‘: ‘https://item.jd.com/1070129528.html‘,
‘Sec-Fetch-Mode‘: ‘no-cors‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36‘
url = ‘https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv9086&productId=1070129528&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1‘
try:
result = requests.get(url, headers=kv)
result.raise_for_status()
result_json_str = result.text[26:-2] # json字符串
result_dict = json.loads(result_json_str) # 将json转换为字典
result_json_comments = result_dict[‘comments‘] # 经过分析,发现评论都在‘comments‘,返回列表套字典
for i in result_json_comments: # 真正的评论在‘content‘
with open(comment_file_path, ‘a+‘, encoding=‘utf-8‘) as f:
f.write(i[‘content‘] + ‘\\n‘)
except Exception as e:
print(e)
if __name__ == ‘__main__‘:
spider_comment()
5.批量爬取
我们刚刚完成一页数据爬取、提取、保存之后,我们来研究一下如何批量抓取?
做过web的同学可能知道,有一项功能是我们必须要做的,那便是分页。何为分页?为何要做分页?
我们在浏览很多网页的时候常常看到“下一页”这样的字眼,其实这就是使用了分页技术,因为向用户展示数据时不可能把所有的数据一次性展示,所以采用分页技术,一页一页的展示出来。
让我们再回到最开始的加载评论数据的url:
https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv9087&productId=1070129528&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
我们可以看到链接里面有两个参数page=0&pageSize=10,page表示当前的页数,pageSize表示每页多少条,那这两个数据直接去数据库limit数据。
老司机一眼便可以看出这就是分页的参数,但是有同学会说:如果我是老司机还干嘛看你的文章?所以我教大家如何来找到这个分页参数。
回到某东的商品页,我们将评价页面拉到最底下,发现有分页的按钮,然后我们在调试窗口清空之前的请求记录。
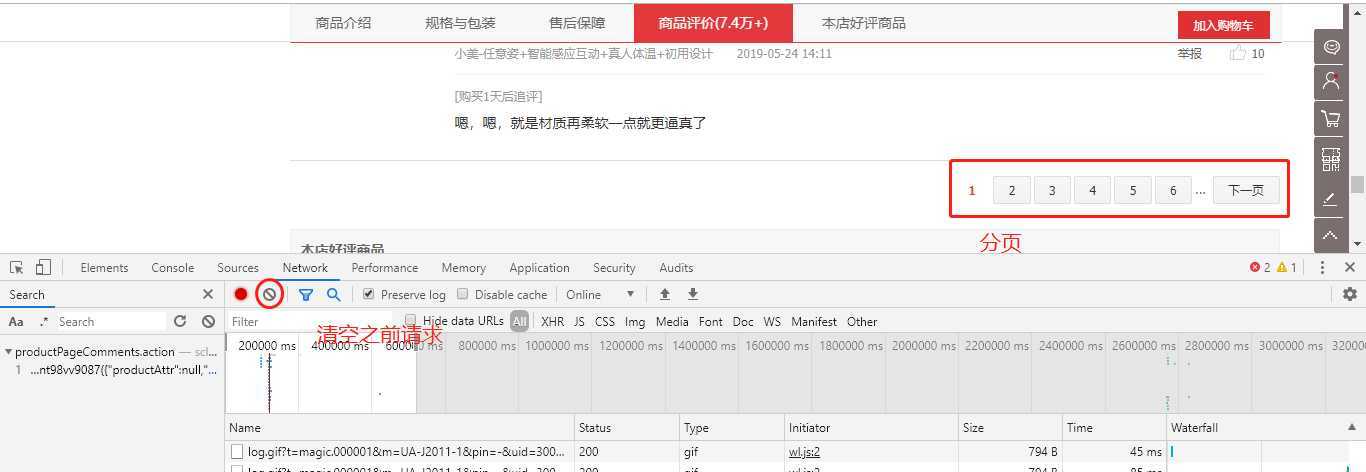
清空之前的请求记录之后,我们点击上图红框分页按钮的数字2,代表这第二页,然后复制第一条评价去调试窗口搜索,最后找到请求链接。
和上面的步骤一样。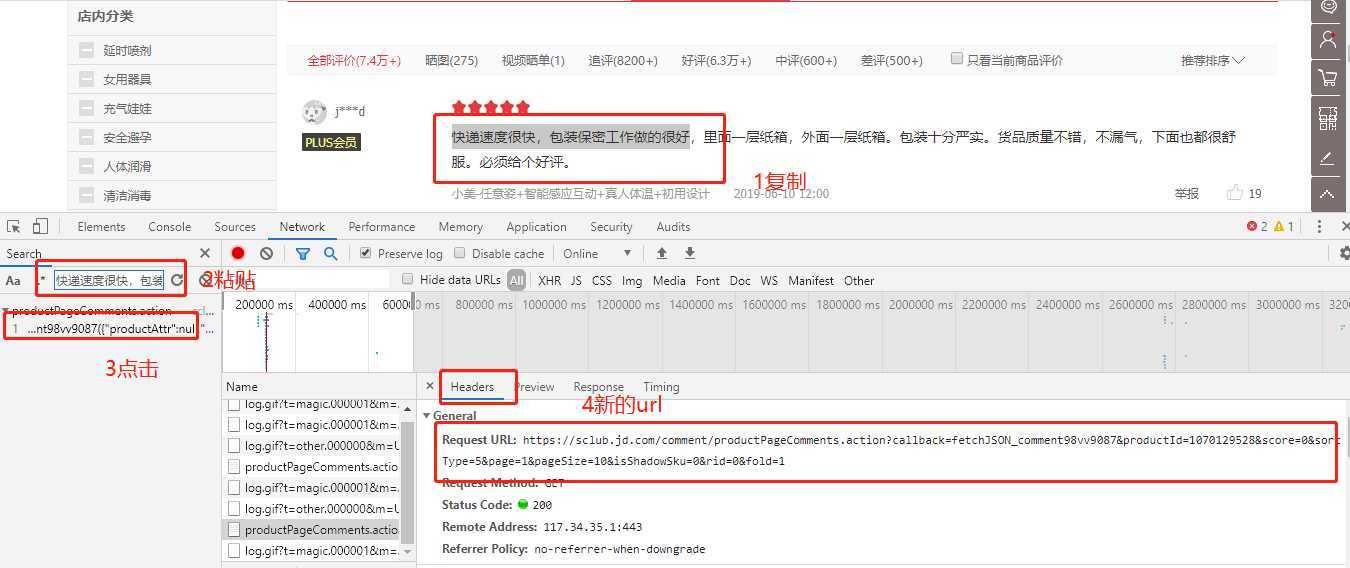
然后我们比较第一页评价与第二页评价的url有何区别,可以很容易发下只有page不同。
这里也就验证了猜想:page表示当前的页数,pageSize表示每页多少条。而且我们还能得出另一个结论:第一个page=0,第二页page=1 然后依次往后。有同学会问:为什么第一页不是1,而是0,因为在数据库中一般的都是从0开始计数,编程行业很多数组列表都是从0开始计数。
好了,知道分页规律之后,我们只要在每次请求时将page参数递增不就可以批量抓取了吗?我们来写代码吧!
import json import os import random import time import requests comment_file_path = ‘jd_comment.txt‘ def spider_comment(page): """爬取狗东评论数据""" kv = ‘Referer‘: ‘https://item.jd.com/1070129528.html‘, ‘Sec-Fetch-Mode‘: ‘no-cors‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36‘ url = ‘https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv9086&productId=1070129528&score=0&sortType=5&page=%s&pageSize=10&isShadowSku=0&fold=1‘ % page try: result = requests.get(url, headers=kv) result.raise_for_status() result_json_str = result.text[26:-2] # json字符串 result_dict = json.loads(result_json_str) # 将json转换为字典 result_json_comments = result_dict[‘comments‘] # 经过分析,发现评论都在‘comments‘,返回列表套字典 for i in result_json_comments: # 真正的评论在‘content‘ with open(comment_file_path, ‘a+‘, encoding=‘utf-8‘) as f: f.write(i[‘content‘] + ‘\\n‘) except Exception as e: print(e) def batch_spider_comment(): # 写入文件之前,先清空之前的数据 if os.path.exists(comment_file_path): os.remove(comment_file_path) for i in range(100): spider_comment(i) # 模拟用户浏览,设置一个爬虫间隔,防止ip被封 time.sleep(random.random() * 5) if __name__ == ‘__main__‘: batch_spider_comment()
6.数据清洗以及生成词云。
数据成功保存之后我们需要对数据进行分词清洗,对于分词我们使用著名的分词库jieba。
import jieba import numpy as np from PIL import Image from wordcloud import WordCloud import matplotlib.pyplot as plt comment_file_path = ‘jd_comment.txt‘ def cut_word(): ‘‘‘ 对数据分词 :return: 分词后的数据 ‘‘‘ with open(comment_file_path, ‘r‘, encoding=‘utf-8‘) as f: comment_txt = f.read() wordlist = jieba.cut(comment_txt, cut_all=True) word_str = ‘ ‘.join(wordlist) #print(word_str) return word_str def create_word_cloud(): """生成词云""" # 设置词云形状图片 coloring = np.array(Image.open(‘wawa.jpg‘)) # 设置词云一些配置,如字体,背景色,词云形状,大小 wc = WordCloud(background_color=‘white‘, max_words=2000,mask=coloring, scale=4, max_font_size=50, random_state=42, font_path=‘C:\\Windows\\Fonts\\msyhbd.ttc‘) # 生成词云 wc.generate(cut_word()) # 在只设置mask情况下,会拥有一个图形形状的词云 plt.imshow(wc, interpolation="bilinear") plt.axis(‘off‘) plt.figure() plt.show() if __name__ == ‘__main__‘: create_word_cloud()
注意:font_path是选择字体的路径,如果不设置默认字体可能不支持中文,猪哥选择的是Mac系统自带的宋体字!
最终结果:

以上是关于充气娃娃什么感觉?的主要内容,如果未能解决你的问题,请参考以下文章