pytorch数学运算与统计属性入门(非常易懂)
Posted yanjy-onlyone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch数学运算与统计属性入门(非常易懂)相关的知识,希望对你有一定的参考价值。
pytorch数学运算与统计属性入门
1、Broadcasting (维度)自动扩展,具有以下两个重要特征:
(1)expand
(2)without copying data
重点的核心实现功能是:
(1)在前面增加缺失的维度
(2)将其中新增加的维度的size扩展到需要相互运算的tensor维度的same size

图1
2、broadcasting自动扩展=unsqueeze(增加维度)+expand(维度扩展)
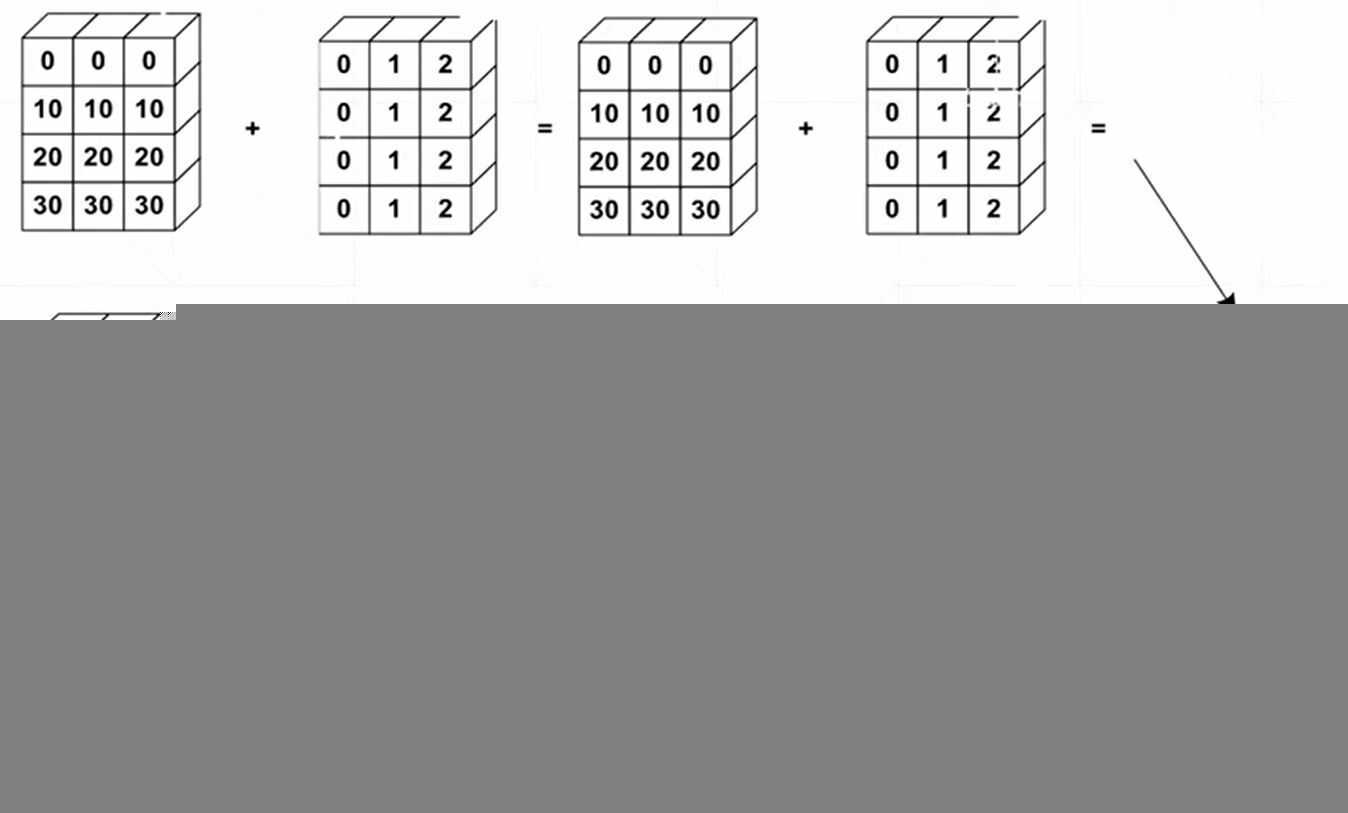
图2
3、tensor的合并与分割:
(1)合并API
1)Cat:对数据进行维度上的合并,不增加属性
2)Stack:增加一个维度,增加一个属性进行数据分类,不对数据进行简单的合并
(2)拆分API
1)Split:根据数据维度的长度来进行拆分(by len([1,2,3...]) or len(1))
2)Chunk:根据所需数据维度的数量来进行拆分(by num)
4、数学运算
(1)基本的加减乘除
1)运算符形式(+-*/)
2)add/sub/mul/div-pytorch的运算名称
(2)高次次方函数power(a,n)表示a的n次方、指数exp和对数函数log函数
(3)矩阵的运算函数-矩阵相乘-torch.mm(仅仅适用于dim=2的情况)/torch.matmul()/@(三种形式)
(4)近似值函数:
a=torch.tensor(3.14)
print(a.floor()) #向下取整函数
print(a.ceil()) #向上取整函数
print(a.trunc()) #数据的整数部分
print(a.frac()) #数据的小数部分
print(a.round())
(5)clamp裁剪函数(梯度裁剪比较常用)
5、统计属性函数

(1)范数函数norm
(2)其他常用属性的计算与统计
a=torch.randn(4,10)
print(a[0])
print(a.min())
print(a.max())
print(a.mean())
print(a.prod())
print(a.std())
print(a.sum())
print(a.argmax(dim=0))
print(a.argsort())
print(a.argmin(dim=1))
(3)dim/keepdim函数的作用:主要用来结果输出维度的变换
(4)topk函数(求取某一维度数据上前n大的数据及其索引)/kthvalue(求取第n小的数据及其索引)
(5)常见比较函数(< > >= <= != torch.gt(),torch.eq(a,b),torch.equal(a,b))
6、其他的高阶操作
(1)where
where(condition,A,B):函数原型:拼接和组装功能
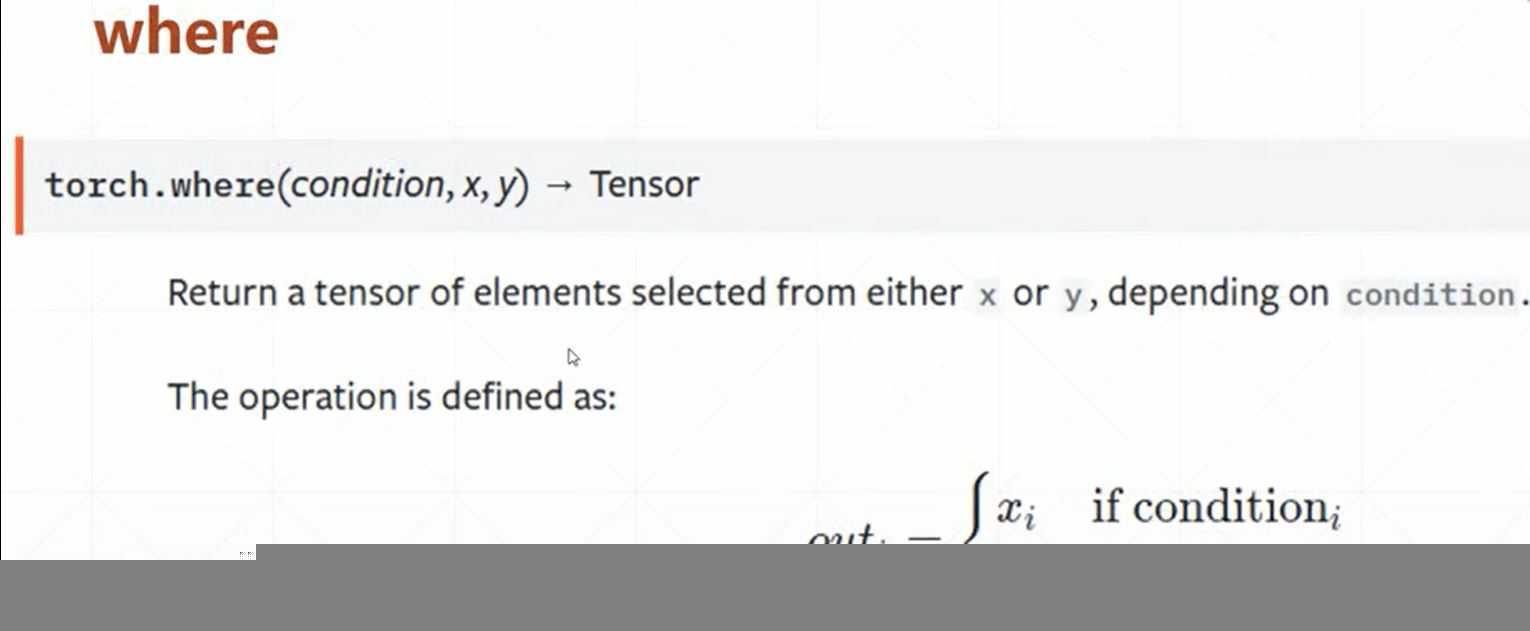
图
(2)gather
gather(input,dim,index):查表和搜索的功能
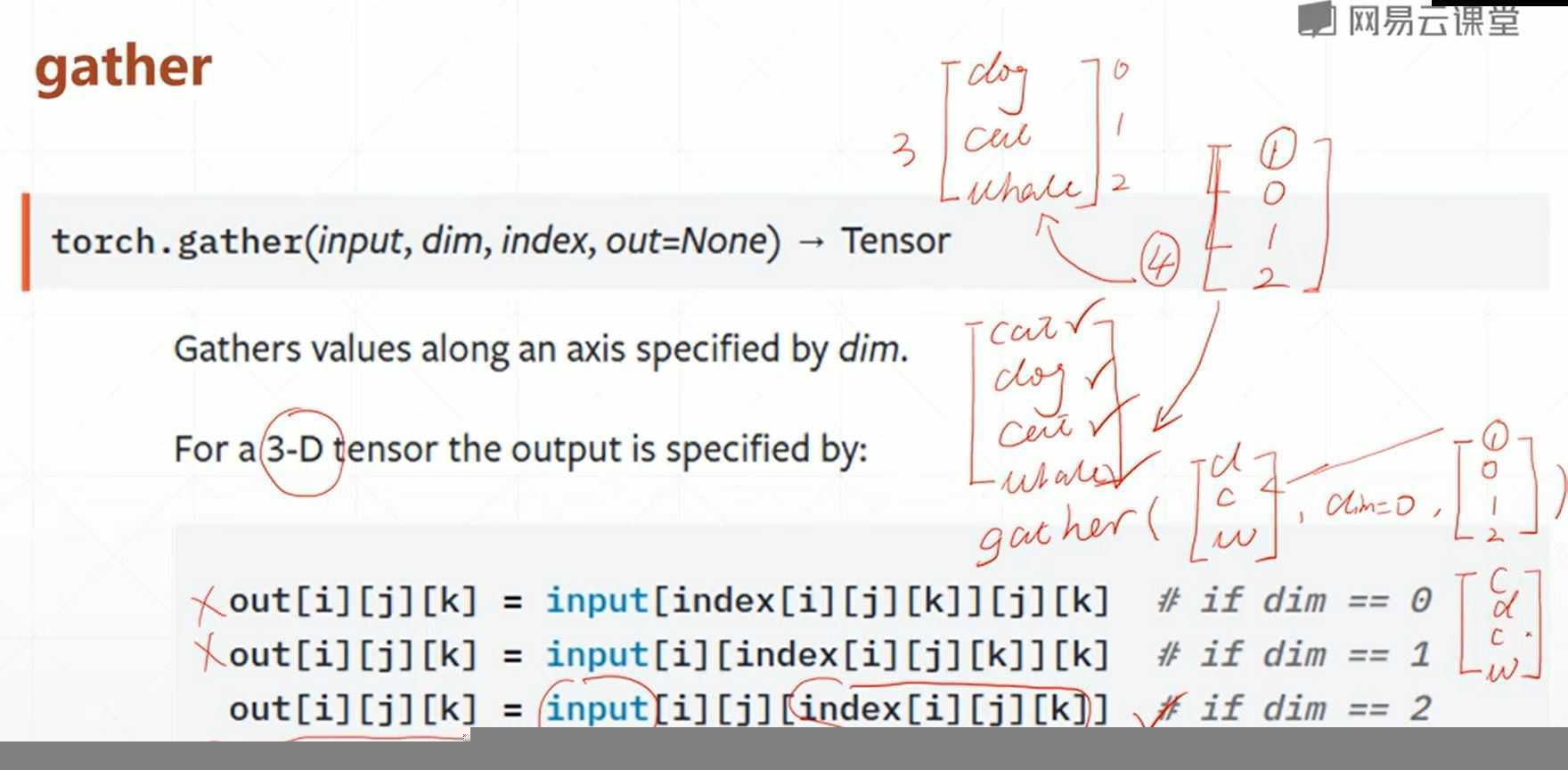
具体的pytorch进阶操作的训练代码如下所示:
#数据的拼接cat函数 对数据进行维度上的合并,不增加属性
import torch
a=torch.rand(4,32,8)
b=torch.rand(5,32,8)
print(torch.cat([a,b],dim=0).shape) #需要合并的数据需要放在list中,另外dim参数是指进行合并的维度
#数据的另外一种拼接方式stack函数:增加一个维度,增加一个属性进行数据分类,不对数据进行合并
a=torch.rand(5,32,8)
b=torch.rand(5,32,8)
print(torch.stack([a,b],dim=2).shape)
a=torch.rand(32,8)
b=torch.rand(32,8)
print(torch.stack([a,b],dim=0).shape)
#数据拆分函数split(by len)和chunk(by num)
#数据拆分spit可以根据数据维度的长度来进行拆分(len([1,2,3...]))
c=torch.rand(3,32,8)
a,b,d=c.split(1,dim=0)
print(a.shape,b.shape)
a,b=c.split([2,1],dim=0)
print(a.shape,b.shape)
c=torch.rand(2,32,8)
a,b=c.split(1,dim=0)
print(a.shape)
#数据拆分根据数据的数量来进行拆分(by num(1)/,函数为Chunk函数
x=torch.rand(4,32,8)
a,b,c,d=x.split(1,dim=0)
print(a.shape)
a,b,c,d=x.chunk(4,dim=0)
print(a.shape)
#tensor数据的数学运算
#基本的加减乘除(1)运算符形式(+-*/)(2)add/sub/mul/div运算名称形式均可
a=torch.rand(4,3)
b=torch.rand(3)
print(a+b)
print(a*b)
print(a-b)
print(a/b)
print(torch.add(a,b)) #与上面是等效的
print(torch.mul(a,b))
print(torch.sub(a,b))
print(torch.div(a,b))
#矩阵的运算函数-矩阵相乘-torch.mm(仅仅适用于dim=2的情况)/torch.matmul()/@(三种形式)
a=torch.ones(2,2)
b=torch.tensor([[1.,2.],[3.,4.]])
print(b)
print(a)
print(torch.mm(a,b))
print(torch.matmul(a,b))
print(a@b) #三种运算等效
#矩阵的降维
a=torch.rand(4,784)
w=torch.rand(512,784)
b=a@w.t()
print(b.shape)
#高次次方函数power(a,n)表示a的n次方、指数和对数函数
a=torch.tensor([[1,3],[2,4]],dtype=float)
print(a)
print(pow(a,3)) #a的三次方
print(a.sqrt()) #a的平方根
print(a.rsqrt()) #a的平方根的倒数
print(torch.exp(a)) #指数函数log
print(torch.log(torch.exp(a))) #对数函数exp
print(torch.log(a))
#近似值函数
a=torch.tensor(3.14)
print(a.floor()) #向下取整函数
print(a.ceil()) #向上取整函数
print(a.trunc()) #数据的整数部分
print(a.frac()) #数据的小数部分
print(a.round()) #求取数据的四舍五入的数据
#clamp裁剪函数(梯度裁剪比较常用)
a=torch.rand(2,3)*15
print(a)
print(a.clamp(10)) #取10以上的数据,小于10的数据代替为10
print(a.clamp(1,10)) #取1-10的数据,将大于10的数据代替为10
#求取数据的统计属性
#1数据的范数norm函数
a=torch.full([8],1)
print(a)
b=a.view(2,4)
c=a.view(2,2,2)
print(a.view(2,4))
print(a.view(2,2,2))
print(a.norm(1),b.norm(1),c.norm(1))
print(b.norm(2,dim=1)) #求取数据的n范数,在dim=x的维度上
print(c.norm(2,dim=2))
#其他常用属性的计算与统计
a=torch.randn(4,10)
print(a[0])
print(a.min())
print(a.max())
print(a.mean())
print(a.prod())
print(a.std())
print(a.sum())
print(a.argmax(dim=0))
print(a.argsort())
print(a.argmin(dim=1))
#dim/keepdim函数的作用
print(a.argmax(dim=1))
print(a.argmax(dim=1,keepdim=True)) #主要用来数据的维度变换[4],转换[4,1]
#topk函数(求取某一维度数据上前n大的数据及其索引)/kthvalue(求取第n小的数据及其索引)
a=torch.rand(4,10)
print(a.topk(3,dim=1))
x,y=a.topk(3,dim=1,largest=False)
print(a.topk(3,dim=1,largest=False))
print(x)
print(a.kthvalue(8,dim=1))
#常用比较函数compare
a=torch.rand(4,10)
print(a>0)
print(a!=0)
print(torch.gt(a,0))
b=torch.rand(4,10)
print(torch.eq(a,b)) #输出每个元素对应位置上的相同与否
print(torch.equal(a,b)) #表示是否完全一样
#高阶操作函数where和gather
#where函数相比for循环来说可以实现GPUU高度并行进行,可以提高数数据处理的速度
cond=torch.tensor([[0.4,0.1],[0.7,0.8]])
print(cond)
A=torch.rand(2,2)
B=torch.rand(2,2)
print(A,B)
print(cond)
print(torch.where(cond>0.5,A,B))
#gather函数-查表操作,可以在GPU上实现,从而提高数据的处理速度,在前沿的一些数据查询和加速方面比较常用
input1=torch.rand(4,10)
print(input1.topk(3,dim=1)[1])
label=torch.tensor(range(100,110))
print(label)
print(label.shape)
print(torch.gather(label.expand(4,10),dim=1,index=input1.topk(3,dim=1)[1])) #gather函数的经典案例帮助理解
以上是关于pytorch数学运算与统计属性入门(非常易懂)的主要内容,如果未能解决你的问题,请参考以下文章