JVM学习记录2--垃圾回收算法
Posted duangl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM学习记录2--垃圾回收算法相关的知识,希望对你有一定的参考价值。
首先要明确,垃圾回收管理jvm的堆内存,方法区是堆内存的一部分,所以也是。
而本地方法栈,虚拟机栈,程序计数器随着线程开始而产生,线程的结束而消亡,是不需要垃圾回收的。
1. 判断对象是否可以被回收
1.1 引用计数法
- 原理:给对象添加一个计数标志,被引用一次就加1,引用取消就减1,而垃圾回收时只需要回收计数值为0的即可。
- 优点:快,简单
- 缺点:无法解决循环引用,如A引用B,B引用A,然后A,B的计数值都是1,但实际上A,B都应该被回收。
1.2 根搜索算法
- 原理:通过一系列名为“GC Roots”的对象做为起点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链(用图论就是对象到GC Roots不可达),则说明对象不可用,可以回收。
- 优点:简单,暴力
- 缺点:对对象的描述只存在“引用”,“无引用”两种,太过纯粹,狭隘。我们希望当内存足够时,可以将一些“缓存”对象也保存在内存,当内存不足时在回收。
java 中引用类型分为4类。
强引用:只有引用关系在,垃圾回收器就不会回收。
软引用:引用关系在,内存足够时,不回收。内存不足时,回收。SoftReference类
弱引用:引用关系在,内存不管够不够,发生gc,必被回收。WeakReference
虚引用:不影响对象的行为,仅为对象被收集器回收时,收到一个系统通知。PhantomReference
2.垃圾回收算法
2.1 标记-清除算法(Mark-Sweep)
标记-清除算法是最基础的收集算法,分为两步。先是“标记”,这个过程就是判断对象是否可以被回收,具体方法就是引用计数法或根搜索算法。其次是“清除”。过程如下:
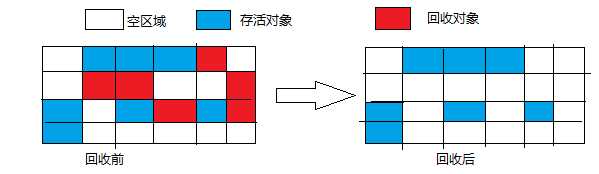
这种算法有两个缺点:一个是效率问题,标记和清除的过程效率不高;一个是空间问题,这种算法产生了很多不连续的内存碎片,当后续分配大对象时,会因为空间不足而多次触发回收,效率更加低下了。
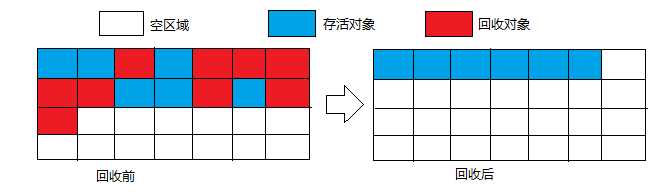
2.2 复制算法(copying)
为了解决效率问题,复制算法将内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块内存用完了,就将存活的对象复制到另一块上面,然后将已使用的内存空间一次清理掉。这样就不需要考虑内存碎片问题了,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。但代价就是讲内存缩小了一半。过程如下:
现在的商业虚拟机都采用这种算法来回收新生代,IBM的专门研究表明,新生代中的对象98%是朝生夕死,所以并不需要安装1:1的比例来划分内存空间。而是将内存分为一个较大的eden区,两个survivor区。当回收,就eden和其中一个survivor区中存活对象一次性地拷贝到另一个survivor区。一般默认的大小比例为8:1。当然,假如survivor区大小不足的话,是需要依赖其它内存的(老生代)进行分配担保(Handle Promotion)。
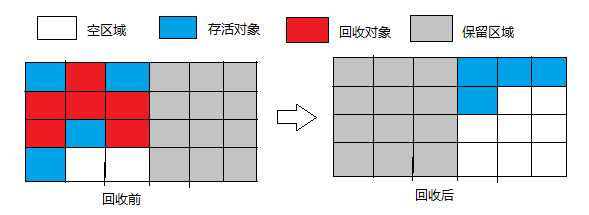
2.3 标记-整理算法(Mark-Compact)
这个算法同样分为两步,首先是“标记”,这个标记-清除算法的“标记”一样,但后续的“整理”不是对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉端边界以为的内存。过程如下:
2.4 分代算法
当前商业虚拟机的垃圾收集都采用了“分代算法”,这种算法并不是新的思想,只是根据对象的存活周期的不同将内存划分为几块。一般是把java堆分为新生代和老生代,这样就可以根据每个区域的特点,采用最适当的收集算法。比如,在新生代采用复制算法(copying)。老生代采用标记-清除算法或者标记-整理算法。
本文借鉴
以上是关于JVM学习记录2--垃圾回收算法的主要内容,如果未能解决你的问题,请参考以下文章