HBase 中的 JVM 与 GC
Posted zackstang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase 中的 JVM 与 GC相关的知识,希望对你有一定的参考价值。
HBase中JVM基本配置
在JVM中,默认情况下会设置minimum heap size 为 1/64 可用物理内存,并为maximum heap size设置 1/4 的物理可用内存(不过在Java8 之前,默认最大是1g)。当然,我们可以通过手动指定 JVM 参数,配置JVM的内存,例如:
-Xms10g -Xmx10g
在HBase 中,也可以在 hbase-env.sh 中显示指定堆内存大小,例如:
# The maximum amount of heap to use. Default is left to JVM default.
# export HBASE_HEAPSIZE=1G
这里有个问题是:是否要同时设置-Xms 与 -Xmx为一相同的值?若是将他们设置为同一一个固定值,则它们的优缺点有:
- 对于一些垃圾回收的算法,例如G1,将它们锁定为同一值会更好
- 不设置 -Xms可以让VM启动更快,但是接下来,需要在每轮gc 增长堆内存后,才会达到一个稳定状态。这样会导致在启动后,最开始会带来一些延迟,这个延时并不是我们在HBase中期望看到的,因为HBase提供的服务一般都是交互式服务
若是设置-Xms与-Xmx为同一值,则JVM在启动时会稍慢,不过在正常启动后,不会再有隐含的内存大小调整的情况,所以会更稳定。而在RegionServer 的进程中,我们可以在分配工作给它前,稍等一会而,以缓解启动进程的消耗。
对于HMaster进程,一般不需要太大内存,2GB 到 4GB就可以满足master的工作需求,因为它的对象分配与销毁的频率远小于RegionServer。
对于RegionServer 进程,若是物理机内存为64GB,则一开始可以给它分配10GB的-Xmx,之后可以根据监控(如jstat等)再进行向上调整。不过若是分配了较大的堆内存,我们也必须要考虑不同的GC算法,以支持更大堆内存中的垃圾回收。
基于以上场景,我们可以在hbase-env.sh 中配置以下参数:
# Set environment variables here.
export HBASE_MASTER_OPTS="-Xms2g -Xmx2g"
export HBASE_REGIONSERVER_OPTS="-Xms10g -Xmx10g"
如前文所述,不指定-Xms的话,堆内存需要在增长多次后才能到达最大堆内存,导致在重新分配内存时的不必要开销,所以最好是按上述指定。
HBase中的堆内存管理
在RegionServer中,主要的任务为:接收并处理读写请求。不过除此之外,RegionServer也需要在内存中维护一些内部信息,例如:对于每个打开的region来说,它们都需要在内存里结构化存储,以处理一些常规操作。
在RegionServer启动后,所分配的JVM堆内存大小就已经指定了,无法再增加。所以对于这部分已有的内存,我们需要谨慎使用,其中最重要的一部分就是:如何调整可供读写操作使用的可用内存。
在HBase 1.0 之前,主要有两个参数需要调整,分别为memstores(对于写)以及block cache(对于读)。剩下的内存被用于所有其他杂项使用(例如Java用于存储打开的region的结构)。对于memstore,我们有以下两个参数可以指定:
hbase.regionserver.global.memstore.upperLimit:默认为0.4(40%),也就是memstore可以使用的最大堆内存hbase.regionserver.global.memstore.lowerLimit:默认为0.35(30%),也就是memstore可以使用的最小堆内存
upper limit在这里较为重要,因为它指定了对于写操作,可以使用的最大内存。对于读来说,仅有一个参数可供调整:
hfile.block.cache.size:默认为0.4(40%),堆内存中用于分配给block cache的比率
memestore的upperLimit ,与 blockcache 的大小,它们的和不能超过80% 堆内存总大小,因为仍需要提供剩余的20% 内存以上,用于regionserver进程完成它自身的部分工作(并且防止Java OOM的问题)。
在HBase 1.0 之后,提供了更多的配置项,用于指定memstore 与 block cache 的upper limit 与 lower limit,例如:
hbase.regionserver.global.memstore.size.min.range:默认未设置,为所有memstore的最小分配内存hbase.regionserver.global.memstore.size.max.range:默认未设置,为所有memsotre的最大分配内存hbase.regionserver.global.memstore.size:默认为0.4(40%),也就是memstore默认被分配的对内存比例
hfile.block.cache.size.min.range:默认未设置,为block cache 大小的最小值hfile.block.cache.size.max.range:默认未设置,为block cache 大小的最大值hfile.block.cache.size:默认为0.4(40%),也就是堆内存中默认分配给block cache 的比例
hbase.regionserver.heapmemory.tuner.period:默认为60000(60s),定义heap tunner 运行的频率
对于memstore与block cache 的上限与下限,我们必须做配置,除非禁止tuner。
HBase 提供了一个机制是:根据请求流量大小,对堆内存进行动态调整。这就是为什么在开启tuner的情况下,我们必须要设置一个上限与下限。
不过这里仍需要保证的一点是:memstore 与 block cache 的最大使用量不能超过JVM内存的 80%。如果超过了这个比例,则tuner会报错,region server 会退出。这个限制的原因与之前的一样:需要剩余足够的内存供给 region server 进程正常工作。
下图是固定内存与动态内存的一个示例图:

动态内存对应的配置为:
<property>
<name>hbase.regionserver.global.memstore.size.min.range</name>
<value>0.2</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size.max.range</name>
<value>0.6</value>
</property>
<property>
<name>hfile.block.cache.size.min.range</name>
<value>0.2</value>
</property>
<property>
<name>hfile.block.cache.size.max.range</name>
<value>0.6</value>
</property>
它们的初始值为默认的40%内存。Tuner可以在某一个内存(如memstore的内存)达到最小20%后,给另一个分配60%的内存。
Tuner的机制仅是增加某一区域(如memstore)的内存,在增加后另一区域(如block cache)的内存即会减少。基于的是(或是说触发的条件是):由于内存压力导致的memstore 强制刷新(会要求更多内存,即增加此区域内存),或是内存压力导致的block cache 中的cache 置换。
两个主要GC算法
在 HBase 中,主要使用的GC算法为CMS或G1,它们的对比如下:
名称 JVM参数 说明
Consurrent Mark Sweep(CMS) -XX:+UseConcMarkSweepGC 低延时(堆内存 < 32GB)
Garbage First(G1) -XX:+UseG1GC 低延时
CMS为较早使用的GC 算法,它可以有效提升HBase的性能,特别是I/O请求的延时。不过它的缺点是:有最大内存的限制。
在CMS刚开始被提出的时候,它可以良好适应当时的服务器硬件性能,不过随着现在超出1TB的内存机器越来越常见,32GB大小的堆内存配置也越来越常见。CMS不适用于较大堆内存的原因是因为:在较大的堆内存中,垃圾回收会造成较长时间的停顿(几秒到十几秒),并最终会导致请求的高延时。
JVM stop log
在HBase region server 进程启动后,会启动一个轻量级的线程,定期(500ms)被唤醒,并比较它在唤醒前它睡眠的时间以及实际经过的时间是否一致。如果检测到它实际睡眠的时间超过了500ms,则在服务器日志记录,例如:
2016-08-05 07:11:32,390 INFO [JvmPauseMonitor] util.JvmPauseMonitor: \\
Detected pause in JVM or host machine (eg GC): \\
pause of approximately 7448ms
GC pool ‘ParNew‘ had collection(s): count=1 time=49ms
GC pool ‘ConcurrentMarkSweep‘ had collection(s): count=1 time=7700ms
...
2016-08-11 23:01:56,686 WARN [JvmPauseMonitor] util.JvmPauseMonitor: \\
Detected pause in JVM or host machine (eg GC): \\
pause of approximately 3594293ms
No GCs detected
第一条是由gc导致,记录的是 CMS 消耗了超过7秒等待垃圾回收完成。第二条与机器的暂停无关。根据暂停的时间,日志会以INFO或是WARN级别记录下来,对应的参数如下:
jvm.pause.info-threshold.ms:默认为1000ms(1s),若是停顿时间超过此值,则以INFO级别记录日志
jvm.pause.warn-threshold.ms:默认为10000ms(10s),若是停顿时间超过此值,则以WARN级别记录日志
在做调优时要注意这些日志条目,以了解停顿的频率与时间。并根据时间调整相关timeout配置(例如zookeeper的配置,如果regionserver 超过一段时间未响应,可能会被zookeeper认为宕机)。
CMS 与 G1
再回到GC部分,G1的提出就是为了解决:CMS在较大堆内存回收垃圾时产生的长时间停顿问题。下图是两者的实现与对比:
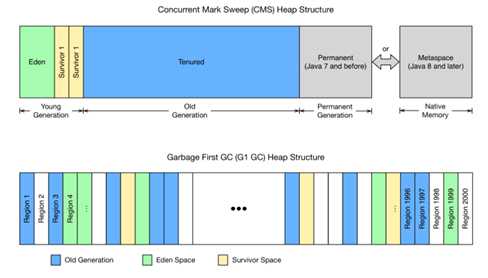
在G1 中,相对于CMS预先配置的堆内存容量,它将整个堆内存空间划分为多个相同大小的regions,一般是2000个左右。在划分好后,G1可以让其中的部分region分别执行Young Generation、Old Generation、以及survivor的角色。G1 gc采用的策略就是在这些区域中执行较多的gc任务,以尽可能地减少jvm pause以及对用户的影响。虽然这些额外的工作是会对延时有较大的影响,不过从长远来看,它的jvm pause时间会更短,并可以提供更稳健的延时,而不是抖动的延时。
CMS
CMS是一个性能较好的GC算法,已被使用多年。启用的参数为:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
(这里其实在指定 -XX:+UseConcMarkSweepGC 后就默认已经指定了-XX:+UseParNewGC,这里显示指定为了之后进一步的讨论)
第一个选项是为Young Generation 设置使用Parallel New Collector:它在清理Young Generation 时会停止整个Java 进程。这个在Young Generation中是可以被接受的,因为它的内存相对Old Generation 会少得多,所以此过程也不会消耗太多的时间,一般少于几百毫秒。不过,这个设置对于Old Generation是不合适的,在最坏的情况下,可能会导致多达几秒的延时。
对此,CMS可以较好地解决此问题,它会尽可能地并行做gc,而不停止Java 进程。虽然此方法会造成额外的CPU资源消耗,但是可以减少或是避免JVM pause。CMS也是hbase 中默认的gc算法。
在CMS中,我们可以做的第一个调整是:Young Generation的大小。它默认的值较小,在region server 执行写操作时,会将数据写入memstore,过小的Young Generation会让这部分数据停留在此区域的时间较短,并可能造成不必要的generation 提升(Young Generation 提升到 Old Generation)。对此,可以将Young Generation的大小设置为一个固定的、更大的一个值,以减少此类影响,例如:
-XX:MaxNewSize=128m -XX:NewSize=128m
或者也可以直接用这两个配置的简写:-Xmn128m。
128MB是一个较好的起点,之后可以根据JVM的指标,确定是否满足需求或是是否需要添加更多的内存。不过对于有较高负载的region server 来说,默认的Young Generation 的大小有些过于小了。如果在一开始不调整此参数的话,我们可能会注意到CPU的使用率会偶尔突然增高,因为JVM需要花时间将Young Generation 中的对象提升到Old Generation中(由于Young Generation中内存不足)。
CMS还有一个参数用于控制:什么时候开始做concurrent mark and sweep 检查。这个参数可以通过以下配置设置:
-XX:CMSInitiatingOccupancyFraction=85
此参数指定的是:什么时候启动后台cms垃圾回收。此参数不能配置过高,为了避免concurrent mode failure 问题。此问题发生的场景为:在后台mark and sweep 工作正在进行时,堆内存已经耗尽了所有的可用空间。则此时,JRE必须停止Java 进程,并且通过清除垃圾,或是将Young Generation 中的对象移动到 Old Generation中(如果这些对象已经够old),以释放空间。
设置此值为85%,表示在堆内存耗尽之前就会开始执行concurrent collection 的工作,但也不会是太早去做这个工作。一个常规的建议是:将这部分值设置为稍高于memstore与block cache总和大小的值。它们的总和一般为80%(memstore 40%,block cache 40%),所以我们会优先设置为85%左右或以上。
下面是一个起始的CMS参考配置:
export HBASE_REGIONSERVER_OPTS="-Xms10g -Xmx10g -Xmn128m \\
-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=85 \\
-XX:+UseCMSInitiatingOccupancyOnly"
G1
G1的启用方法为:
-XX:+UseG1GC
除此之外,还需要设置一个预期最大的gc pause 时间。不过这个仅是一个soft goal,JVM会尽量满足此目标。不过若是为了满足工作负载,此暂停时间可能会更长。此参数为:
-XX:MaxGCPauseMillis=200
默认即为200ms,可以根据需求做进一步调整。最后一个参数需要调整的是:什么时候gc collector 开始一个concurrent GC cycle,以整个堆内存已使用部分百分比为阈值,默认为45%,例如:
-XX:InitiatingHeapOccupancyPercent=45
可以先以此为初始配置,然后再根据负载调整G1 中每个region的大小等,此部分需要更深入的G1 算法知识,之后再详述。
以上是关于HBase 中的 JVM 与 GC的主要内容,如果未能解决你的问题,请参考以下文章