协同过滤 Collaborative Filtering
Posted chaojunwang-ml
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了协同过滤 Collaborative Filtering相关的知识,希望对你有一定的参考价值。
协同过滤 collaborative filtering
人以类聚,物以群分
相似度
1. Jaccard 相似度
定义为两个集合的交并比:
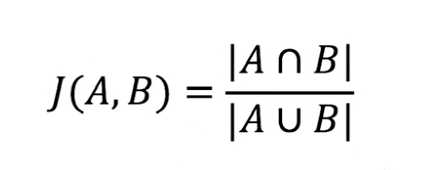
Jaccard 距离,定义为 1 - J(A, B),衡量两个集合的区分度:
![]()
为什么 Jaccard 不适合协同过滤?—— 只考虑用户有没有看过,没考虑评分大小
2. 余弦相似度
根据两个向量夹角的余弦值来衡量相似度:
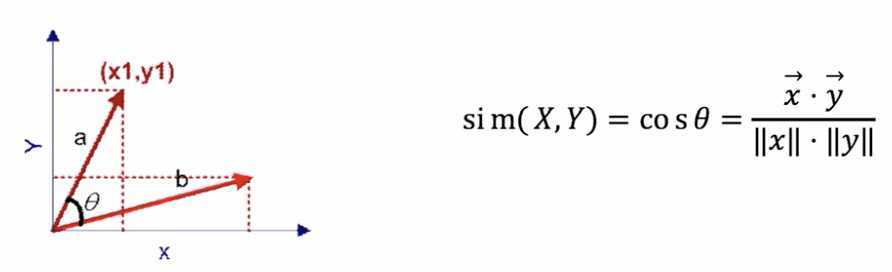
为什么余弦相似度不适合协同过滤?—— 不同用户各自评分总和不一样,导致评分占总比不一样,可能计算出和事实相反的结果。
3. Pearson 相似度
解决余弦相似度中的相似度差异问题,又称中心余弦算法。先中心化,再算余弦相似度,这样正值表示正相关,负值表示负相关。
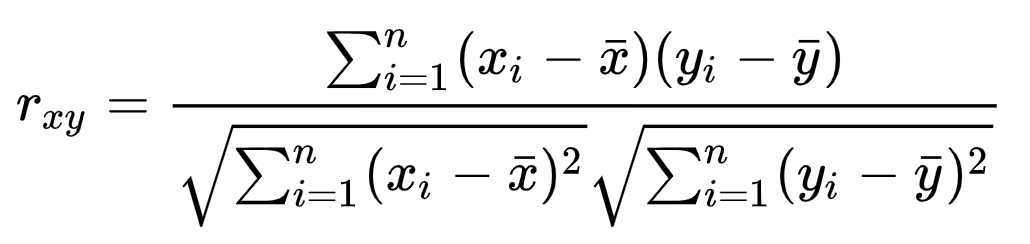
基于用户的协同过滤
通过用户对物品的喜爱程度进行度量和打分。根据不同用户对相同商品或内容的态度进行商品推荐。
举例说明,每个行向量表示某个用户对所有电影的评分

先把数据中心化
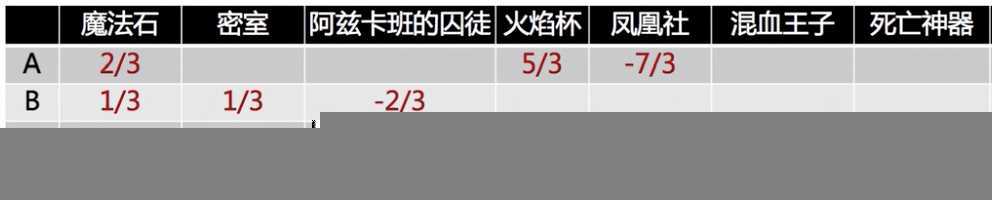
然后计算用户 A 和其他用户的 Pearson 相关系数:
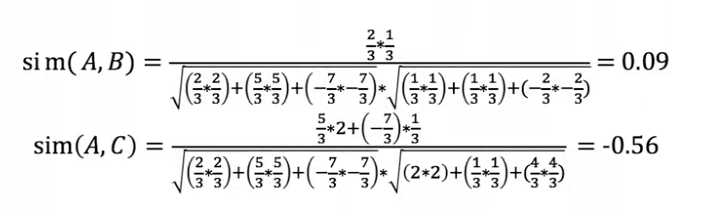
可以发现用户 A 和用户 B 喜好接近,因此可以将 B 喜欢但 A 没看过的密室推荐给 A,同时也可以将 A 喜欢但 B 没看过的火焰杯推荐给 B。
用户法存在的问题:
1. 数据稀疏性。物品太多,不同用户之间买的物品重叠性较低,导致无法找到一个偏好相似的用户
2. 算法扩展性。最近邻算法的计算量随着用户和物品数量的增加而增加,不适合数据量大的情况使用。
基于物品的协同过滤
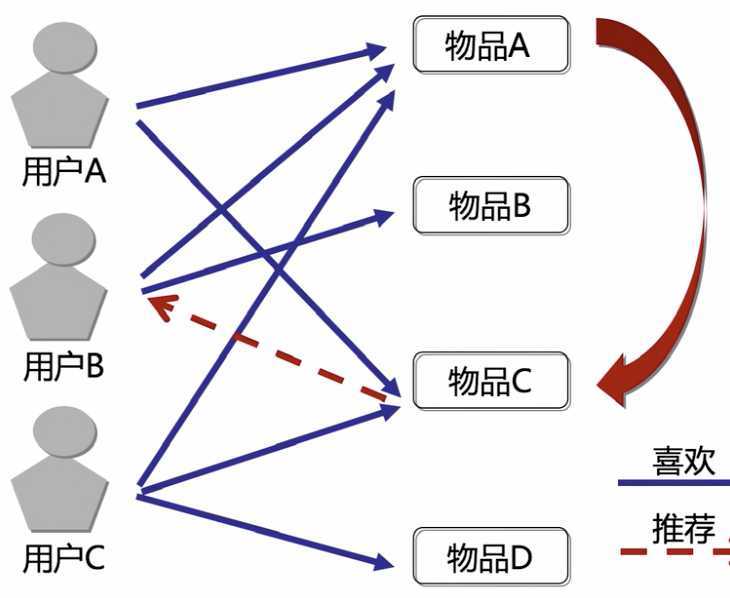
通过计算不同用户对于不同物品的评分,获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。
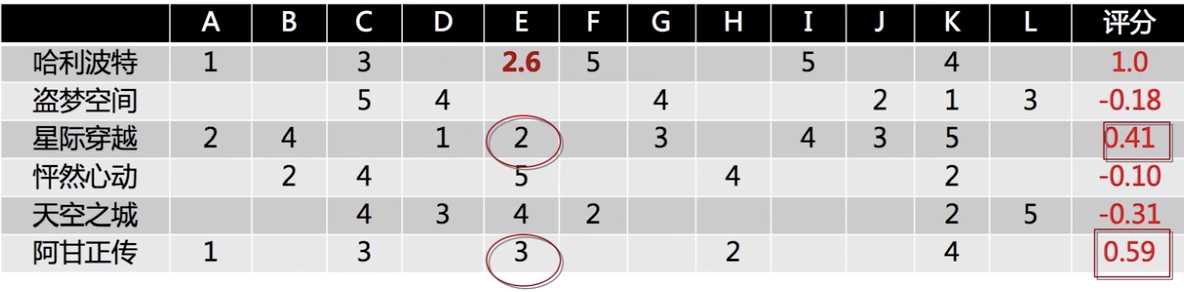
举例说明,每一个行向量表示某个物品被各个用户的评分,先中心化
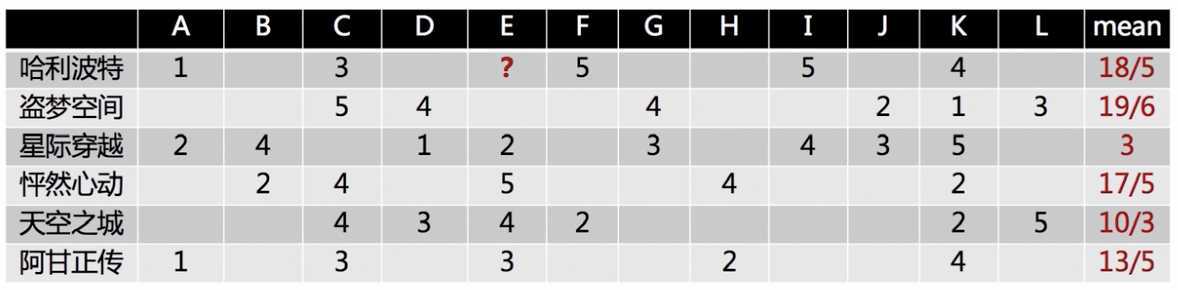
如何预测用户 E 对 哈利波特的喜好程度?计算哈利波特和其他电影之间的 Pearson 相关系数

选择相关性较大的其他电影,拿出用户 E 对这些电影的评分,利用 Pearson 相关系数做 weighted sum:
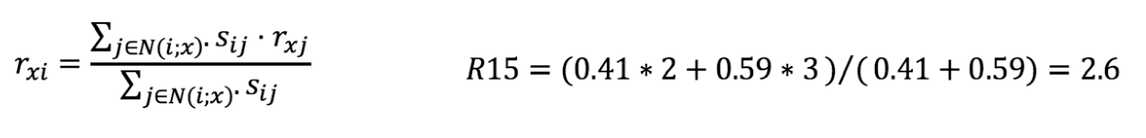
从原理上看,基于用户或基于物品都是可以的,但实践中以物品为基础效果更好,且需要很少的数据就可以进行预测,用户法需要大量数据。
SVD 协同过滤
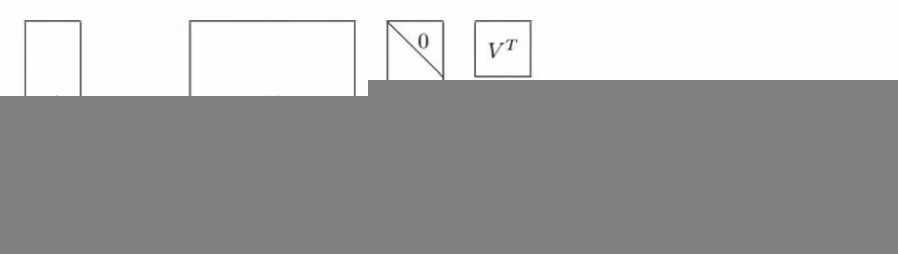
奇异值矩阵的特征值按照从大到小排列且迅速减小,可以把大矩阵用三个小矩阵来近似描述,实现降维和去噪,应用于协同过滤中可以减少计算量。
用 K 维 SVD 分解做协同过滤,实际上就是找一组 latent variables,U 和 V 分别描述了物品与隐变量、用户与隐变量之间的关系。 然后就可以都在 latent space 中表示。
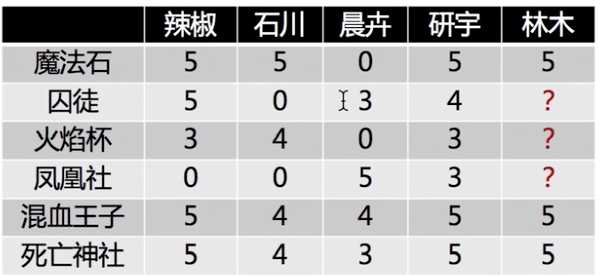
举例说明,4 个用户对 6 部电影的评分情况
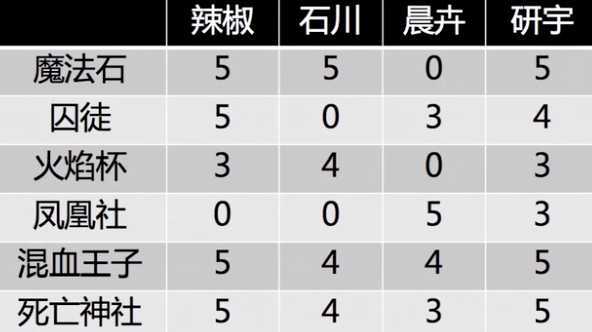
做二维 SVD 分解:

在 latent space 中表示用户和电影,发现电影之间、用户之间、电影和用户之间,都可以衡量中心余弦相似度。
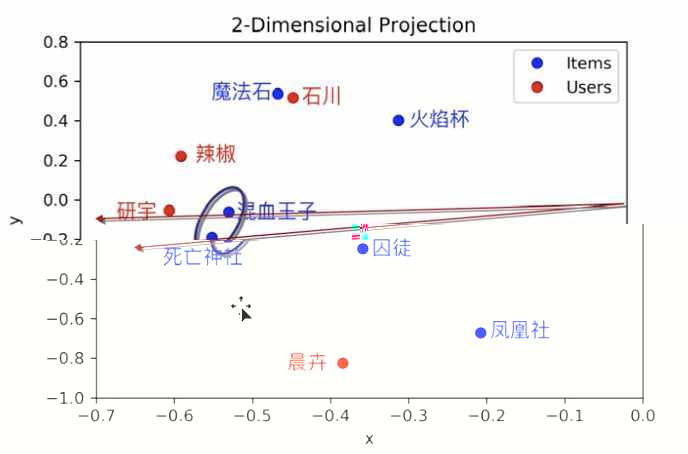
如果出现一个新用户,如何给他推荐他没有看过的电影?
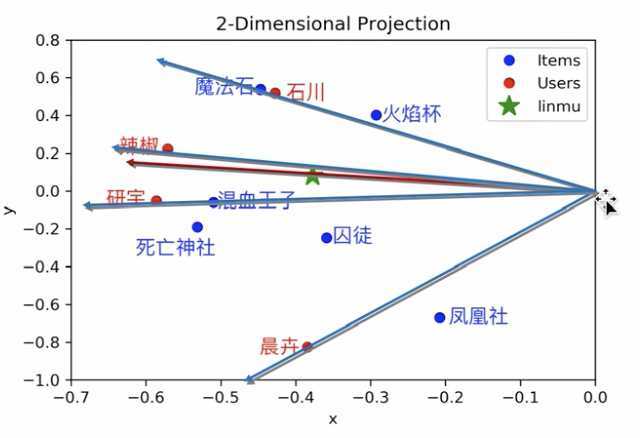
把新用户投影到 latent space

找到和新用户相似度高的用户,把相似用户评分高而新用户没看过的电影,按相似用户的评分高低顺序先后推荐给新用户即可。
以上是关于协同过滤 Collaborative Filtering的主要内容,如果未能解决你的问题,请参考以下文章