Java中常用IO流之文件流的基本使用姿势
Posted u-vitamin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java中常用IO流之文件流的基本使用姿势相关的知识,希望对你有一定的参考价值。
所谓的 IO 即 Input(输入)/Output(输出) ,当软件与外部资源(例如:网络,数据库,磁盘文件)交互的时候,就会用到 IO 操作。而在IO操作中,最常用的一种方式就是流,也被称为IO流。IO操作比较复杂,涉及到的系统调用比较多,相对操作内存而言性能很低。然而值得兴奋的是,Java提供了很多实现类以满足不同的使用场景,这样的实现类有很多,我只挑选些在日常编码中经常用到的类进行说明,本节主要介绍和文件操作相关的流,下面一起来瞧瞧吧。
File
File是Java在整个文件IO体系中比较基础的类,它可以实现对文件,文件夹以及路径的操作,譬如:创建文件或文件夹,获取绝对路径,判断是否存在,重命名,删除,获取当前目录下的文件或文件夹等操作。
File file = new File("example"); //相对路径
System.out.println(file.getAbsolutePath()); //获取绝对路径
System.out.println(file.getName()); //获取名称
System.out.println(file.exists()); //判断文件或文件夹是否存在
boolean result = file.mkdirs();// 把 example 当成文件夹来创建,mkdirs()为级联创建
System.out.println(result);
result = file.createNewFile();// 把 example 当成文件夹来创建
System.out.println(result);
在使用File的时候有几点需要注意:
- 传入File中的参数路径可以存在也可以不存在。
- 传入File中的参数路径如果是相对路径,那么这个路径是相对于当前Java Project根目录的。
- 当传入的路径不存在的时候,是无法根据 isDirectory() 或 isFile() 来判断是文件夹还是文件
当有需求进行遍历指定目录下所有指定后缀名或是指定名称文件或文件夹时,需要在ListFile的参数中提供一个名为filter的过滤器来帮助实现过滤功能,这个过滤器Java是不进行提供的,要根据自己的需求来实现。如果要使用这个方法需要实现FileFilter 类。如下实现了一个过滤指定文件的后缀名的过滤器。
class ExtendNameFilter implements FileFilter
private String extendName;
public ExtendNameFilter(String extendName)
this.extendName = extendName;
public boolean accept(File dir)
if(dir.isDirectory())
return true;
return dir.getName().endsWith(this.extendName);
// 筛选指定文件夹下文件以.java结尾的文件
File[] files = file.listFiles(new ExtendNameFilter(".java"));
for(File f : files)
System.out.println(f.getName());
File还有很多常用的操作,由于篇幅有限这里就不逐个演示,更多操作的使用方式和如上示例在调用方法上没有任何区别,主要注意参数和返回值即可。
字节,字符和编码格式
对于字节,字符和编码格式这里不做概念性的描述,详细的释义网上有很多,请自行查阅。但从表现形式上对于它们可以大致这样理解:字节和字符对于系统数据而言表现形式是不同的,可以通过打开一些文件来观察,如果打开的是图片或者是可执行程序文件,那么就会看到一些类似于乱码的东西;而如果是文本文件,基本上会看到明文数据,例如“你好”,“Hello World”等。对于前一种看不懂的就是使用字节来表示的,能看的懂得就是使用字符来表示的。而字符也是通过字节来存储的,只不过,在不同的编码格式中所使用的字节数是不一样的,具体哪些字符需要多少个字节表示需要对应的编码表。例如:使用GBK编码存储汉字字符,则用2个字节来表示,但在UTF8中则使用3个字节来表示
FileOutputStream & FileInputStream 字节流
File只是能操作文件或文件夹,但是并不能操作文件中的内容,要想操作文件的内容就需要使用文件IO流,其操作文件的内容主要有两种方式:以字节的方式和以字符的方式。而该小节主要讲以字节文件流的形式操作文件内容,以字符文件流的方式操作我留到下一小节进行说明。
在Java中以字节流的形式操作文件内容的类主要是FileOutputStream 和 FileInputStream。 分别是 OutputStream(字节输出流) 和 InputStream(字节输入流) 抽象基类的子类。下面以图片的复制来展示下该流的用法。
File sourceFile = new File("sourceFile.jpg");
File destFile = new File("destFile.jpg");
FileInputStream fis=null; // 读取源文件的流
FileOutputStream fos = null; // 输出到目标文件的流
try
fis = new FileInputStream(sourceFile);
fos = new FileOutputStream(destFile);
byte[] bytes= new byte[1024];
int len = 0;
while((len=fis.read(bytes))!=-1)
fos.write(bytes, 0, len);
catch(IOException ex)
finally
try fis.close(); catch(IOException ex)
try fos.close(); catch(IOException ex)
在使用 FileOutputStream 和 FileInputStream 的过程中需要注意的地方:
- FileInputStream 所要操作的文件必须存在,否则就会抛出异常。而 FileOutputStream 写入的目的文件则不需要存在,当不存在时会被创建,存在的时候会被覆盖,也可以使用 FileOutputStream 造函数的第二个参数,来实现追加文件内容。
- 在使用 FileInputStream 读取字节的时候,当读取到字节的末尾,再继续读取,无论多少次都会返回 -1,而返回值len表示本次读取了多少个字节。通常情况下每次读取1024个字节,可以达到空间和时间的平衡。但是具体情况也是需要具体分析的。
- 字节流是不存在缓冲区的,所以不需要使用flush操作刷新缓冲区,字节的读取和写入都是通过操作系统来实现的。
- 只要是流就是需要关闭的,无论是否在异常情况下都需要关闭流,防止占用系统资源,导致其他程序无法对该文件进行操作。但是在关闭流的时候也有可能会报异常,所以也需要 try...catch。
FileOutputStream 和 FileInputStream主要用来操作字节表现形式的文件,例如图片,可执行程序等。当然操作字符表现形式的文件也是没有问题的,只不过这么干不规范。
OutputStreamWriter & InputStreamReader
这小节主要讲以字符流的形式操作文件,在Java中对应操作的主要类为 OutputStreamWriter 和 InputStreamReader 。有时候又称它们为转换流,具体原因一会在说,先看一个例子。
File sourceFile = new File("sourceFile.txt");
File destFile = new File("destFile.txt");
FileInputStream fis= new FileInputStream(sourceFile);
FileOutputStream fos = new FileOutputStream(destFile);
InputStreamReader reader=null;
OutputStreamWriter writer=null;
try
reader= new InputStreamReader(fis,"utf-8");
writer =new OutputStreamWriter(fos,"gbk");
char[] cbuf =new char[1024];
int len=0;
while((len=reader.read(cbuf))!=-1)
System.out.println(String.copyValueOf(cbuf,0,len));
writer.write(cbuf, 0, len);
catch(IOException ex)
tryreader.close();catch(IOException ex)
trywriter.close();catch(IOException ex)
上述示例主要实现了一个文件的复制,与字节流的使用方式不同的是,字符流的构造函数需要传递字节流和编码格式。这是因为操作文件内容都是以字节的形式来操作的。字符输入流根据编码表对字节流读取的字节转义成字符,同时也说明了传递编码表格式参数的重要性。如果被读取文件编码格式是UTF-8且不传递这个参数,那么这个参数为操作系统的默认编码表(对于Windows而言是GBK),如果默认的编码表与UTF-8不同(与系统编码表格式相同,可不传递此参数),在转义为字符的过程中就会出现问题。假如文件内容为“好”,在UTF-8中对应的字节为-10-20-30。那么就以系统的默认编码表来转义,假如默认为GBK,“好”字的编码为-50-60,由原来3个字节表示汉字,现在变成了2个字节表示汉字,又由于编码表不兼容,所以导致出现乱码。而在使用字符输出流的时候,将字符按照编码表参数转化为字节后再写入对应编码格式的文件中去。如果输出的内容是以追加的方式,那么需要保证前后两个输出文件内容的编码格式一样,否则也会出现乱码。假如之前的输出文件是GBK格式,你使用字符输出流输出的字符格式为UTF8并追加到文件中去,这个时候乱码就产生了。综上过程,也就知道大家为什么又称 FileOutputStream 和 InputStreamReader 为转换流了。
传递给字符流的字节流不需要单独的进行关系,在字符流关闭的时候会调用字节流的close()方法。
FileWriter & FileReader
FileWriter 和 FileReader 分别是 OutputStreamWriter 和 InputStreamReader 的子类,只不过他们是只能操作系统默认编码表的字符流。也可以这么简单的理解: OutputStreamWriter 和 InputStreamReader 的构造函数不支持传递第二个参数,就是操作系统默认的编码表。所以在使用上只需要注意操作的文件编码格式是否与系统默认的编码格式一致即可。既然不传递第二个参数就可以达到相同的效果,为什么还会有这个两个类呢?因为这两个类操作简单。下面还是以复制文件为例。
File sourceFile = new File("sourceFile.txt");
File destFile = new File("destFile.txt");
FileReader reader=null;
FileWriter writer=null;
try
reader= new FileReader(sourceFile);
writer =new FileWriter(destFile);
char[] cbuf =new char[1024];
int len=0;
while((len=reader.read(cbuf))!=-1)
System.out.println(String.copyValueOf(cbuf,0,len));
writer.write(cbuf, 0,len);
catch(IOException ex)
finally
tryreader.close();catch(IOException ex)
trywriter.close();catch(IOException ex)
无论是使用 FileWriter & FileReader 还是 OutputStreamWriter & InputStreamReader ,在他们的内部都会存在缓冲区的,默认大小为8192字节。如果不对流进行关闭的话,数据会继续存在缓冲区,不会存储到文件上,除非手动调用flush方法或者是在缓冲区中写入的数据超过了缓冲区的大小,数据才会刷新到文件上。而调用close方法的内部会先调用flush刷新缓冲区。
BufferedOutputStream & BufferedInputStream & BufferedWriter & BufferedReader
这四个Buffered开头的类分别是为字节流和字符流提供一个合适的缓冲区来提高读写性能,尤其是在读写数据量很大的时候效果更佳显著。其用法和不带Buffered的流没有任何区别,只不过在不带Buffered流的基础上提供了一些更加便利的方法,例如newLine(),ReadLine()和ReadAllBytes(),他们会根据操作系统的不同添加合适的换行符,根据合适的换行符来读取一行数据和读取所有字节。来看一下用法以缓冲字符流为例
File sourceFile = new File("sourceFile.txt");
File destFile = new File("destFile.txt");
BufferedWriter bw =null;
BufferedReader br =null;
try
FileReader reader= new FileReader(sourceFile);
FileWriter writer=new FileWriter(destFile);
bw =new BufferedWriter(writer);
br =new BufferedReader(reader);
String line =null;
while((line=br.readLine())!=null)
bw.write(line);
bw.newLine();
catch(IOException ex)
finally
try bw.close(); catch(IOException ex)
try br.close(); catch(IOException ex)
上述的代码中有两点需要注意:
- 当按照行来读取字符的时候,当下一行没有内容,继续读取下一行的内容,结果会返回 null,可以此来判断文件中是否还有字符。
- 当读取的文件行返回为null后,仍然会执行一次循环,此时调用newLine() 会在写入的文件中多添加一个换行符,这个换行符无关紧要,可以不用考虑处理掉。
ObjectOutputStream & ObjectInputStream
在编写程序的过程中,难免会遇到和外部程序进行数据交流的需求,例如调用外部服务,并传输一个对象给对方,此时需要把传输对象序列化为流才能和外部程序进行交互。又比如需要对一个对象进行深拷贝,也可以将对象序列化为流之后再反序列化为一个新的对象。Java提供了ObjectOutputStream 和 ObjectInputStream 来实现对对象的序列化和反序列化。序列化后的流为字节流,为了清晰的看到序列化后的结果,以下将序列化后的流输出到文件中然后在反序列化为一个对象,具体来看一看吧。
Student stu =new Student("vitamin",20,1);
File destFile = new File("destFile.txt");
// 序列化对象到文件中
ObjectOutputStream oos= null;
try
FileOutputStream fos = new FileOutputStream(destFile);
oos =new ObjectOutputStream(fos);
oos.writeObject(stu);
catch(IOException ex)
finally
try oos.close();catch(IOException ex)
// 反序列化文件中的流为对象
ObjectInputStream ois= null;
try
FileInputStream fis = new FileInputStream(destFile);
ois =new ObjectInputStream(fis);
Student newStu = (Student)ois.readObject();
System.out.println(newStu.toString());
catch(Exception ex)
finally
try ois.close();catch(IOException ex)
// Student 类定义
class Student implements Serializable
private String Name;
public int Age;
public transient int Sex;
public static String ClassName;
private final static long serialVersionUID= -123123612836L;
public Student(String name,int age,int sex)
this.Name =name;
this.Age = age;
this.Sex = sex;
@Override
public String toString()
return String.format("Name=%s,Age=%d,Sex=%d", this.Name,this.Age,this.Sex);
对象要想成功实现序列化和反序列化需要注意以下几点:
- 对象要想实现序列化,被序列化的对象要实现标记接口 Serializable。
- 无论属性访问权限如何,都可以进行序列化和反序列化,但静态属性无法被序列化和反序列化。
- 如果在对象序列化的过程中,不想让某个属性参与其中,可以使用关键字
transient进行标记。 - 序列化到文件后是不要进行flush操作的,同字节流一样也不存在缓冲区。
- 如果对象在序列化后,对对象的属性的修改(比如访问属性的变更,字段类型的变更)都会导致在反序列后出现类似错误 :
Student; local class incompatible: stream classdesc serialVersionUID = -123123612836, local class serialVersionUID = -1225000535040348600这是由于对象在编译成class文件过程中会对属性生成一个serialVersionUID,这个属性也会存储到序列化后的对象中,每次属性的变更都会导致它进行修改,如果出现前后不一致,则导致出现以上错误。如果想避免这个问题,需要在对象内指定 serialVersionUID ,具体数值什么都可以。但是属性的定义一定要是 final static long。 - 反序列化后的对象是Object类型,不是Student。如果需要使用Student对象的属性或方法,需要进行强制类型转化。
- 对象在序列化和反序列化的过程中,抛出的不只有IOException。如果删除Student类定义或是Student.class文件,然后对序列化后的流调用toString()方法
System.out.println(ois.readObject());,就会抛出异常:java.lang.ClassNotFoundException: Student, 如果反序列化后的对象转为非Student对象,也会报其他的非IOException异常。所以在处理异常的时候,需要考虑到这些情况。
Properties
在学习Java的过程中肯定会接触到用Map结构来存储Key/Value关系的数据,在我之前的博客 Java中关于泛型集合类存储的总结 中讲到过它的一个实现类 HashMap。 但是除了HashMap外还有一个实现类HashTable ,它可以实现和HashMap一样的功能,但是由于是线程安全的(同步的)并且存储的对象是Object类型,这就导致它的性能对于线程不安全(非同步)HashMap会有所降低,所以不是很常用。但是HashTable有一个子类 Properties 却很常用,它可以在文件中存储 Key=Value 形式的数据,可以用其来读取配置。
Properties prop =new Properties();
prop.setProperty("Name", "vitamin");
prop.setProperty("Age", "20");
File file =new File("destFile.txt");
FileWriter writer =new FileWriter(file);
prop.store(writer, "this is a test conf"); // 存储到文件中并设置备注,如果备注是中文则会被转码
FileReader reader =new FileReader(file);
prop.load(reader);
System.out.println(prop.getProperty("Name")); // vitamin
System.out.println(prop.getProperty("Sex")); // null
System.out.println(prop.getProperty(" Name")); // nullProperties虽然继承自HashTable,但是它的Key和Value只能是String类型,然而实现内部仍然调用的是put(Object,Object)方法。Properties是允许你直接调用put(Object,Object)方法的,毕竟都是Map的实现类,但是这样调用了之后,在运行时会报错并警告你只能设置String类型的数据。
Properties通过load和store方法将Key=Value的对应关系从文件中加载并转化为Properties对象和将Properties对象转化为Key=Value对应关系存在到文件中。注意:在文件中存储的Key=Value关系形式,在等号两侧是否有空格很重要,如果有空格,虽然看上去是没什么问题,但是对于Properties对象而言却不是你想要的结果,可以自己尝试一下。如果需要在被Load的文件中添加注释的话,则在行首添加 # 即可。
#this is a test conf
#Sat Sep 21 15:03:54 CST 2019
Age=20
Name=vitamin
PrintStream & PrintWriter
最后再来说一下Java提供的打印流 PrintStream 和 PrintWriter,可以在输出的数据上做一些格式化操作。 提起 PrintStream 你可能会感到很陌生,但你是否留意过经常使用的System.out.print() 方法的内部实现,它的底层就是使用 PrintStream 来操作的,PrintStream 继承自文件字节流 FileOutputStream。对于后者 PrintWriter 更加常用,因为它实现了前者的所有方法,并且可以实现对字符流的打印,这是PrintStream所没有的。所以 PrintWriter 也更加灵活。下面通过示例来感受下 PrintWriter吧
File file =new File("destFile.txt");
PrintWriter pw =null;
try
pw = new PrintWriter(file);
pw.printf("Name=%s", "vitamin");
pw.flush();
catch(IOException ex)
finally
pw.close();
值得注意的一点是 PrintWriter 的 close() 方法不会抛出IOException,因为在底层这个异常已经被捕捉并处理了。
PrintWriter的内部是有缓冲区的(当构造函数传入的是File类型时,内部使用的是BefferedWriter来实现的),所以需要手动调用flush()方法。但是PrintWriter的构造函数支持第二个参数:是否启用自动刷新缓冲。当设置为true后,仅当调用 println , printf , format 方法时才会生效。
IO流的选择
上面说了这么多的IO流,到底什么场景下需要该使用什么流呢?来看一张图
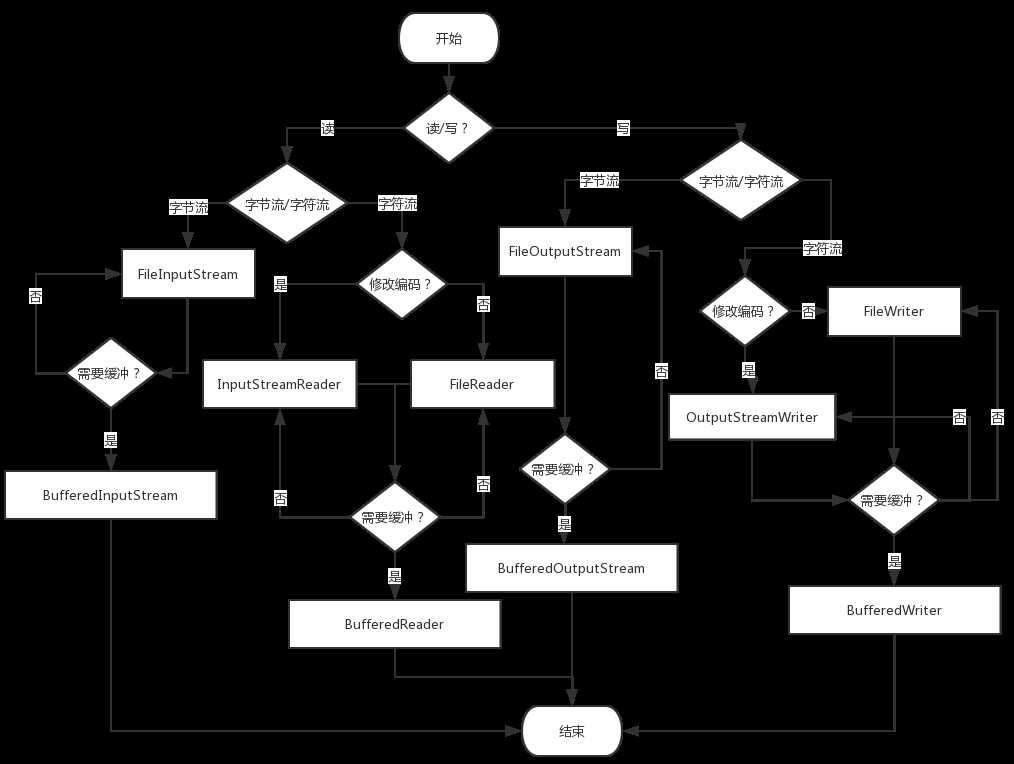
除了上面的图之外还需要在额外问自己几个问题:
- 是否需要进行序列化和反序列化操作?如果是则选择 ObjectInputStream 或 ObjectOutputStream。
- 是否需要读取Key=Value形式或者是想要存储成Key=Value形式的配置?如果是可以选择 Properties 操作起来更加方便。
- 是否需要打印指定格式的数据到输出文件?可以考虑使用 PrintWriter,其实它就是在流的基础上提供了一些更加简洁的操作。
第三方工具包
在开发中觉得写起来比较繁琐,如果不想自己封装的话,推荐一个好用的第三方工具包:commons-io。
以上是关于Java中常用IO流之文件流的基本使用姿势的主要内容,如果未能解决你的问题,请参考以下文章