字符编码常识
Posted solverpeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符编码常识相关的知识,希望对你有一定的参考价值。
基本常识:
1.位和字节
位:(bit),计算机里存放的二进制的值(0/1)。
字节:(byte),一个字节由8位组成。8个位的组合有256个组合方式,其值范围:“00000000-11111111”,常用16进制来表示。
通常所说的字符编码,就是指定义一套规则,将真实世界里的字母、字符与计算机二进制序列进行相互转化。
2.编码标准
(1) 拉丁编码(适用于美国,欧洲)
<1> ASCII编码
只支持基础拉丁字母。设计:用1个字节来表示1个字符。且最高位为0,表示字符含义的只有7位,所以可表达的字符只有128个。(适合美国人)
<2> EASCII编码
到西欧的时候,发现美国人设计的ASCII编码无法满足,所以将一个字节中的最高位也利用了起来,可表达的字符256个。
<3> ISO 8859
虽然西欧使用256个字符能满足自身使用了,但是北欧、东欧还是不够,所以就出现了ISO 8859。
不是单独的字符集编码,而是一整套。从ISO 8859-(1-16)没有12,每个字符集对应不同的区域的编码。兼容ASCII的。
以上这三种编码都是单字节编码,一个字符对应一个字节。
(2)中文编码:
但是对于字符集更大的中文来说,并不合适。(大概有8w左右),所以需要多个字节来表示一个字符的编码规则。
GB2312编码:国家简体字符集,用两个字节表示一个汉字。同样还兼容ASCII编码规则。
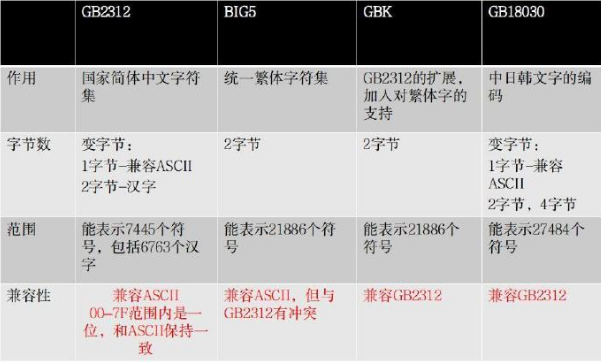
(3) Unicode 编码:全世界字符统一编码规则
Unicode 采用4字节来表示一个字符,理论上,能表示的字符数就达到2的31次,21亿左右的字符。
但是这样一来,对于中文和拉丁字母就会形成一种浪费。另外如何让计算机区分是Unicode编码还是其他编码也是需要考虑的问题。
<1>UTF-8编码:Unicode编码的一种实现。Unicode是统一编码标准规范。
编码规则:
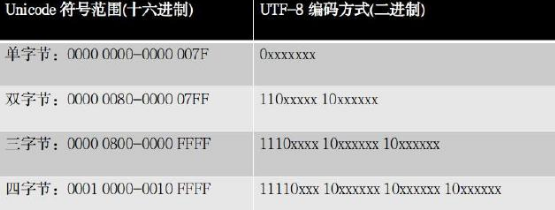
- 规则1:对于单字节字符,字节的第一位为0,后7位为这个符号的Unicode码,所以对于拉丁字母,UTF-8与ASCII码是一致的。
- 规则2:对于n字节(n>1)的字符,第一个字节前n位都设为1,第n+1位为0,后面字节的前两位一律设为10,剩下没有提及的位,全部为这个符号的Unicode编码
如图:
UTF-8 与GBK和GB2312并不完全兼容。也就是说不能通过何种方式进行转换。只能通过查表的形式来转换。
UTF-8下的中文占3个字节或4个字节,并不固定。
3.UTF-8 的BOM
Bom是微软给UTF-8加上的,用于表示文件使用的是UTF-8编码。即在UTF-8编码的文件起始位置,加入三个字节“EE BB BF”。
标准并不推荐。
参照:
http://blog.jobbole.com/76376/
https://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/
以上是关于字符编码常识的主要内容,如果未能解决你的问题,请参考以下文章