spark-shell读取parquet文件
Posted mylittlecabin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark-shell读取parquet文件相关的知识,希望对你有一定的参考价值。
1、进入spark-shell窗口
2、
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
3、
val parquetFile = sqlContext.parquetFile("hdfs://cdp/user/az-user/sparkStreamingKafka2HdfsData/part-00000-ff60a7d3-bf91-4717-bd0b-6731a66b9904-c000.snappy.parquet")
hdfs://cdp是defaultFS,也可以不写,如下:
val parquetFile2 = sqlContext.parquetFile("/user/az-user/sparkStreamingKafka2HdfsData/part-00000-ff60a7d3-bf91-4717-bd0b-6731a66b9904-c000.snappy.parquet")
4、
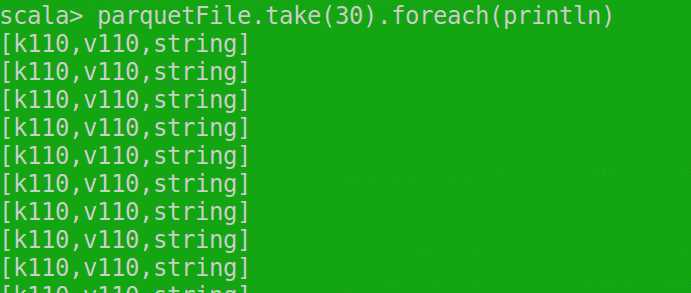
parquetFile.take(30).foreach(println)
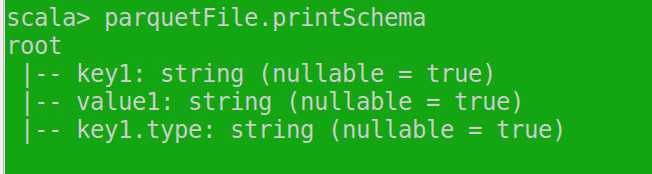
以上是关于spark-shell读取parquet文件的主要内容,如果未能解决你的问题,请参考以下文章