算法与数据结构开篇——基础与心得
Posted ideal-20
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法与数据结构开篇——基础与心得相关的知识,希望对你有一定的参考价值。
算法与数据结构开篇
你真的会数据结构吗?
公司开发一个客服电话系统,小菜需要完成客户排队模块的开发,经过三次修改:
第一次:小菜使用了数据库设计了一张客户排队表,并且设置了一个自动增长的整型id字段,来一个用户,就在这张表的末尾插入一条数据,等客服系统一空闲,就将表中最前的的客户提交,然后删除这条记录。
- 实时排队模块,在内存中实现即可,无序用数据库
第二次:小菜用数组变量重新实现了这个功能,害怕数组不够大,选择远大于实际情况的100作为数组长度
- 数组虽然可以满足一定需求,但是需要考虑溢出问题,以及新增和删除后的数据移动,显然不是很方便
第三次:小菜使用了数据结构中的 “队列结构” 终于满足了需求
说明:此例子归纳参考自《大话数据结构》
为什么你的程序比别人的慢?(算法问题)
来看一个问题:
公元前五世纪,我国古代数学家张丘建在《算经》一书中提出了“百鸡问题”:鸡翁一值钱五,鸡母一值钱三,鸡雏三值钱一。百钱买百鸡,问鸡翁、鸡母、鸡雏各几何?请设计一个“高效”的算法求解。
也就是说:
买一只公鸡要五文,买一只母鸡要三文,而一文可以买三只小鸡,共有100文,问公鸡母鸡小鸡各能买几只?
话不多说,我们先给出一种最容易想到的方式,也就是列两个三元方程组
也就是满足鸡的总数为100,同时花钱数也为100,我们来看一下代码实现
方式一:
//i j k 分别代表公鸡 母鸡 雏鸡的数量
//20、34、300 为100元最多能买公鸡、母鸡、小鸡的数量
for (int i = 0; i < 20; i++)
for (int j = 0; j < 34; j++)
for (int k = 0; k < 300; k = k + 3) //k = k + 3 是为了满足小鸡实际存在的要求
if (5*i + 3*j + k/3 == 100 && i + j + k == 100)
cout << "公鸡 母鸡 雏鸡 数量分别为:" << i <<", "<< j <<", "<< k << endl;
我们用了三层循环,有没有办法能简化以下代码呢?能不能减少循环层数呢?这显然是可行的,上面小鸡的数量这一层明显可以省略的,因为总数是已知的
方式二:
for (int i = 0; i < 20; i++)
for (int j = 0; j < 34; j++)
k_temp = 100 - i - j;
if (k_temp % 3 == 0)
k = k_temp;
if (5*i + 3*j + k/3 == 100 && i + j + k == 100)
cout << "公鸡 母鸡 雏鸡 数量分别为:" << i <<", "<< j <<", "<< k << endl;
确实程序更加优化了一些,但是这样是不是就可以了呢?其实还可以优化为一层循环!
方式三:
int i, j, k, t;
for (int t = 0; t <= 25/7; t++)
i = 4 * t;
j = 25 - 7 * t;
k = 75 + 3 * t;
cout << "公鸡 母鸡 雏鸡 数量分别为:" << i <<", "<< j <<", "<< k << endl;
上例中对程序的优化涉及到了数学的运算
//根据花钱的总数为100列式
5x + 3y + (100 - x - y)/3 = 100
//对上式进行化简
y = 25 -(7/4)x
= 25 - 2x + x/4
//设 x/4 = t,原式子可变为
y = 25 - 7t
//可以得到三个不等式
x = 4t >= 0
y = 25 - 7t >= 0
z = 75 + 3t >= 0
//解得
t >= 0
t <= 25/7为了增加说服力,我们测试每一个程序的运算时间,不太熟悉的朋友我下面已经贴出了代码
#include<ctime>
clock_t startTime,endTime;
startTime = clock();
......测试代码
endTime = clock();
cout << "The run time is: " << (double) (endTime - startTime) / CLOCKS_PER_SEC << "s" << endl; 我们将数据放大一些,方便体现差异,我们将总金额和总数量均改为1000 下面是三种方式的运算时间
The run time is: 0.114s
The run time is: 0.03s
The run time is: 0.026s很显然程序逐步的到了优化,减少了for循环 大大的减少了循环次数,所以节省了时间
为什么要一起学习数据结构和算法?
想要回答这个问题,我们先开看一下数据结构和算法的概念
数据结构概念
数据结构是指相互之间存在一种或多种特定关系数据元素的集合
也就是说,计算机在对数据进行存储的时候并不是杂乱无序的而是拥有一定规则的,一个或多个数据元素之间拥有一定的相互关系,所以也可以说数据结构是计算机存储和组织数据的方式
算法的概念
算法是一种可以被计算机使用来解决问题的的方法,这种方法也正是解决问题的具体步骤
对于小型的程序而言,即使这个算法比较差劲,解决问题的步骤比较累赘繁琐,也不会有很大的关系,只要能解决问题的就是好程序,但是如果对于数据量较大的中大型程序,我们就需要对方法的时间和空间进行有效的利用,也就是设计一个高效的算法,在同样硬件设备的情况下,有时候甚至可以将速度提高十倍甚至百倍
程序 = 数据结构 + 算法
数据结构是对计算机所存储的数据之间的一种组织管理,算法是对数据进行操作从而将你解决问题的方法在计算机中具体实现,也就是说,在计算机中而言,其实这两者单独拿出来讨论是没有什么实际意义的,就像鱼离不开水一样,即使一个优秀的算法,如果数据之间没有任何结构关系可言,算法也就无从实现,也就没有意义了,而即使数据之间有了组织关系,但是不对其进行操作这显然也没有意义。
简单总结:只有数据结构的程序是没有灵魂的,只有算法的程序却只有魂魄,没有躯体
不可否认,数据结构是非常重要的,但我更加倾向于算法为核心,正如 Algorithms(4th.Edition) 中的观点,数据结构是算法的副产品或者结果,在我看来,如何建立一个有效且高效的算法以及模型是更重要一些的,开发的最终目的就是通过程序利用科技设备实现我们实际生活中的一些需求,我们遇到问题的第一步都是在现实中对问题进行分析,然后设计出合适的方法,然后就要想办法将这种方法表达给计算机设备,但是这个时候就需要数据结构这样一种满足需要的产物,来支持我们对我们的设备具体表达我们的方法,尤其随着数据量的检验,不同的算法就会对解决实际问题的效率产生更大的影响,我用一个不是很恰当却很形象的例子表达就是:你的身体(数据结构)死了,你可能还活着,但你的灵魂(算法)死了,你即使活着也已经死了
当然数据结构的重要性也是不容置疑的,一个好的数据结构,可以帮助我们的程序更加高效,如果什么时候,模型以及算法的选用已经可以根据数据的特点以及需求选用,我们就可以将更多的精力投入到数据结构的设计中去,不过这也仅仅是一种美好的假想,所以我们还是要学好算法,但是学好算法,我们也就要对支持我们算法的数据结构进行一定的研究
说了一些个人的观点,那让我们赶紧介绍一些入门的必备知识
数据结构的基本概念和术语
数据:描述客观事物的数字和符号,是能够被计算机识别且进行处理的的符号集合
整型和实数型数据是可以直接进行数值计算的
文字、图像、图形、声音、视频等多媒体信息则可以通过合适的编码保存处理
例如:文本通过字符编码处理、声音通过储存波形 (WAV) 或在波形分解后存储其振幅特性然后压缩 (MP3)
数据元素:组成数据且有意义的的基本单位 (个体)
- 例如:猫和狗都是动物群体中的一个数据元素
数据项:组成数据元素具有特定意义的最小不可分割单位
作为人这个类群中具体的个体,一个人而言,其所拥有的手、脚、眼、鼻,亦或者姓名、年龄、身高、等都属于数据项
数据对象:性质相同的数据元素的集合,是数据的子集
- 例如:人类中一些人的生日、身高相同
逻辑结构和物理结构(存储结构)
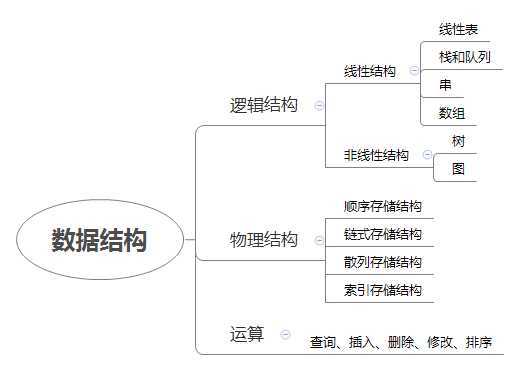
逻辑结构
逻辑结构:数据对象中数据元素之间的相互关系
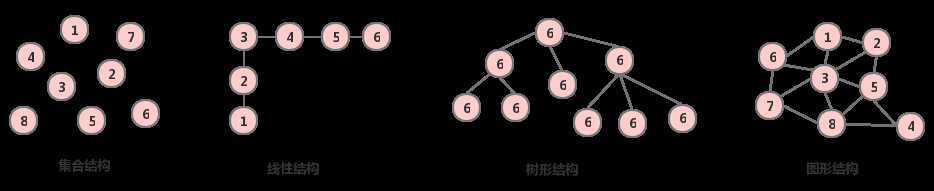
① 集合结构:数据元素之间的唯一关系就是属于同一个集合
② 线性结构:数据元素之间存在一对一的关系(除首尾元素均存在前驱和后继)
③ 树形结构:数据元素之间存在一对多的关系
④ 图形结构:数据元素之间存在多对多的关系
- (每一个数据元素看做一个节点,元素之间的逻辑关系用连线表示,如果关系有方向则连线带箭头)
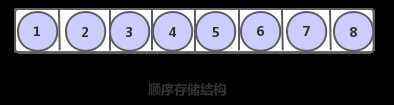
物理结构(存储结构)
物理结构:数据的逻辑结构关系在计算机中的存储形式
① 顺序存储结构:把元素分别放在地址连续的存储单元中的存储方式
- 也就是说:元素一个一个有序的排好队,各自占据一定的空间,例如定义一个含有6个浮点型数据的数组:然后内存中的一块大小为6个浮点型数据大小空间就会被计算机所开辟,然后数据存入时,依次顺序摆入
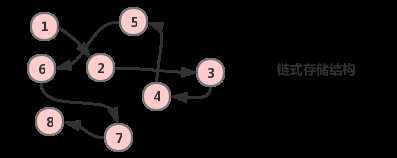
② 链式存储结构:把元素存储在任意的存储单元中的存储方式
因为数据元素位置不确定,所以需要通过指针指向到元素的存储地址,从而确定不同数据元素之间的位置
举例:200人同时在一个阶梯教室上课,同学们坐的位置是没有关系的,老师点名签到的时候,你只需要关注你学号前一位的同学有没有被点到,点到后,你就知道下一个该你了
③ 散列 (哈希) 存储方式:是一种力图将数据元素的存储位置与关键码之间建立确定对应关系的查找技术
你别慌,我这就来解释了,它的原理就是,将一个节点的关键字key作为自变量,通过一个确定的函数运算f(key),其函数值作为节点的存储地址,将节点存入到指定的位置上,查找的时候,被搜索的关键字会再次通过f(key)函数计算地址,然后读取对应数据
我们后面会专篇讲解这个内容,现在做一个简单的了解即可
④ 索引存储方式:存储时,除了存储节点,还附加建立了索引表来表示节点的地址
算法的特征
输入:算法具有零个或者多个输入(零个的情况例如打印输出字符串,或者算法自身已经给定了初始条件)
输出:算法具有一个或者多个输出,用来反映算法对输入数据加工后的结果
- 有穷性:算法必须在执行有限个步骤后终止
- “有限” 的定义不是绝对的,而是实际应用中合理的可接受的
- 确定性: 算法的每一步骤都具有确定的含义,不会出现二义性
- 也就是说,唯一的输入只有唯一的输出
可行性:算法的每一步都是可行的,通过有限步骤可以实现
算法的设计要求
正确性:合理的数据输入下,最终可以输出能解决问题需求的正确答案
- 对正确的理解:
- 无语法错误
- 输入合法和非法的数据均可以得到正确答案
- 输入刁难的数据依旧可以输出满足需要的答案
- 对正确的理解:
可读性:算法便于阅读和理解
算法应该层次分明,易读易懂,方便二次调试和修改
复杂一些的算法,变量的命名尽量恰当一些,用阿里的开发手册中的一句话就是说:“正确的英文拼写和语法可以让阅读者易与理解避免歧义”,“为了达到代码自解释的目标,任何自定义编程元素在命名时,使用尽量完整的单词组合来表达其意”
健壮性:当数据不合理的时候,算法也能对各种情况作出处理,而不是报出异常,或者输出错误的答案
高效性:尽量满足时间效率高,存储率低的需求
函数的渐进增长
| 次数 | 算法A :2n + 4 | 算法B :3n + 3 | 算法C :2n | 算法D :3n |
|---|---|---|---|---|
| n = 1 | 6 | 6 | 2 | 3 |
| n = 2 | 8 | 9 | 4 | 6 |
| n = 3 | 10 | 12 | 6 | 9 |
| n = 10 | 24 | 33 | 20 | 30 |
| n = 100 | 204 | 303 | 200 | 300 |
n = 1的时候 算法 A 和 B 的效率一致,但是从n = 2的时候开始算法 A 的效率已经大于算法 B 了,n值变大后,算法 A 相比 B 变的更加快速
-所以在n值没有限定的情况下,只要在超过某数值N后,函数值就一直大于另一个函数,那么我们称函数是渐进增长的
函数的渐近增长:给定两个函数f(n)和g(n),如果存在一个整数N,使得对于所有的n > N,f(n)总是比g(n)大,那么,我们说f(n)的渐近增长快于g(n)
接着我们分别用 AC 、BD进行对照,你会发现其实后面的加数对算法的影响几乎是忽略不计的,所以我们一般选择忽略这些加法常数
| 次数 | 算法A :2n + 6 | 算法B :3n2 + 3 | 算法C :n | 算法D :n2 |
|---|---|---|---|---|
| n = 1 | 8 | 6 | 1 | 1 |
| n = 2 | 10 | 15 | 2 | 4 |
| n = 3 | 12 | 30 | 3 | 9 |
| n = 10 | 26 | 303 | 10 | 100 |
| n = 100 | 206 | 30003 | 100 | 10000 |
算法 A 和 B 比较的时候,n = 1的时候 B效率更高,从n = 2开始 算法 A 就比较高效,随着数据的输入,体现的越明显,但是我们同时将这两个算法去掉最高次项的系数,接着可以看到对数据的走向仍然影响不大
最高次项的系数对数据走向的影响不大
最高项的指数大的函数,随着n的增长,结果也会快速增长
判断算法效率的时候,应主要关注最高次项,其他次要项或者常数项常常可以忽略
算法的时间复杂度
算法的时间复杂度是一个函数 T(n),它定性描述该算法的运行时间,通常用大O表示法,记作:T(n) = O(f(n)) 例如3n2 + 2n + 1 的时间复杂度为 O(n2)
注意:
T(n) = O(f(n)) 解释:随着n增大算法执行时间的增长率和f(n)的增长率相同,同时也考察输入值大小趋于无穷的情况,也称作算法的渐进时间复杂度
在这个过程中,不考虑函数的低阶项、常数项和最高项系数,
常见的时间复杂度
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2^n) < O(n!) < O(n^n)
实际开发中,我们常见到的还是前几个加粗的
我们还需要提到两个概念:
最坏情况与平均情况
最坏情况就是,运行时间的最大值,情况不能再坏了
平均时间就是
一般情况下,我们都是指最坏时间复杂度,但平均时间是最有意义的时间,因为它与我们的期望值更接近
作者的话
这些文章,当然谈不上算什么有深度的技术,但是我在尽可能的将一些概念通过举例、图表等方式给对这方面知识有需要的朋友,快速的入门,通过一些通俗的说法,先对一些知识有一定的了解,在此基础上,去看一些深入的权威书籍,或者大牛的博文,就会不至于劝退,自知技术有限,但仍然想给一些刚刚接触这部分知识的朋友们一些帮助,总得一个人,经历一些难捱的日子,你才会变得更加强大!
结尾:
如果文章中有什么不足,或者错误的地方,欢迎大家留言分享想法,感谢朋友们的支持!
如果能帮到你的话,那就来关注我吧!如果您更喜欢微信文章的阅读方式,可以关注我的公众号
在这里的我们素不相识,却都在为了自己的梦而努力 ?
一个坚持推送原创Java技术的公众号:理想二旬不止

以上是关于算法与数据结构开篇——基础与心得的主要内容,如果未能解决你的问题,请参考以下文章