将postgresql中的数据实时同步到kafka中
Posted cq-yangzhou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了将postgresql中的数据实时同步到kafka中相关的知识,希望对你有一定的参考价值。
参考地址:https://blog.csdn.net/weixin_33985507/article/details/92460419
参考地址:https://mp.weixin.qq.com/s/sccRf9u0MWnHMsnXjlcRGg
一、安装kafkacat
kafkacat 是一个C语言编写的 kafka 生产者、消费者程序。
安装kafkacat 之前,需要安装一下依赖
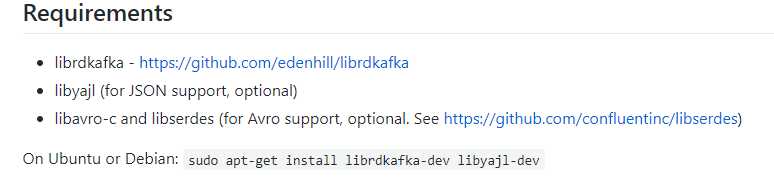
sudo apt-get install librdkafka-dev libyajl-dev
二、重点是安装avro-c
安装avro-c的依赖
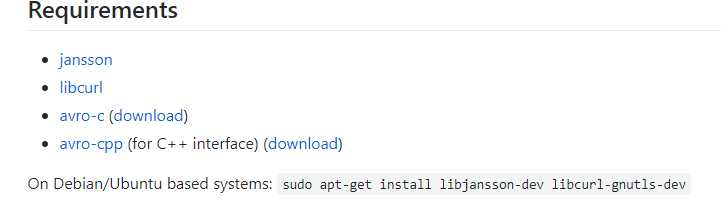
(1)、 其中安装libcur时会出错,因此先执行
sudo apt-get install libjansson-dev
(2)、接着安装aptitude(若没有安装)
apt install aptitude
(3)、安装curl
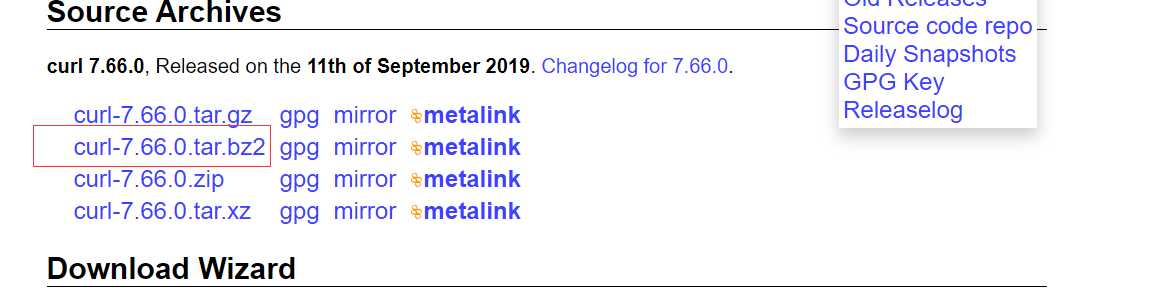
tar jxvf curl-7.66.0.tar.bz2
cd curl-7.66.0
./configure
make
make insall
安装完成之后将curl-7.66.0/include/curl 目录拷贝到/usr/include目录下面(需要包含curl 目录)
sudo cp -r /home/yzh/curl-7.66.0/include/curl /usr/include
(4)、安装zlib
sudo apt install zlib1g-dev
(5)、安装snappy
sudo apt install libsnappy-dev
(6)、安装PkgConfig
sudo apt install pkg-config
(7)、安装liblzma
sudo apt install liblzma-dev
(8)、安装cmake
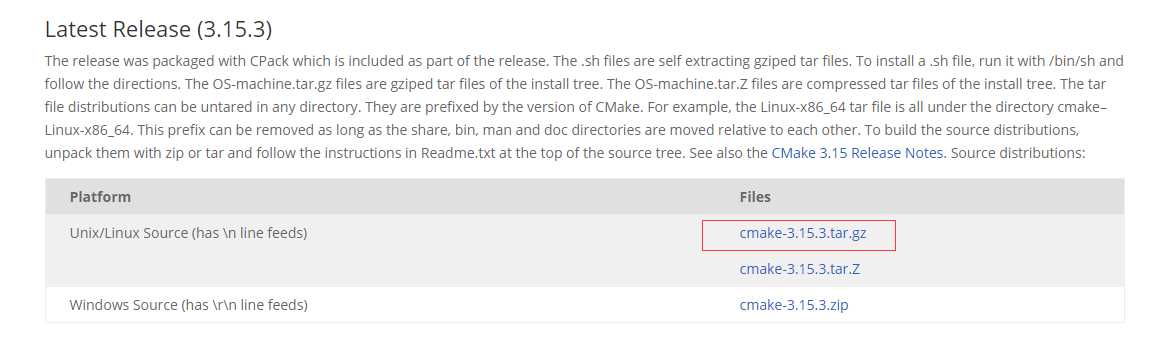
tar zxvf cmake-3.15.3.tar.gz cd cmake-3.15.3 ./bootstrap make make install cmake -version cmake version 3.15.3 CMake suite maintained and supported by Kitware (kitware.com/cmake).
(9)、安装avro-c
需要root用户
tar -zvxf avro-c-1.9.1.tar.gz cd avro-c-1.9.1/ mkdir build cd build cmake .. -DCMAKE_INSTALL_PREFIX=/opt/avro -DCMAKE_BUILD_TYPE=Release -DTHREADSAFE=true make make test make install
导入库文件
# vi /etc/ld.so.conf /opt/avro/lib # ldconfig
安装完成之后,需要将/opt/avro(安装时指定的路径 )中的相关文件拷贝到/usr相关路径下面
cp -r /opt/avro/lib/* /usr/lib cp -r/opt/avro/include /usr/include
三、安装libserdes
git clone https://github.com/confluentinc/libserdes cd libserdes ./configure make sudo make install
四、安装kafkacat
git clone https://github.com/edenhill/kafkacat ./configure make sudo make install
安装之后,需要添加环境变量
sudo vim /etc/profile exoprt LD_LIBRARY_PATH=/usr/local/lib export PATH=$PATH:$LD_LIBRARY_PATH
五、安装wal2json
git clone https://github.com/eulerto/wal2json cd wal2json make sudo make install
六、修改postgresql相关配置文件
posgresql.conf
shared_preload_libraries = ‘wal2json‘ wal_level = logical max_wal_senders = 4 max_replication_slots = 4
创建具有Replication和Login授权的用户
CREATE ROLE <name> REPLICATION LOGIN;
修改pg_hba.conf,使该用户可以远程或本地访问数据库
############ REPLICATION ############## local replication <name> trust host replication <name> 127.0.0.1/32 trust host replication <name> ::1/128 trust
七、测试
1、建立测试环境(创建的表必须要有主键)
CREATE DATABASE test; CREATE TABLE test_table ( id char(10) NOT NULL, code char(10), PRIMARY KEY (id) );
2、创建slot
pg_recvlogical -h localhost -p 5432 -U postgres -d testdb --slot test_slot --create-slot -P wal2json
3、启动zookeeper、kafka(略)
5、启动slot
pg_recvlogical -h localhost -p 5432 -U postgres -W -d testdb -S test_slot(对应创建的slot) --start -f - | kafkacat -b 127.0.0.1:9092 -t testdb_topic
6、消费testdb_topic
bin/kafka-console-consumer.sh --topic testdb_topic --bootstrap-server 127.0.0.1:9092 --from-beginning

以上是关于将postgresql中的数据实时同步到kafka中的主要内容,如果未能解决你的问题,请参考以下文章