目标检测---搬砖一个ALPR自动车牌识别的环境
Posted carle-09
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测---搬砖一个ALPR自动车牌识别的环境相关的知识,希望对你有一定的参考价值。
目标检测---搬砖一个ALPR自动车牌识别的环境
参考
License Plate Detection and Recognition in Unconstrained Scenarios
@https://www.cnblogs.com/greentomlee/p/10863363.html
@https://github.com/sergiomsilva/alpr-unconstrained
环境
The current version was tested in an Ubuntu 16.04 machine, with Keras 2.2.4, TensorFlow 1.5.0, OpenCV 2.4.9, NumPy 1.14 and Python 2.7.
OpenCV各版本差异与演化,从1.x到4.0
@https://www.cnblogs.com/shine-lee/p/9884551.html
搭建一个虚拟环境隔离python, opencv的不同版本:Ubuntu 16.04 + Keras 2.2.4 + TensorFlow 1.5.0 + OpenCV 2.4.9 + NumPy 1.14 + Python 2.7.
(1)激活虚拟环境
u@u160406:~/Virtualenv/py2$ source bin/activate
(py2) u@u160406:~/Virtualenv/py2$
(2)opencv-python
自动安装opencv
python -m pip install opencv-python
pip install opencv-python
pip install opencv-contrib-python
安装的是最新版本的opencv (这里Successfully installed opencv-python-4.1.1.26)
查看版本python
import cv2
cv2.__version__
>>> 4.1.1
没有opencv 2.x版本的
python -m pip install opencv-python==2.4.9
ERROR: Could not find a version that satisfies the requirement opencv-python==2.4.9 (from versions: 3.1.0.0, 3.1.0.1, 3.1.0.2, 3.1.0.3, 3.1.0.4, 3.1.0.5, 3.2.0.6, 3.2.0.7, 3.2.0.8, 3.3.0.9, 3.3.0.10, 3.3.1.11, 3.4.0.12, 3.4.0.14, 3.4.1.15, 3.4.2.16, 3.4.2.17, 3.4.3.18, 3.4.4.19, 3.4.5.20, 3.4.6.27, 3.4.7.28, 4.0.0.21, 4.0.1.23, 4.0.1.24, 4.1.0.25, 4.1.1.26)
卸载
pip install opencv-python
pip uninstall opencv-contrib-python-4.1.1.26
(2‘)手动安装opencv
1、下载
wget -O opencv.zip https://github.com/Itseez/opencv/archive/2.4.9.zip
wget -O opencv-3.3.0.zip https://github.com/opencv/opencv/archive/2.4.9.zip
contrib库:https://github.com/opencv/opencv_contrib/releases
opencv版本:https://opencv.org/releases.html
opencv2.x 自带contrib库,contrib库从opencv 3.x+版本已经独立出来,所以opencv2.x 不用下载opencv_contrib.zip, 下载也找不到资源。
opencv2.x安装不用在单独安装contrib库,opencv 3.x+需要单独安装contrib库
wget -O opencv_contrib.zip https://github.com/Itseez/opencv_contrib/archive/2.4.9.zip
wget -O opencv-3.3.0.zip https://github.com/opencv/opencv_contrib/archive/2.4.9.zip
2、进入到OpenCV的文件夹中,创建一个build目录,进行编译:
cd opencv-2.4.9
mkdir build
3、进入build目录:
cd build
opencv 2.x 貌似不支持CUDA,cmake一直报错,最后如下命令通过:
cmake选项:
cmake .. -DCMAKE_BUILD_TYPE=Release -DCUDA_nppi_LIBRARY=true -DWITH_CUDA=OFF ..
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/home/u/Virtualenv/py2/local/ -D PYTHON_EXECUTABLE=/home/u/Virtualenv/py2/bin/python -D PYTHON_PACKAGES_PATH=/home/u/Virtualenv/py2/lib/python2.7/site-packages ..
4、开始编译:make -j4
5、安装: sudo make install
6、测试是否安装成功
python
>>>import cv2
>>> cv2.__version__
‘2.4.9‘
(3)退出虚拟环境
(py2) u@u160406:~/Virtualenv/py2/cars-LPR$ deactivate
(4)因为在虚拟环境中装opencv,因为没有在系统中配置opencv环境变量。
重启电脑,查看opencv版本是否还可用
u@u160406:~/Virtualenv/py2$ source bin/activate
(py2) u@u160406:~/Virtualenv/py2$ python
Python 2.7.12 (default, Nov 12 2018, 14:36:49)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
‘2.4.9‘
>>> 可用
*************************************************************************************************************************************************
@https://blog.csdn.net/ELEVEN_ZOU/article/details/80893579
@https://www.cnblogs.com/greentomlee/p/10863363.html
一、WHAT
论文下载地址:License Plate Detection and Recognition in Unconstrained Scenarios [pdf]
github 的项目地址:alpr-unconstrained
数据集: http://www.inf.ufrgs.br/~crjung/alpr-datasets.
工程主页:alpr-datasets
视频效果: Demi Lovato Rock in Riio Lisboa 2018
本文选自ECCV2018的论文《License Plate Detection and Recognition in Unconstrained Scenarios ( 复杂| 无约束 场景下的车牌检测和识别)》。该论文不进给出了一套完整的车配识别系统( Automatic License Plate Recognition system,ALPR system)的解决方案,而且提供了在无约束(Unconstrained Scenarios)场景下的识别算法, 很好的解决了实际生活中的车牌识别问题。
1. 引入新颖的CNN,可以检测和纠正单一图像中的多个失真的车牌,将纠正后的车牌图片送入ocr方法中,得到最后的车牌文字
2. 对来自不同区域的车牌进行了人工标注:使用一个由真是数据和人工生成的数据组成的车牌进行训练, 并使用与目标区域相似的字体类重新训练ocr网络
3.扩展了现有的OCR方法,针对巴西车牌进行开发。
结果: 不仅仅在巴西车牌上的准确率很高,在欧洲和台湾车牌生也获得了很高的召回率和准确率
PS: 台湾车牌和欧洲车牌是由数组和字母构成的,其实和巴西车牌的构成是一样的,唯一所有不同的是车牌图像的比例可能会有所不同。但这种图像预处理的时候统一设置图片就好了
二、WHY
常见的商业软件大多是在场景受限的情况下对车牌进行识别的,例如停车场、收费站的监控,这些场景都很固定,摄像的角度和车牌 但是对于宽松的场景,比如执法人员手中的相机或者是智能机拍下的图片,照片的倾斜度可能会很高,对于这些商业软件而言,识别起来就很困难。
因此,本论文提出一个完整的ALPR系统,可以在多变的场景下表现良好。
总的来说就是: 目前很多ALPR系统对正面拍摄车牌照片识别效果良好,但是在多变的角度和场景(光线)下车牌往往是倾斜的,导致识别的效果并不如意。因此,本论文提出一个完整的ALPR系统,可以在多变的场景下表现良好。

数据集中存在的倾斜车牌
基于此,这篇文章提出了一种完整的ALPR系统,可以在各种场景下具有良好的表现。在这篇文章的贡献主要有两个:
1. 介绍了一种新颖的神经网络,能够检测出不同场景环境下的车牌;并在OCR之前对变形的进行校正。
2. 利用真实数据合成多样的车牌,用于训练。手动标注的样本了少于200个,并且是从头开始训练网络。
三、HOW(实现方法)
ALPR 的主要任务是 在图像中找到并识别车牌(license plates );通常情况下会分为4个子任务序列:
- 车辆检测( vehicle detection)
- 车牌检测( license plate detection)
- 字符分割( character segmentation)
- 字符识别( character recognition)
而子任务3和4可以看做OCR; 所以一共有3个子任务:vehicle detection, license plate detection, OCR. 这篇文章也是按照这三个子任务的顺序进行展开的,如下图所示。
具体的说就是:基于YOLOv3 的车辆识别 --> 车牌的检测和校正--> 车牌的OCR识别:
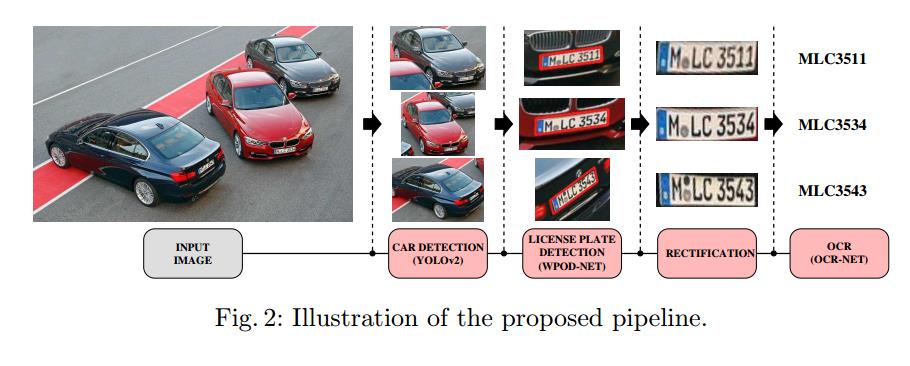
示例流程
问题1: 为什么要先检测出车辆,再检测出车牌?而不是直接检测车牌呢?
根据经验,较大的输入图像上是可以检测较小的物体,但是这会增加了计算量。车牌属于小目标的检测,通常情况下在有车的图片上,往往会伴随着车牌,(即:有车牌的地方一定能检测出车辆),所以可以先检测车辆。
问题2: 为什么对车牌进行校正?
这是因为在正视图上,车牌的大小和车辆的bounding box 的比例较大;而在斜视图或者侧视图上,车牌大小和车辆的比例较小。因此,需要将倾斜的视图调整到正面的视图上,以保持车牌区域的可识别性。 简而言之就是:倾斜视角的车牌面积较小,将车牌变成正视图的视角后,车牌面积会增大,从而增加车牌的识别率。

倾斜视角的车牌面积较小,将车牌变成正视图的视角后,车牌面积会增大,从而增加车牌的识别率。
问题3: 车牌的校正是如何实现的?
在车牌校正方面,虽然3D姿态估计是方法可以确定校正的尺寸和调整的尺度,但是本文提出了一种基于车辆bounding box的纵横比(aspect ratio)的一种方法,简单又高效。首先需要设置resizing factor,即当bounding box的aspect ratio接近于1的时候,影响因子会较小;当aspect ratio 增加的时候,影响因子也会增加。
缩放因子的计算方式如下:
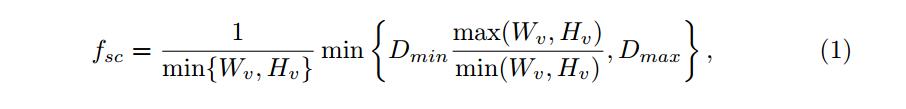
(1)中,Wv和 Hv是识别车辆后的图像大小, Dmin和Dmax是常量,分别是288和608
其中:Wv和Hv是车辆的bounding box的宽度和高度。
注意: 由于Dmin ≤ fsc min(Wv, Hv) ≤ Dmax,所以Dmin和Dmax为调整车辆图片的维度大小划定了范围,经过尝试之后最佳的值是Dmin=288; Dmax=608
fsc代码实现如下:

1 Ivehicle = cv2.imread(img_path) # vehicle bounding box
2
3 ratio = float(max(Ivehicle.shape[:2]))/min(Ivehicle.shape[:2]) # 计算缩放比例
4 side = int(ratio*288.)
5 bound_dim = min(side + (side%(2**4)),608) # fsc
6 print "\\t\\tBound dim: %d, ratio: %f" % (bound_dim,ratio)
7
8 factor = float(max_dim)/min_dim_img
9 print "\\t Fsc is %f"%(factor)
缩放因子用于计算后期的图像的宽高:
1 # wpod_net前期对车辆的bounding box 的归一化
2 # 详情见:def detect_lp(model,I,max_dim,net_step,out_size,threshold):
3 def detect_lp(model,I,max_dim,net_step,out_size,threshold):
4 ‘‘‘
5 :param model: 车牌检测模型,wpod_net
6 :param I: 车辆图片,im2single(Ivehicle),W,H,C
7 :param max_dim: bound_dim
8 :param net_step:2**4
9 :param out_size:(240,80)
10 :param threshold:lp_threshold==0.5
11 :return:
12 ‘‘‘
13
14 min_dim_img = min(I.shape[:2])# [W,H,C]-->[W,H]
15 factor =.....# 计算的缩放因子
16
17 w,h = (np.array(I.shape[1::-1],dtype=float)*factor).astype(int).tolist()# [w,h,c]
18 w += (w%net_step!=0)*(net_step - w%net_step)
19 h += (h%net_step!=0)*(net_step - h%net_step)
20 Iresized = cv2.resize(I,(w,h))# 车辆图片做缩放
21
22 T = Iresized.copy()
23 T = T.reshape((1,T.shape[0],T.shape[1],T.shape[2]))
24
25 start = time.time() # 获取时间
26 Yr = model.predict(T) # 预测的车牌区域
27 Yr = np.squeeze(Yr)
28 elapsed = time.time() - start
29 ....(略)#后期是放射变换,校正车牌的
30
31
3.1车辆的检测
车辆检测所需要的数据集是:Cars Dataset
考虑车辆的检测的需要使用的较少的时间,于是借用了YUOLOv3的模型与darknet框架进行检测的;
使用 YOLOv3的主要原因是:
1 . 检测速度很快(大约是70 FPS );
2. 识别的准确率较高,在PASCAL VOC数据集中的测试结果是76.8% mPA.
在这篇文章中,将YOLOv3直接拿来使用,并没有做性能上的改进,同时忽略了除了cars以外的其他类别;
PS :
Yolov3 相比于Faster RCNN 确实很快,但是也有致命的缺陷: 不能识别出特别小的物体。如果在实际应用中需要在一张很大的图像上识别很小的车,建议重新训练
另外,YOLOv2 中具有车牌的物体不仅仅是cars, 还有bus和truck;这两个类别在程序中确被忽略的。
使用YOLOv2 用于车辆检测:本文没有对YOLO进行更改和改进,只是将网络该网络作为车辆检测的工具,将汽车和公交车这两类进行合并,忽略了yolo里面的其他类别。
将检测出的车辆图片裁剪并且进行调整,作为车牌识别的输入。
测出的正样本(车辆),将会被resized ,送入车牌检测模块。resize 因子已经在上一节给出,通过这种缩放计算以后,包含有车辆的图片会被统一成大小为 288*608大小的图片;
3.2 车牌的检测和校正(License Plate Detection and Unwarping)
车牌检测所需的数据集是 SSIG License Plate Character Segmentation Database 和 AOLPR
车牌本质上是附加在车上的矩形平面物体。为了充分的利用车牌的形状优势,本文提出了一种 扭曲平面检测网络(Warped Planar Object Detection Network., WPOD NET)。该网络可以学习识别不同扭曲程度的车牌,并学习回归仿射变换的系数,将就扭曲的车牌unwarps成正面视图下的矩形形状。WOPD的检测流程如下图所示。
经过WPOD网络之后是一个8通道的特征图(图片中显示的是6通道,应该是8)
在特征图上提取扭曲的车牌,首先会设置固定大小的单元(m, n)
如果该单元的目标概率大于给定的阈值(threshold),那么部分回归参数用于构建放射变换矩阵,将虚拟正方形区域转换成车牌的区域
该网络的结构总共21层卷积,其中14层是内部残差块(ResBlock);所有的卷积核大小均为固定大小的3*3;除了识别块(Detection)以外,其他的激励函数全部是ReLu;包含有4个2*2大小的max pooling,stride=2,这样可以使得输入的维度减少了16倍(2*2*4);最后在识别模块有两个并行的卷积层
具体结构如下图(fig4)所示,左侧是网络的整体结构,右侧是ResBlock和Detection块的结构。
可以看出来,在检测出车牌以后,还会对倾斜的车牌进行校正;现在需要关注的部分有两点:
1. WPOD是如何设计的?
2. 如何进行车牌校正的?
3. 为什么会在最后一层使用两个并行的卷积层?
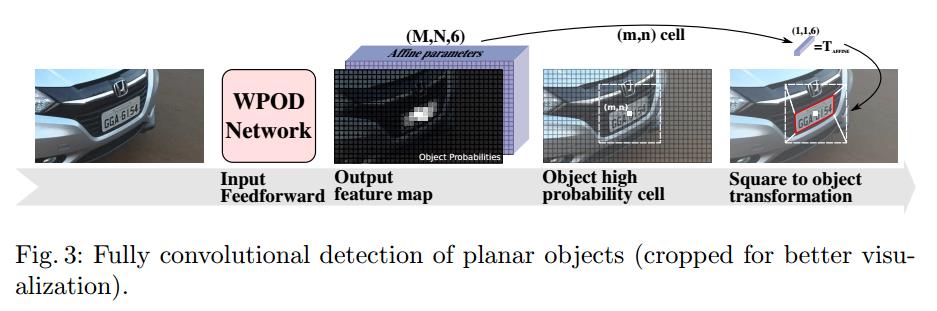
检测车牌的整个流程
问题1. WPOD是如何设计的?
好,回答第一个问题: WPOD的设计:
网络结构如下,可以看出:整个网络是 Conv( 包含res-block ) +Maxpooling +DETECTION构成的; 一共有21个卷积层,其中14个是residual blocks,所有的卷积层的filter/kernal大小都是3*3;并且每个Conv操作都会使用到ReLu; 另外有4个Maxpooling的,kernel=2*2, stride=2,
DETECTION上是两个并行的网络(粉红色的区域); 第一个是使用softmax函数去推断概率; 第二个是回归仿射参数,而不需要激活,使用恒等式F(X)=x作为激活函数
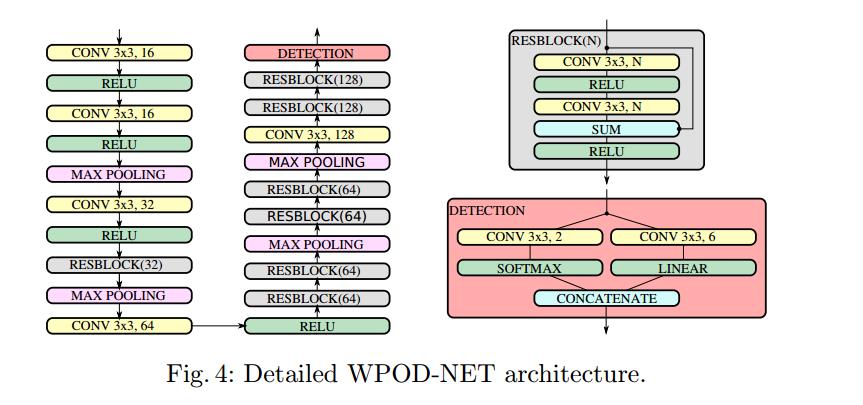
WPOD net 结构详情
1 # 为了书写方便,将conv+bn+relue封装在一个函数里面
2 def conv_batch(_input,fsz,csz,activation=‘relu‘,padding=‘same‘,strides=(1,1)):
3 output = Conv2D(fsz, csz, activation=‘linear‘, padding=padding, strides=strides)(_input)
4 output = BatchNormalization()(output)
5 output = Activation(activation)(output)
6 ## 最后两层的书写方式:
7 def end_block(x):
8 xprobs = Conv2D(2, 3, activation=‘softmax‘, padding=‘same‘)(x)
9 xbbox = Conv2D(6, 3, activation=‘linear‘ , padding=‘same‘)(x)
10 return Concatenate(3)([xprobs,xbbox])
11
12 ## model的构建
13 def create_model_eccv():
14
15 input_layer = Input(shape=(None,None,3),name=‘input‘)
16
17 x = conv_batch(input_layer, 16, 3)
18 x = conv_batch(x, 16, 3)
19 x = MaxPooling2D(pool_size=(2,2))(x)
20 x = conv_batch(x, 32, 3)
21 x = res_block(x, 32)
22 x = MaxPooling2D(pool_size=(2,2))(x)
23 x = conv_batch(x, 64, 3)
24 x = res_block(x,64)
25 x = res_block(x,64)
26 x = MaxPooling2D(pool_size=(2,2))(x)
27 x = conv_batch(x, 64, 3)
28 x = res_block(x,64)
29 x = res_block(x,64)
30 x = MaxPooling2D(pool_size=(2,2))(x)
31 x = conv_batch(x, 128, 3)
32 x = res_block(x,128)
33 x = res_block(x,128)
34 x = res_block(x,128)
35 x = res_block(x,128)
36
37 x = end_block(x)
38
39 return Model(inputs=input_layer,outputs=x)
40 ##
res_block的实现:
1 def res_block(x,sz,filter_sz=3,in_conv_size=1):
2 xi = x
3 for i in range(in_conv_size):
4 xi = Conv2D(sz, filter_sz, activation=‘linear‘, padding=‘same‘)(xi)
5 xi = BatchNormalization()(xi)
6 xi = Activation(‘relu‘)(xi)
7 xi = Conv2D(sz, filter_sz, activation=‘linear‘, padding=‘same‘)(xi)
8 xi = BatchNormalization()(xi)# xi 的通道和x的通道是一样的
9 xi = Add()([xi,x]) ## 这里是矩阵的加法
10 xi = Activation(‘relu‘)(xi)
11 return xi
问题2. 车牌区域是如何校正的?
如下图所示,WPOD Net本身是没有纠正车牌的能力;
作者是构建仿射矩阵,将虚拟方框(白色的方框)转换为lp区域。 WPOD net会输出一个8-channel的feature map,以及编码对象的概率和放射变换的参数。为了能够获取扭曲的车牌,首先在box的中心设置一个固定大小的虚框。如果以(m,n)单元为中心的虚框的目标概率大于检测的阈值,说明白色方框覆盖的区域里 有车牌,同时为扭曲的车牌进行仿射变换。

1 # inference
2 Ivehicle = cv2.imread(img_path) # vehicle bounding box; 读取读取车辆图片(根据bounding box裁剪)
3 factor= ...# 计算缩放因子
4 w,h = ... # 根据缩放因子和车辆图像计算w和h
5 Iresized = cv2.resize(I,(w,h))# 车辆图片做缩放
6
7 T = T.reshape((1,T.shape[0],T.shape[1],T.shape[2]))
8 Yr= model.predict(T) # 预测的车牌区域
9 # reconstruct
10 Yr=Y
11 Probs = Y[...,0] # 模型的预测结果的概率
12 Affines = Y[...,2:] # 仿射变换的
13 xx,yy = np.where(Probs>threshold)#threshold=0.5
14
15 base = lambda vx,vy: np.matrix([[-vx,-vy,1.],[vx,-vy,1.],[vx,vy,1.],[-vx,vy,1.]]).T # 构建放射矩阵
16
17 for i in range(len(xx)):
18 y,x = xx[i],yy[i]
19 affine = Affines[y,x]
20 prob = Probs[y,x]
21
22 mn = np.array([float(x) + .5,float(y) + .5])
23
24 A = np.reshape(affine,(2,3))
25 A[0,0] = max(A[0,0],0.)
26 A[1,1] = max(A[1,1],0.)
27
28 pts = np.array(A*base(vxx,vyy)) #*alpha
29 pts_MN_center_mn = pts*side
30 pts_MN = pts_MN_center_mn + mn.reshape((2,1))
31
32 pts_prop = pts_MN/MN.reshape((2,1))
33
34 labels.append(DLabel(0,pts_prop,prob))
35
36 ... #仿射变换end
37
对扭曲车牌检测的效果图:

问题3. 为什么会在最后一层使用两个并行的卷积层?
到现在为止,我们还没有回答这个网络的最关键的问题:文中提到的warp net放射变换参数是从哪里得到的?
网络最后的并行卷积层有着不同的使命:
第一个卷积模块是:用于计算物体的概率的,使用了softmax作为激励函数。
第二个卷积模块是:用于获取仿射参数的,没有使用激励函数
两个卷积学习的目标是根据Loss function 而定的,因此还需要知道loss function 是如何实现的。

第一个卷积模块是:用于计算物体的概率的,使用了softmax作为激励函数。
第二个卷积模块是:获取仿射参数的,没有使用激励函数

Loss Function 的设计:
假设
问题4. 如何实现仿射变换的?仿射变换恢复的扭曲图片和3D恢复的扭曲图片有什么区别?
1.解释仿射变换
2. 解释仿射变换实现的车牌校正
3. 解释仿射变换与3D扭曲图片之间的区别
3.3 车牌的OCR识别
这部分字符分割和识别是使用改进的YOLO模型。
所使用的改进方法和网络架构和这篇文章一样:Silva, S.M., Jung, C.R.: Real-time brazilian license plate detection and recognition using deep convolutional neural networks. In: 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI). pp. 55–62 (Oct 2017). https://doi.org/10.1109/SIBGRAPI.2017.14
数据集是通过使用合成和扩增数据来处理世界各地不同区域的LP特征,在该工作中大大地扩大了训练数据集。 人工创建的数据包括将7个字符的字符串粘贴到纹理背景上,然后执行随机转换,如旋转、平移、噪声和模糊。
车牌数据集的制作流程如下图所示:

制作好的数据如下入所示:

这种综合数据的使用极大地提高了网络的泛化能力,使得完全相同的网络对世界不同地区的LPs都有很好的应用效果。
这部分涉及OCR , 后期会专门设置一个专题阐述OCR的识别算法
四、总结
这篇论文的实用性应该较高;但就创新性而言,并没有太多改进。值得一提的是对扭曲的车牌进行了仿射变换,使得车牌可以恢复正常矩形的形状 。
在论文的最后,作者给出测试的结果,通过对比5中不同的车牌检测数据集可以看出这篇论文的综合测试的正确率较高。

五、附录
5.1 检测车辆
1 1 mkdir tmp # 创建临时存储的文件夹
2 2 # 检测车辆,第一个参数是检测图片所在的目录, 第二个参数将检测的车辆保存的目录
3 3 python vehicle-detection.py ./samples/test/ ./tmp
5.2 检测车牌
1 python license-plate-detection.py ./tmp/ ./data/lp-detector/wpod-net_update1.h5
输出的日志:
1 Searching for license plates using WPOD-NET
2 Processing ./tmp/03033_0car.png
3 Bound dim: 476, ratio: 1.606780
4 Processing ./tmp/03016_0car.png
5 Bound dim: 606, ratio: 2.052117
6 Processing ./tmp/03071_0car.png
7 Bound dim: 608, ratio: 2.156250
8 Processing ./tmp/03057_0car.png
9 Bound dim: 526, ratio: 1.804819
10 Processing ./tmp/03066_0car.png
11 Bound dim: 544, ratio: 1.889503
12 Processing ./tmp/03058_0car.png
13 Bound dim: 346, ratio: 1.159664
14 Processing ./tmp/03066_1car.png
15 Bound dim: 490, ratio: 1.685950
16 Processing ./tmp/03066_2car.png
17 Bound dim: 608, ratio: 2.135135
18 Processing ./tmp/03025_0car.png
19 Bound dim: 568, ratio: 1.958333
20 Processing ./tmp/03058_1car.png
21 Bound dim: 372, ratio: 1.288136
22 Processing ./tmp/03009_0car.png
23 Bound dim: 526, ratio: 1.802211
24 Processing ./tmp/03009_1car.png
25 Bound dim: 608, ratio: 3.037433
5.3 ocr识别
1 python license-plate-ocr.py ./tmp
2
3 # log
4 layer filters size input output
5 0 conv 32 3 x 3 / 1 240 x 80 x 3 -> 240 x 80 x 32 0.033 BFLOPs
6 1 max 2 x 2 / 2 240 x 80 x 32 -> 120 x 40 x 32
7 2 conv 64 3 x 3 / 1 120 x 40 x 32 -> 120 x 40 x 64 0.177 BFLOPs
8 3 max 2 x 2 / 2 120 x 40 x 64 -> 60 x 20 x 64
9 4 conv 128 3 x 3 / 1 60 x 20 x 64 -> 60 x 20 x 128 0.177 BFLOPs
10 5 conv 64 1 x 1 / 1 60 x 20 x 128 -> 60 x 20 x 64 0.020 BFLOPs
11 6 conv 128 3 x 3 / 1 60 x 20 x 64 -> 60 x 20 x 128 0.177 BFLOPs
12 7 max 2 x 2 / 2 60 x 20 x 128 -> 30 x 10 x 128
13 8 conv 256 3 x 3 / 1 30 x 10 x 128 -> 30 x 10 x 256 0.177 BFLOPs
14 9 conv 128 1 x 1 / 1 30 x 10 x 256 -> 30 x 10 x 128 0.020 BFLOPs
15 10 conv 256 3 x 3 / 1 30 x 10 x 128 -> 30 x 10 x 256 0.177 BFLOPs
16 11 conv 512 3 x 3 / 1 30 x 10 x 256 -> 30 x 10 x 512 0.708 BFLOPs
17 12 conv 256 3 x 3 / 1 30 x 10 x 512 -> 30 x 10 x 256 0.708 BFLOPs
18 13 conv 512 3 x 3 / 1 30 x 10 x 256 -> 30 x 10 x 512 0.708 BFLOPs
19 14 conv 80 1 x 1 / 1 30 x 10 x 512 -> 30 x 10 x 80 0.025 BFLOPs
20 15 detection
21 mask_scale: Using default ‘1.000000‘
22 Loading weights from data/ocr/ocr-net.weights...Done!
23 Performing OCR...
24 Scanning ./tmp/03009_0car_lp.png
25 LP: GN06BG
26 Scanning ./tmp/03016_0car_lp.png
27 LP: MPE3389
28 Scanning ./tmp/03025_0car_lp.png
29 LP: INS6012
30 Scanning ./tmp/03033_0car_lp.png
31 LP: SEZ229
32 Scanning ./tmp/03057_0car_lp.png
33 LP: INTT263
34 Scanning ./tmp/03058_1car_lp.png
35 LP: C24JBH
36 Scanning ./tmp/03066_0car_lp.png
37 LP: 77
38 Scanning ./tmp/03066_2car_lp.png
39 LP: HHP8586
40 Scanning ./tmp/03071_0car_lp.png
41 LP: 6GQR959

最终的识别结果:

--------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1.基本功能:从一张或者一系列的图片中提取车牌信息,比如车牌号码、车牌颜色等信息。
2.功能扩展:车型、车品牌、车牌类型等。
3.应用方向:电子交易系统(停车自动收费、收费站自动支付等)、交通执法、交通监控等。
4.影响因子:
(1)车牌的影响:位置、数量、尺寸、颜色、字体、背景图案和颜色(指车牌的背景)、遮挡(可能车牌较脏)、倾斜、特殊车牌、双行车牌、其他(比如车框、螺钉)。
(2)环境影响:拍摄相机的种类(彩色、黑白、红外)和拍摄角度、光照影响、背景(指车的外形背景)。
5.车牌识别的一般步骤:图象获取——>车牌提取——>车牌字符分割——>字符识别。
6.各种识别方法之间性能比较方案:比较方法的优缺点(应用范围、功能范围)、识别率、识别速度等。
7.双行车牌的定位与字符的切割。
8.中国车牌的特点:多省份多种类的中文字符,且中文字符可能出现的位置有三处,如下所示:
且还有一些受环境影响的车牌:
# 总结如下:
车牌字符:数字0--9(10个)、字母A--Z(没有I和O,24个)、省份简称(31个)、特殊字符(7个,还有一些比较少见,没算在内) 共计72个
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z","川","鄂","赣","甘","贵","桂","黑","泸","冀","津","京","吉","辽","鲁","蒙","闽","宁","青","琼",
"陕","苏","晋","皖","湘","新","豫","渝","粤","云","藏","浙","澳","港","挂","警","领","使","学"
环境因素:拍摄角度、分辨率、环境亮度、模糊程度等。
原文链接:https://blog.csdn.net/ELEVEN_ZOU/article/details/80893579
以上是关于目标检测---搬砖一个ALPR自动车牌识别的环境的主要内容,如果未能解决你的问题,请参考以下文章