如何产生好的词向量
Posted robert_ai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何产生好的词向量相关的知识,希望对你有一定的参考价值。
如何产生好的词向量?
词向量、词嵌入(word vector,word embedding)也称分布式表示(distributed representation),想必任何一个做NLP的研究者都不陌生。如今词向量已经被广泛应用于各自NLP任务中,研究者们也提出了不少产生词向量的模型并开发成实用的工具供大家使用。在使用这些工具产生词向量时,不同的训练数据,参数,模型等都会对产生的词向量有所影响,那么如何产生好的词向量对于工程来说很重要。中科院自动化所的来斯惟博士对此进行了详细的研究。本篇博客也是我阅读来博士发表的论文《How to Generate a Good Word Embedding?》和其博士论文的笔记,并结合自己*时实验的经验总结出来的,希望对大家在训练词向量时有所帮助。
1 词的表示技术
在来博士的博士论文中概述了现有的主要词表示技术,我在此也先简单进行介绍。
1.1 独热表示技术(早期传统的表示技术)

1.2 分布表示技术(与独热表示技术相对应,基于分布式假说[即上下文相似的词,其语义也相似],把信息分布式地存储在向量的各个维度中的表示方法,具有紧密低维,捕捉了句法、语义信息特点)
- 基于矩阵的分布表示

- 基于聚类的分布表示
通过聚类手段构建词与其上下文之间的关系。代表模型:布朗聚类(Brown clustering)。
-
基于神经网络的分布表示(这是我们下面要研究的主要方法,在此介绍几种代表性模型)
神经网络语言模型(NNLM)
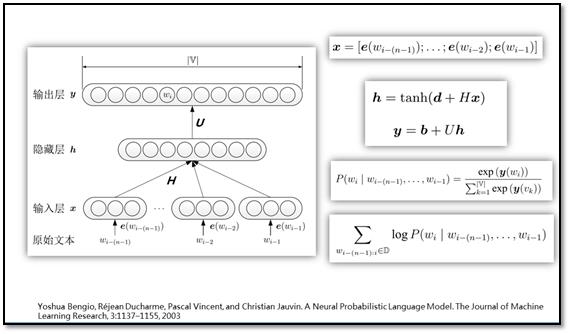
Log双线性语言模型(LBL)

C&W模型

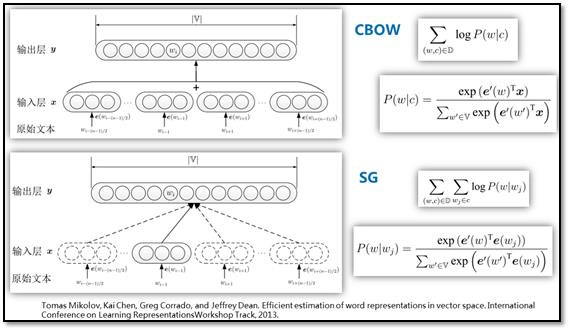
Continuous Bag-of-Words(CBOW)
Skip-gram(SG)
Word2vec工具中的两个模型
Order模型
在上面CBOW模型的在输入层是直接进行求和,这样并没有考虑词之前的序列顺序,所以来博士把直接求和改为了词向量之间的顺序拼接来保存序列顺序信息。

模型理论比较
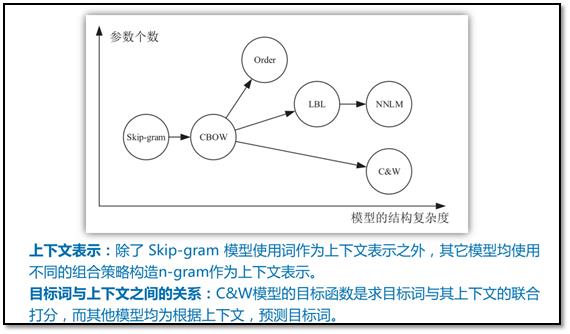
2各种模型的实验对比分析
整个实验是围绕下面几个问题进行的:
- 如何选择合适的模型?
- 训练语料的大小及领域对词向量有什么影响?
-
如何选择训练词向量的参数?
- 迭代次数
- 词向量维度
评价任务
词向量的语言学特性
- 词义相关性(ws): WordSim353数据集,词对语义打分。皮尔逊系数评价。
- 同义词检测(tfl): TOEFL数据集,80个单选题。准确率评价
- 单词语义类比(sem): 9000个问题。queen-king+man=women。准确率
- 单词句法类比(syn): 1W个问题。dancing-dance+predict=predicting。准确率
词向量用作特征
- 基于*均词向量的文本分类(avg): IMDB数据集,Logistic分类。准确率评价
- 命名实体识别(ner): CoNLL03数据集,作为现有系统的额外特征。F1值
词向量用作神经网络模型的初始值
- 基于卷积的文本分类(cnn): 斯坦福情感树库数据集,词向量不固定。准确率
- 词性标注(pos): 华尔街日报数据集,Collobert等人提出的NN。准确率
实验结果(红色字体为博主自己总结,黑色字体为论文结论)
模型比较
- 对于评价语言学特性的任务,通过上下文预测目标词的模型,比上下文与目标词联合打分的C&W模型效果更好。
- 对于实际的自然语言处理任务,各模型的差异不大,选用简单的模型即可。
- 简单模型在小语料上整体表现更好,而复杂的模型需要更大的语料作支撑。
语料影响
- 同领域的语料,一般语料越大效果越好
- 领域内的语料对相似领域任务的效果提升非常明显,但在领域不契合时甚至会有负面作用。
- 在自然语言任务上,同领域的语料10M效果明显差,但是100M以上扩大语料,任务结果的差异较小。
规模和领域的权衡
- 语料的领域纯度比语料规模更重要。(特别是在任务领域的语料比较小时,加入大量其他领域的语料可能会有很负面的影响)
参数选择
迭代次数
- 根据词向量的损失函数选择迭代次数不合适。
- 条件允许的话,选择目标任务的验证集性能作为参考标准。
- 具体任务性能指标趋势一样,可以选简单任务的性能峰值。
- 使用word2vec工具中demo的默认参数,15~25次差不多。
词向量维度
- 对于分析词向量语言学特性的任务,维度越大效果越好。
- 对于提升自然语言处理任务而言,50维词向量通常就足够好。(这里我觉得只能说是某些任务,不过趋势是一致的,随着词向量维度的增加,性能曲线先增长后趋*于*缓,甚至下降)
3 总结
- 选择一个合适的模型。复杂的模型相比简单的模型,在较大的语料中才有优势。(在word2vec工具中我一般使用SG模型)
- 选择一个合适领域的语料,在此前提下,语料规模越大越好。使用大规模的语料进行训练,可以普遍提升词向量的性能,如果使用领域内的语料,对同领域的任务会有显著的提升。(训练语料不要过小,一般使用同领域语料达到100M规模)
- 训练时,迭代优化的终止条件最好根据具体任务的验证集来判断,或者*似地选取其它类似的任务作为指标,但是不应该选用训练词向量时的损失函数。(迭代参数我一般使用根据训练语料大小,一般选用10~25次)
-
词向量的维度一般需要选择50维及以上,特别当衡量词向量的语言学特性时,词向量的维度越大,效果越好。(一般根据具体任务进行实验,最后根据性能和实验需使用的时间选择合适的词向量维度)
主要参考文献
[1] Lai S, Liu K, Xu L, et al. How to Generate a Good Word Embedding?. arXiv preprint arXiv:1507.05523, 2015.
[2] 来斯惟. 基于神经网络的词和文档语义向量表示方法研究. 中科院自动化所,博士论文,2016.
以上是关于如何产生好的词向量的主要内容,如果未能解决你的问题,请参考以下文章