关于近期使用pandas的一些经验总结
Posted fxm1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于近期使用pandas的一些经验总结相关的知识,希望对你有一定的参考价值。
1.pandas的去重函数drop_duplicates
DataFrame.drop_duplicates(subset=None, keep=‘first‘, inplace=False)
其中subset参数为用来指定要去重的列,默认是所有列;
keep参数有first,last,False三个可选项,first表示保留重复项中的第一项,last保留最后一项,False全部删除,默认为first;
inplace参数取bool值,为True时表示在原变量上直接修改,为False表示创建一个副本保存修改,默认为True。
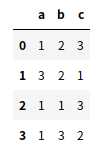
1 例: 2 data = [[1,2,3],[3,2,1],[1,1,3],[1,3,2]] 3 df = pd.DataFrame(data, columns=(‘a‘,‘b‘,‘c‘))
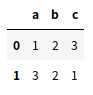
#将a列去重 df.drop_duplicates(‘a‘)
2.当某一列为字符串时,要删除这列中包含某个字符串的行
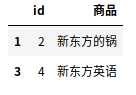
data = [[1,‘蓝翔挖掘机‘], [2,‘新东方的锅‘], [3,‘蓝翔金克拉‘], [4,‘新东方英语‘]] df = pd.DataFrame(data, columns=(‘id‘, ‘商品‘))

#删除“商品”列包含“蓝翔”的行 df = df[~df[‘商品‘].str.contains(‘蓝翔‘)]
3.将二维列表转为一维,例如[[1,2,3],[4,5,6],[7,8,9]]转为[1,2,3,4,5,6,7,8,9] -- 处理数据过程中遇到的
使用 itertools 中的 chain模块
from itertools import chain a = [[1,2,3],[4,5,6],[7,8,9]] print(‘a:‘,a) b = list(chain.from_iterable(a)) print(‘b:‘,b)
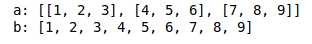
以上是关于关于近期使用pandas的一些经验总结的主要内容,如果未能解决你的问题,请参考以下文章