Python基础
Posted tianlangdada
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础相关的知识,希望对你有一定的参考价值。
今日主要内容
- 基础数据类型补充
- 循环删除问题
- 二次编码
一、基础数据类型补充
(一)int
int.bit_length()
- 计算整型对应的二进制位数
a = 10 print(a.bit_length()) # 4
(二)str
str.capitalize() 首字母大写,其余小写 str.title() 每个用特殊字符隔开的首字母大写 str.index() 计算元素索引位置 str.find() 计算元素索引位置 str.center() 将字符串居中 str.format() 格式化输出 str.swapcase() 大小写转换
str.capitalize()
- 将字串首字母大写,其余全部变为小写
s = "hello WORLD" s1 = s.capitalize() print(s1) # Hello worldstr.title()
- 将每个用特殊字符、中文、空格隔开的英文单词首字母大写
s = "hello world" s1 = s.title() print(s1) # Hello Worldstr.index(n)
- 计算元素n的索引位置,若n不在字符串中,会报错
- 默认计算第一个出现该元素n的索引位置
- 也可指定在范围内查询
s = "hello world" num = s.index("l") print(num) # 2 num1 = s.index("l", 5, 10) # 9str.find()
- 计算元素n的索引位置,若n不在字符串中,返回-1
- 默认计算第一个出现该元素n的索引位置
- 也可指定在范围内查询
s = "hello world" num = s.find("l") print(num) # 2 num1 = s.find("l", 5, 8) # -1str.center()
- 输入一个长度,使字符串在这个长度内居中
- 可填入第二个参数,居中后空白部分用它来填充
s = "DNF" s1 = s.center(15, "*") print(s1) # ******DNF******str.format()
- 格式化输出
- 按照位置格式化
s1 = "name: age: sex:" print(s1.format("ZXD", 23, "man")) # name:ZXD age:23 sex:man- 按照索引格式化
s1 = "name:2 age:0 sex:1" print(s1.format(23, "man", "ZXD")) # name:ZXD age:23 sex:man- 按照关键字格式化
s1 = "name:name age:age sex:sex" print(s1.format(sex="man", age=23, name="ZXD")) # name:ZXD age:23 sex:manstr.swapcase()
- 将字符串大小写互换
s = "hello WORLD" s1 = s.swapcase() print(s1) # HELLO world
(三)list
list.reverse() 将列表反向排列 list.sort() 将列表排序
list.reverse()
- 将列表反向排列
lst = [1, 2, 3, 4, 5] lst.reverse() print(lst) # [5, 4, 3, 2, 1]list.sort()
- 将列表升序排序
- 可填入关键字参数降序排序:reverse = True
lst = [2, 5, 1, 3, 8] lst.sort() print(lst) # [1, 2, 3, 5, 8] lst.sort(reverse = True) print(lst) # [8, 5, 3, 2, 1]
面试题:
lst = [1, 2, [3]] lst1 = lst * 2 lst1[2].append(4) print(lst1) # [1, 2, [3, 4], 1, 2, [3, 4]]- 列表在使用乘法时,将列表所有元素乘以倍数放到一个新列表中,所以相同元素的内存地址相同,元素共用
(四)dict
dict.fromkeys()
批量创建字典,第一个元素迭代成为key,第二个元素为所有key共用的value
两个坑:
- 第一个坑,fromkeys方法是创建字典,而不是在字典中修改或添加
dic = dic.fromkeys("abc", 123) print(dic) # dic = dic.fromkeys("abc", 123) print(dic) # 'a': 123, 'b': 123, 'c': 123- 第二个坑,fromkeys的第二个参数是共用的,若是可变类型数据修改,则字典中u所有value全被修改
dic = dic = dic.fromkeys("abc", [1]) dic["c"].append(2) print(dic) # 'a': [1, 2], 'b': [1, 2], 'c': [1, 2]
字典定义
dic =dic = dict()dic = dict(key=value)dic = dict([(key,value)])
dic1 = dict(k1=1) print(dic1) # 'k1': 1 dic2 = dict([("k1", 1)]) print(dic2) # 'k1': 1
(五)类型转换
转换为bool
- 所有的空、零转换为布尔类型都是False
- 所有的非空、非零转换为布尔类型都是True
print(bool()) # False print(bool(0)) # False print(bool([])) # False print(bool("")) # False print(bool()) # False print(bool(())) # False print(bool(set())) # Falsetuple与list互换
tu = tuple(list)lst = list(tuple)
l = [1, 2, 3] tu = tuple(l) print(tu) # (1, 2, 3) # 转换为元组 lst = list(tu) print(lst) # [1, 2, 3] # 转换为列表set与list互换
lst = set(list)st = list(set)
l = [1, 2, 3] st = set(l) print(st) # 1, 2, 3 # 转换为集合 lst = list(st) print(lst) # [1, 2, 3] # 转换为列表set与tuple互换
tuple(set)list(tuple)
t = (1, 2, 3) st = set(t) print(st) # 1, 2, 3 # 转换为集合 tu = tuple(st) print(tu) # (1, 2, 3) # 转换为元组int和str互换
int(str)str(int)
i = 123 s = str(i) print(s) # 123 # 转换为字符串 i = int(s) print(i) # 123 # 转换为整型str和list互换
s = str.join(list)lst = str.split()
lst = ["a", "b", "c"] s = "_".join(lst) print(s) # a_b_c lst = s.split("_") print(lst) # ['a', 'b', 'c']
(六)基础数据类型总结
| 是否有序 | 是否可变 | 可否迭代 | 查看方式 | |
|---|---|---|---|---|
| int | 有序(不支持索引) | 不可变 | 不可迭代 | 直接查看 |
| bool | 不可变 | 不可迭代 | 直接查看 | |
| str | 有序 | 不可变 | 可迭代 | 索引查看 |
| tuple | 有序 | 不可变 | 可迭代 | 索引查看 |
| list | 有序 | 可变 | 可迭代 | 索引查看 |
| dict | 无序 | 可变 | 可迭代 | 通过键查看 |
| set | 无序 | 可变 | 可迭代 | 直接查看 |
二、循环删除问题
(一)列表
尝试一下利用循环列表删除元素,清空列表
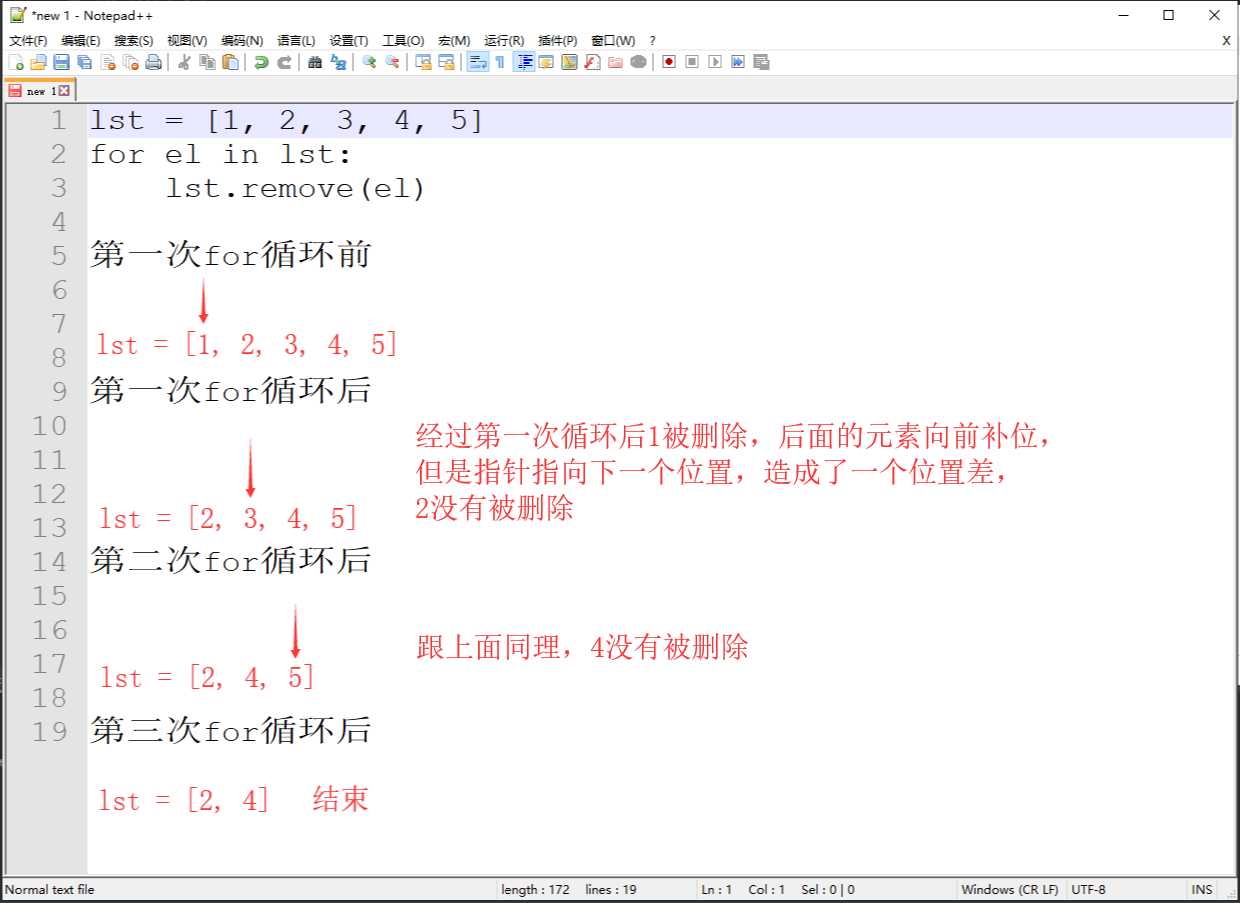
lst = [1, 2, 3, 4, 5] for el in lst: lst.remove(el) print(lst) # [2, 4]- 发现列表并没有被清空,这是为什么呢?
原理:
- for循环时,有一个元素指针记录当前循环位置,每循环一次指针就指向下一个位置,同时列表中的元素被删除会向前补位,这样就造成了一个位置差,导致元素删不干净
解决方法:
- 方法一:for循环元素个数次,每次都删除第一个元素
lst = [1, 2, 3, 4, 5] for i in range(len(lst)): lst.pop(0) print(lst) # []- 方法二:复制一个副本,循环副本删除原列表
lst = [1, 2, 3, 4, 5] lst1 = lst.copy() for el in lst1: lst.remove(el) print(lst) # []
(二)字典
尝试一下利用循环字典删除键值对,清空字典
dic = "k1": 1, "k2": 2, "k3": 3 for i in dic: dic.pop(i) print(dic) # RuntimeError: dictionary changed size during iteration- 报错:迭代期间字典长度改变
解决方法:
- 复制一个副本,循环副本删除原字典
dic = "k1": 1, "k2": 2, "k3": 3 dic1 = dic.copy() for k in dic1: dic.pop(k) print(dic) #
(三)集合
尝试一下利用循环集合删除元素,清空集合
st = 1, 2, 3, 4, 5 for el in st: st.remove(el) print(st) # RuntimeError: Set changed size during iteration- 报错:迭代期间集合改变长度
解决方法:
- 复制一个副本,循环副本删除原集合
st = 1, 2, 3, 4, 5 st1 = st.copy() for el in st1: st.remove(el) print(st) # set()
三、二次编码
(一)编码回顾
- ascii码
- 只包含英文、数字、特殊符号
- 每个字符:一个字节,8位
- gbk:国标码
- 包含中文、英文、数字、特殊符号
- 英文:一个字节,8位
- 中文:两个字节,16位
- unicode:万国码
- 每个字符:四个字节,32位
- utf-8:可变长度编码
- 英文:一个字节,8位
- 欧洲文字:两个字节,16位
- 中文:三个字节,24位
(二)编码与解码
- Python3内存中使用的就是uncode
- 硬盘中存储时选择的编码方式
- gbk
- utf-8
- 用什么编码就要用什么解码
编码
- 格式:
数据.encode(编码)
s = "你好啊" se = s.encode("utf-8") print(se) # b'\\xe4\\xbd\\xa0\\xe5\\xa5\\xbd\\xe5\\x95\\x8a'- 格式:
解码
- 格式:
编码后的数据.decode(编码)
s = b'\\xe4\\xbd\\xa0\\xe5\\xa5\\xbd\\xe5\\x95\\x8a' se = s.decode("utf-8") print(se) # 你好啊- 格式:
用处:
- 存储:文件操作
- 传输:网络编程
以上是关于Python基础的主要内容,如果未能解决你的问题,请参考以下文章