正则表达式
Posted s686zhou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式相关的知识,希望对你有一定的参考价值。
向我们平常见的那些注册页面啥的,都需要我们输入手机号码,你想我们的电话号码也是有限的吧。(手机号码一i共11位,并且只以13,14,15,17,18开头的数字这些特点)如果你的输入有误就会提示,那么现实中这个程序的话你觉得用while循环判断简单吗,那么我们看看实现结果
while True: phone_number=input(‘请输入你的电话号码:‘) if len(phone_number)==11 and phone_number.isdigit() and (phone_number.startswith(‘13‘) or phone_number.startswith(‘14‘) or phone_number.startswith(‘15‘) or phone_number.startswith(‘17‘) or phone_number.startswith(‘18‘)): print(‘是合法的手机号码‘) else: print(‘不是合法的手机号码‘)
看到这个代码,虽说很容易理解,但是还有更简单的方法
import re phone_number=input(‘请输入你的电话号码:‘) if re.match(‘^(13|14|15|17|18)[0-9]9$‘,phone_number): ‘‘‘^这个符号表示的是判断是不是以13|14|15|17|18开头的, [0-9]: []表示一个字符组,可以表示0-9的任意字符 9:表示后面的数字重复九次 $:表示结束符 ‘‘‘ print(‘是合法的手机号码‘) else: print(‘不是合法的手机号码‘)
那么什么是正则呢?
首先你要知道的是,谈到正则,就只和字符串相关了。在线测试工具http://tool.chinaz.com/regex/
比如你要用‘1’去匹配‘1’,直接就可以匹配上。
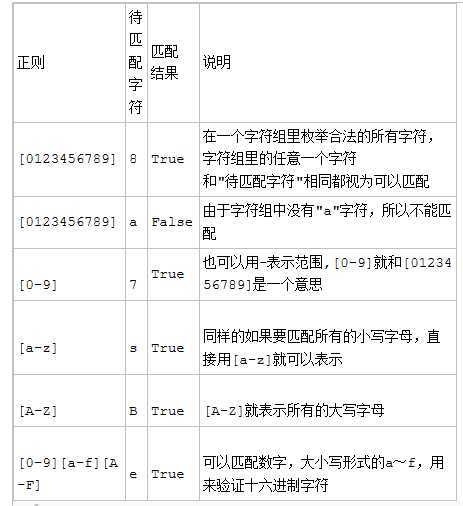
字符组
字符组:【字符组】
在同一位置可能出现的各种字符组成了一个字符组,在正则表达式中用【】表示,字符分为很多类,比如数字,字母,标点等等。
假如你现在要求一个位置‘只能出现一个数字’,那么这个位置上的字符只能是0,1,2,3....9
字符
量词
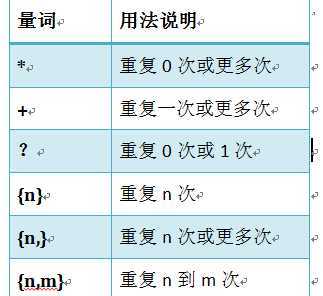
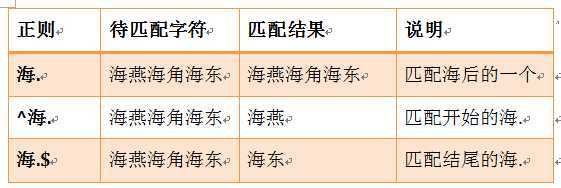
.^$
*+?
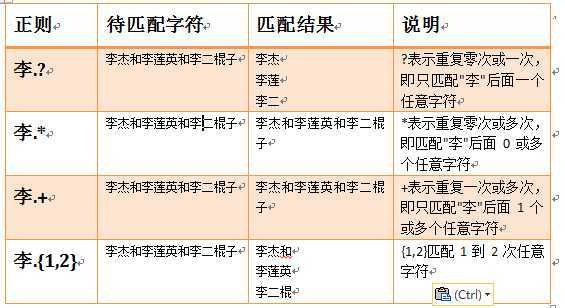
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能多的匹配,后面加?就变成了非贪婪匹配,也就是惰性匹配。
贪婪匹配
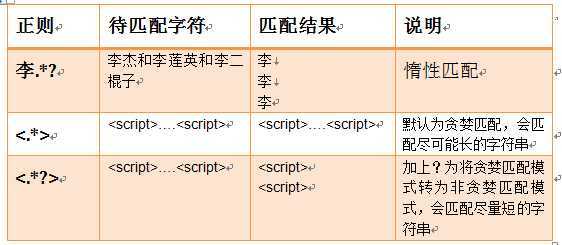
几个常用的贪婪匹配
*?;重复任意次,但尽可能少重复
+?:重复一次或更多次,但尽可能少重复
??:重复0次或1次,但尽可能少重复
n,m:重复n到m次,但尽可能少重复
n,: 重复n次以上,但尽可能少重复
.*?的用法:
.是任意字符
*是取0到无限长度
?是非贪婪模式
和在一起就是取尽量少的任意字符,一般不会这么单独写,大多用在:
.*?x
意思就是取前面任意长度的字符,直到一个x出现
字符集:
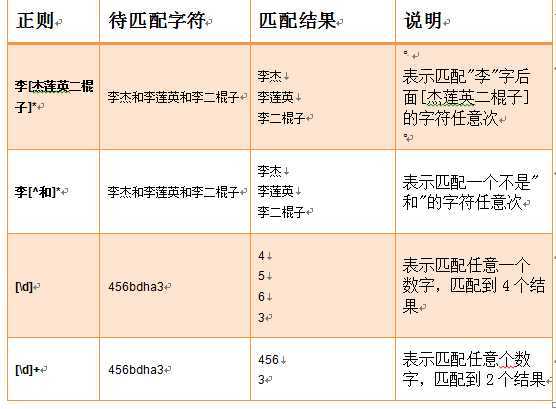
分组()与或 | 【^】
(1)^[1-9]\\d13,16[0-9x]$ #^以数字0-9开始,
\\d13,16重复13次到16次
$结束标志
上面的表达式可以匹配一个正确的身份证号码
(2)^[1-9]\\d14(\\d2[0-9x])?$
#?重复0次或者1次,当是0次的时候是15位,是1的时候是18位
(3)^([1-9]\\d16[0-9x]|[1-9]\\d14)$
#表示先匹配[1-9]\\d16[0-9x]如果没有匹配上就匹配[1-9]\\d14


举个例子,比如html源码中有<title>xxx</title>标签,用以前的知识,我们只能确定源码中的<title>和</title>是固定不变的。因此,如果想获取页面标题(xxx),充其量只能写一个类似于这样的表达式:<title>.*</title>,而这样写匹配出来的是完整的<title>xxx</title>标签,并不是单纯的页面标题xxx。 想解决以上问题,就要用到断言知识。 在讲断言之前,读者应该先了解分组,这有助于理解断言。 分组在正则中用()表示,根据小菜理解,分组的作用有两个: n 将某些规律看成是一组,然后进行组级别的重复,可以得到意想不到的效果。 n 分组之后,可以通过后向引用简化表达式。 先来看第一个作用,对于IP地址的匹配,简单的可以写为如下形式: \\d1,3.\\d1,3.\\d1,3.\\d1,3 但仔细观察,我们可以发现一定的规律,可以把.\\d1,3看成一个整体,也就是把他们看成一组,再把这个组重复3次即可。表达式如下: \\d1,3(.\\d1,3)3 这样一看,就比较简洁了。 再来看第二个作用,就拿匹配<title>xxx</title>标签来说,简单的正则可以这样写: <title>.*</title> 可以看出,上边表达式中有两个title,完全一样,其实可以通过分组简写。表达式如下: <(title)>.*</\\1> 这个例子实际上就是反向引用的实际应用。对于分组而言,整个表达式永远算作第0组,在本例中,第0组是<(title)>.*</\\1>,然后从左到右,依次为分组编号,因此,(title)是第1组。 用\\1这种语法,可以引用某组的文本内容,\\1当然就是引用第1组的文本内容了,这样一来,就可以简化正则表达式,只写一次title,把它放在组里,然后在后边引用即可。 以此为启发,我们可不可以简化刚刚的IP地址正则表达式呢?原来的表达式为\\d1,3(.\\d1,3)3,里边的\\d1,3重复了两次,如果利用后向引用简化,表达式如下: (\\d1,3)(.\\1)3 简单的解释下,把\\d1,3放在一组里,表示为(\\d1,3),它是第1组,(.\\1)是第2组,在第2组里通过\\1语法,后向引用了第1组的文本内容。 经过实际测试,会发现这样写是错误的,为什么呢? 小菜一直在强调,后向引用,引用的仅仅是文本内容,而不是正则表达式! 也就是说,组中的内容一旦匹配成功,后向引用,引用的就是匹配成功后的内容,引用的是结果,而不是表达式。 因此,(\\d1,3)(.\\1)3这个表达式实际上匹配的是四个数都相同的IP地址,比如:123.123.123.123。 至此,读者已经掌握了传说中的后向引用,就这么简单。 对于分组的理解
分组命名:语法(?p<name>) 注意先命名,后正则
import re import re ret=re.search(‘<(\\w+)>\\w+<(/\\w+)>‘,‘<h1>hello</h1>‘) print(ret.group()) # 给分组起个名字。就用下面的分组命名,上面的方法和下面的分组命名是一样的,只不过就是给命了个名字 ret=re.search(‘<(?P<tag_name>\\w+)>\\w+</(?P=tag_name)>‘,‘<h1>hello</h1>‘) #(?P=tag_name)就代表的是(\\w+) print(ret.group()) # 了解(和上面的是一样的,是上面方式的那种简写) ret=re.search(r‘<(\\w+)>\\w+</\\1>‘,‘<h1>hello</h1>‘) print(ret.group(1))
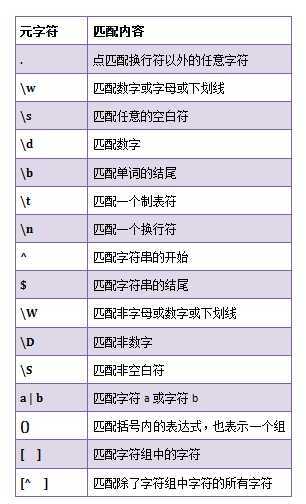
转义符:
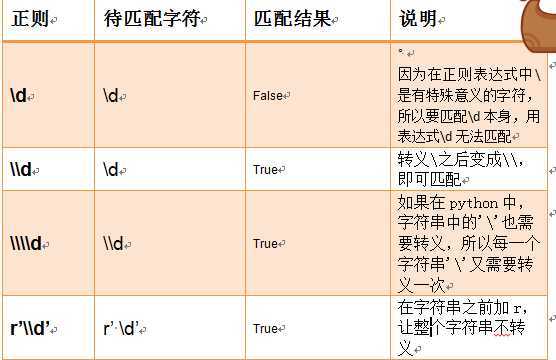
以上是关于正则表达式的主要内容,如果未能解决你的问题,请参考以下文章