倒排索引
Posted kkbill
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了倒排索引相关的知识,希望对你有一定的参考价值。

-
文档:一般搜索引擎的处理对象是网页。而文档的概念则要更加宽泛一些,凡是以文本形式存在的存储对象,比如.doc,.txt,.html等格式的文件都是文档。在这里,可以简单的把文档理解成网页。
-
文档集合:由若干篇文档构成的集合就称为文档集合。对于搜索引擎而言,文档集合就是从互联网上爬下来的所有网页的集合,这个数据是巨大的,为了存储这些海量的数据从而有了分布式存储。在我的这个小项目中,我就只爬取了几百篇博客作为我的文档集合。
-
文档编号:在搜索引擎内部,每篇文档会有唯一的编号作为标记,方便数据处理。记文档编号为docID。
-
倒排列表:倒排列表记录了出现过某个单词的文档列表,以及单词在文档中的一些信息(比如权重,位置等),每条记录称为倒排项。通过倒排列表,即可获得包含某一单词的所有的文档。
- 单词词典:搜索引擎的索引单位通常是单词,单词词典是由文档集合中出现过的所有单词构成的。

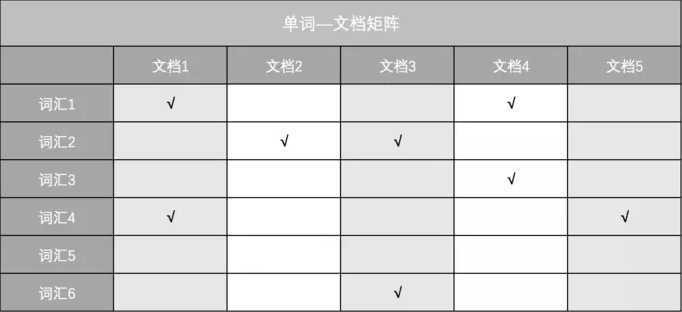
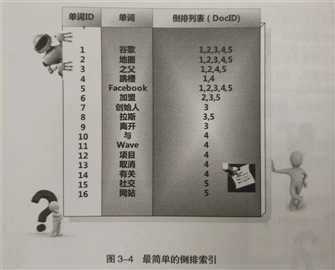
对于英文,各个单词之间是分割开的,很好处理;对于中文,则需要分词算法先把一句连续的话切分成一个个单词,比如,"南京市长江大桥"到底是切分成"南京", "市长", "江大桥"还是"南京市", 长江大桥"就是分词算法做的事情。但这不是讨论的重点,我们假设,能很好的对中文文档进行分词。对于不同的单词,我们为其赋予唯一的单词编号,同时记录该单词在哪些文档中出现过。基于此,我们可以得到最简单的倒排索引,如下图所示。比如,"跳槽"这一个单词的编号是4,它在文档1、4中出现过,因此该单词对应的倒排列表就是1, 4。
下面的倒排索引则稍微复杂了一些,不仅记录了单词在哪篇文档中出现过,还记录了单词在该文档中出现的频率(Term Frequency, TF),之所以记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是一个很重要的计算因子。比如,"跳槽"一词的倒排列表为(1;1), (4;1),说明该单词在1号文档中出现过1次,在4号文档中出现过1次。

下面的倒排索引则增加了文档频率(Document Frequency,DF)和单词在文中的位置信息(<pos>),还是以"跳槽"为例,其文档频率为2,表示在整个文档集合中,共有2个文档包含"跳槽"这个单词;倒排索引项(1; 1; <4>)表示该单词在1号文档中出现过1次,并且出现的位置是4,即文档中的第4个单词是"跳槽"。

图3-6所示的倒排索引已经是一个非常完备的索引系统了,有了这个索引系统,搜索引擎就可以很方便的响应用户的查询。比如用户输入查询词"Facebook",搜索系统查找倒排索引,从中可以读出包含这个单词的文档,这些文档就是提供给用户的搜索结果,而利用单词频率信息(TF)、文档频率信息(DF)即可对这些候选搜索结果进行排序,计算文档与查询的相似性,按照相似性得分由高到低排序输出。
构建倒排索引表的数据结构是 unordered_map<string, vector<pair<int, double>>> invertIndexTable; 即 单词1 docID1,weight1, docID2,weight2, docID3,weight3... 单词2 docID1,weight1, docID2,weight2, docID3,weight3... ... ... 项目部分源码 void PagelibProcesser::createInvertIndexTable() for(auto iter = pagelib_.begin(); iter != pagelib_.end(); ++iter) //pagelib_的结构是vector<WebPage> auto docWordMap = (*iter).getDocWordMap();//词典,[单词,词频] for(auto it = docWordMap.begin(); it != docWordMap.end(); ++it) //倒排索引的结构unordered_map<string, vector<pair<int, double>>> invertIndexTable_ invertIndexTable_[it->first].push_back(iter->getDocID(),it->second);//<单词,<docID,词频>> size_t totalPageNum = pagelib_.size();//网页库中网页的总数 map<int,double> pageWeight;//每个网页的权重和 for(auto iter = invertIndexTable_.begin(); iter != invertIndexTable_.end(); ++iter) size_t df = iter->second.size();//文档频率,表示单词在多少篇文档中出现过 double idf = log(static_cast<double>(totalPageNum)/(df+1));//逆文档频率 for(auto & elem : iter->second) double weight = elem.second * idf; elem.second = weight; pageWeight[elem.first] += pow(weight,2); //归一化处理 for(auto iter = invertIndexTable_.begin(); iter != invertIndexTable_.end(); ++iter) for(auto & elem : iter->second) elem.second = elem.second / sqrt(pageWeight[elem.first]);
建倒排索引时最难的是每个词语的权重值的计算,它涉及到如下几个概念:
做个记录,方便回顾。
以上是关于倒排索引的主要内容,如果未能解决你的问题,请参考以下文章