实时统计每天pv,uv的sparkStreaming结合redis结果存入mysql供前端展示
Posted data-magnifier
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时统计每天pv,uv的sparkStreaming结合redis结果存入mysql供前端展示相关的知识,希望对你有一定的参考价值。
最近有个需求,实时统计pv,uv,结果按照date,hour,pv,uv来展示,按天统计,第二天重新统计,当然了实际还需要按照类型字段分类统计pv,uv,比如按照date,hour,pv,uv,type来展示。这里介绍最基本的pv,uv的展示。
| id | uv | pv | date | hour |
|---|---|---|---|---|
| 1 | 155599 | 306053 | 2018-07-27 | 18 |
关于什么是pv,uv,可以参见这篇博客:https://blog.csdn.net/petermsh/article/details/78652246
1、项目流程
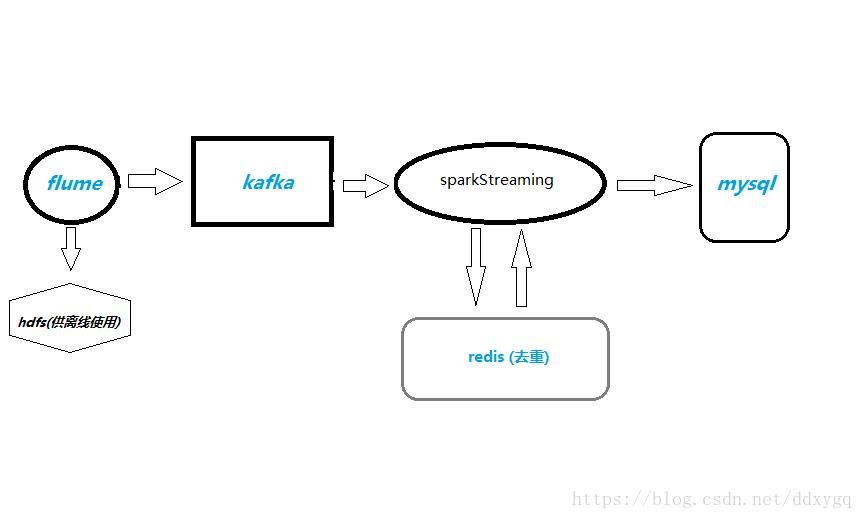
日志数据从flume采集过来,落到hdfs供其它离线业务使用,也会sink到kafka,sparkStreaming从kafka拉数据过来,计算pv,uv,uv是用的redis的set集合去重,最后把结果写入mysql数据库,供前端展示使用。
2、具体过程
1)pv的计算
拉取数据有两种方式,基于received和direct方式,这里用direct直拉的方式,用的mapWithState算子保存状态,这个算子与updateStateByKey一样,并且性能更好。当然了实际中数据过来需要经过清洗,过滤,才能使用。
定义一个状态函数
// 实时流量状态更新函数
val mapFunction = (datehour:String, pv:Option[Long], state:State[Long]) =>
val accuSum = pv.getOrElse(0L) + state.getOption().getOrElse(0L)
val output = (datehour,accuSum)
state.update(accuSum)
output
计算pv
val stateSpec = StateSpec.function(mapFunction)
val helper_count_all = helper_data.map(x => (x._1,1L)).mapWithState(stateSpec).stateSnapshots().repartition(2)这样就很容易的把pv计算出来了。
2)uv的计算
uv是要全天去重的,每次进来一个batch的数据,如果用原生的reduceByKey或者groupByKey对配置要求太高,在配置较低情况下,我们申请了一个93G的redis用来去重,原理是每进来一条数据,将date作为key,guid加入set集合,20秒刷新一次,也就是将set集合的尺寸取出来,更新一下数据库即可。
helper_data.foreachRDD(rdd =>
rdd.foreachPartition(eachPartition =>
// 获取redis连接
val jedis = getJedis
eachPartition.foreach(x =>
val date:String = x._1.split(":")(0)
val key = date
// 将date作为key,guid(x._2)加入set集合
jedis.sadd(key,x._2)
// 设置存储每天的数据的set过期时间,防止超过redis容量,这样每天的set集合,定期会被自动删除
jedis.expire(key,ConfigFactory.rediskeyexists)
)
// 关闭连接
closeJedis(jedis)
)
)3)结果保存到数据库
结果保存到mysql,数据库,20秒刷新一次数据库,前端展示刷新一次,就会重新查询一次数据库,做到实时统计展示pv,uv的目的。
/**
* 插入数据
* @param data (addTab(datehour)+helperversion)
* @param tbName
* @param colNames
*/
def insertHelper(data: DStream[(String, Long)], tbName: String, colNames: String*): Unit =
data.foreachRDD(rdd =>
val tmp_rdd = rdd.map(x => x._1.substring(11, 13).toInt)
if (!rdd.isEmpty())
val hour_now = tmp_rdd.max() // 获取当前结果中最大的时间,在数据恢复中可以起作用
rdd.foreachPartition(eachPartition =>
try
val jedis = getJedis
val conn = MysqlPoolUtil.getConnection()
conn.setAutoCommit(false)
val stmt = conn.createStatement()
eachPartition.foreach(x =>
val datehour = x._1.split("\\t")(0)
val helperversion = x._1.split("\\t")(1)
val date_hour = datehour.split(":")
val date = date_hour(0)
val hour = date_hour(1).toInt
val colName0 = colNames(0) // date
val colName1 = colNames(1) // hour
val colName2 = colNames(2) // count_all
val colName3 = colNames(3) // count
val colName4 = colNames(4) // helperversion
val colName5 = colNames(5) // datehour
val colName6 = colNames(6) // dh
val colValue0 = addYin(date)
val colValue1 = hour
val colValue2 = x._2.toInt
val colValue3 = jedis.scard(date + "_" + helperversion) // // 2018-07-08_10.0.1.22
val colValue4 = addYin(helperversion)
var colValue5 = if (hour < 10) "'" + date + " 0" + hour + ":00 " + helperversion + "'" else "'" + date + " " + hour + ":00 " + helperversion + "'"
val colValue6 = if(hour < 10) "'" + date + " 0" + hour + ":00'" else "'" + date + " " + hour + ":00'"
var sql = ""
if (hour == hour_now) // uv只对现在更新
sql = s"insert into $tbName($colName0,$colName1,$colName2,$colName3,$colName4,$colName5) values($colValue0,$colValue1,$colValue2,$colValue3,$colValue4,$colValue5) on duplicate key update $colName2 = $colValue2,$colName3 = $colValue3"
else
sql = s"insert into $tbName($colName0,$colName1,$colName2,$colName4,$colName5) values($colValue0,$colValue1,$colValue2,$colValue4,$colValue5) on duplicate key update $colName2 = $colValue2"
stmt.addBatch(sql)
)
closeJedis(jedis)
stmt.executeBatch() // 批量执行sql语句
conn.commit()
conn.close()
catch
case e: Exception =>
logger.error(e)
logger2.error(HelperHandle.getClass.getSimpleName + e)
)
)
// 计算当前时间距离次日零点的时长(毫秒)
def resetTime =
val now = new Date()
val todayEnd = Calendar.getInstance
todayEnd.set(Calendar.HOUR_OF_DAY, 23) // Calendar.HOUR 12小时制
todayEnd.set(Calendar.MINUTE, 59)
todayEnd.set(Calendar.SECOND, 59)
todayEnd.set(Calendar.MILLISECOND, 999)
todayEnd.getTimeInMillis - now.getTime
4)数据容错
流处理消费kafka都会考虑到数据丢失问题,一般可以保存到任何存储系统,包括mysql,hdfs,hbase,redis,zookeeper等到。这里用SparkStreaming自带的checkpoint机制来实现应用重启时数据恢复。
checkpoint
这里采用的是checkpoint机制,在重启或者失败后重启可以直接读取上次没有完成的任务,从kafka对应offset读取数据。
// 初始化配置文件
ConfigFactory.initConfig()
val conf = new SparkConf().setAppName(ConfigFactory.sparkstreamname)
conf.set("spark.streaming.stopGracefullyOnShutdown","true")
conf.set("spark.streaming.kafka.maxRatePerPartition",consumeRate)
conf.set("spark.default.parallelism","24")
val sc = new SparkContext(conf)
while (true)
val ssc = StreamingContext.getOrCreate(ConfigFactory.checkpointdir + DateUtil.getDay(0),getStreamingContext _ )
ssc.start()
ssc.awaitTerminationOrTimeout(resetTime)
ssc.stop(false,true)
checkpoint是每天一个目录,在第二天凌晨定时销毁StreamingContext对象,重新统计计算pv,uv。
注意
ssc.stop(false,true)表示优雅地销毁StreamingContext对象,不能销毁SparkContext对象,ssc.stop(true,true)会停掉SparkContext对象,程序就直接停了。
应用迁移或者程序升级
在这个过程中,我们把应用升级了一下,比如说某个功能写的不够完善,或者有逻辑错误,这时候都是需要修改代码,重新打jar包的,这时候如果把程序停了,新的应用还是会读取老的checkpoint,可能会有两个问题:
- 执行的还是上一次的程序,因为checkpoint里面也有序列化的代码;
- 直接执行失败,反序列化失败;
其实有时候,修改代码后不用删除checkpoint也是可以直接生效,经过很多测试,我发现如果对数据的过滤操作导致数据过滤逻辑改变,还有状态操作保存修改,也会导致重启失败,只有删除checkpoint才行,可是实际中一旦删除checkpoint,就会导致上一次未完成的任务和消费kafka的offset丢失,直接导致数据丢失,这种情况下我一般这么做。
这种情况一般是在另外一个集群,或者把checkpoint目录修改下,我们是代码与配置文件分离,所以修改配置文件checkpoint的位置还是很方便的。然后两个程序一起跑,除了checkpoint目录不一样,会重新建,都插入同一个数据库,跑一段时间后,把旧的程序停掉就好。以前看官网这么说,只能记住不能清楚明了,只有自己做时才会想一下办法去保证数据准确。
5)日志
日志用的log4j2,本地保存一份,ERROR级别的日志会通过邮件发送到手机。
val logger = LogManager.getLogger(HelperHandle.getClass.getSimpleName)
// 邮件level=error日志
val logger2 = LogManager.getLogger("email")
分享一个大神的人工智能教程。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到人工智能的队伍中来!
微信公众号
我的微信公众号,专注于大数据分析与挖掘,感兴趣可以关注,看一看,瞧一瞧!

以上是关于实时统计每天pv,uv的sparkStreaming结合redis结果存入mysql供前端展示的主要内容,如果未能解决你的问题,请参考以下文章
在电商行业,采用flink进行热门实时流量统计,流量PV和UV分析市场营销分析恶意登录监控订单支付实时监控等场景的解决方案
6.Redis系列Redis的高级应用-HyperLogLog