openstack学习-理解存储管理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openstack学习-理解存储管理相关的知识,希望对你有一定的参考价值。
openstack存储类型openstack中存储可以分为两类,如下图所示:
目前openstack支持三种类型的持久存储:块存储、对象存储和文件系统存储

因为目前Manila使用较少,重点为CInder和Swift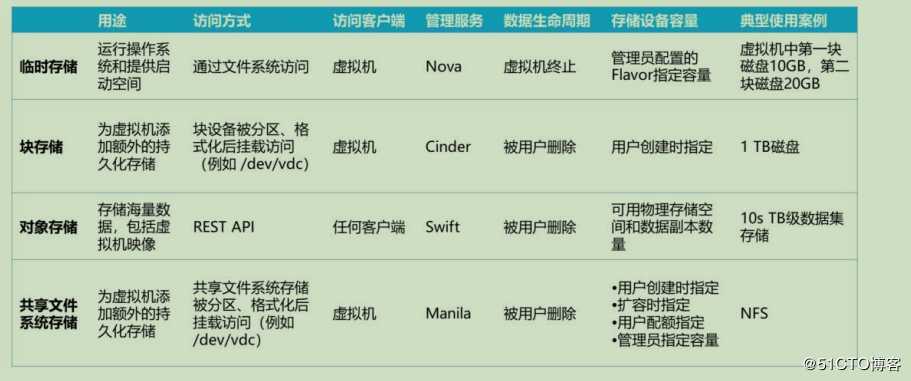
块存储Cinder
Cinder简介
Cinder在OpenStack中的位置和作用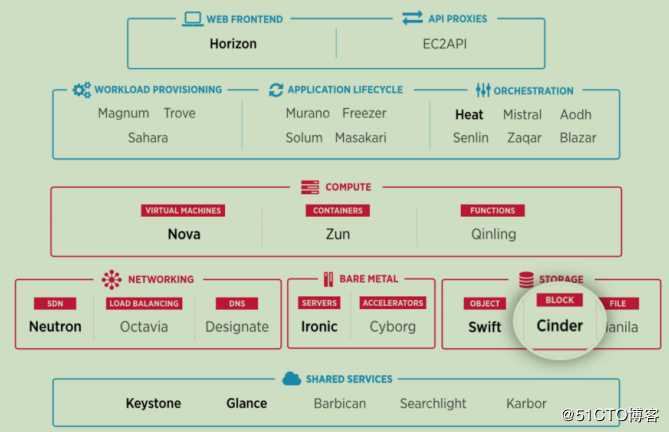
Cinder的核心功能是对卷的管理,允许对卷、卷的类型、卷的快照、卷备份进行处理。它为后端不同的存储设备提供给了统一的接口,不同的块设备服务厂商在Cinder中实现其驱动,可以被Openstack整合管理
Cinder的架构
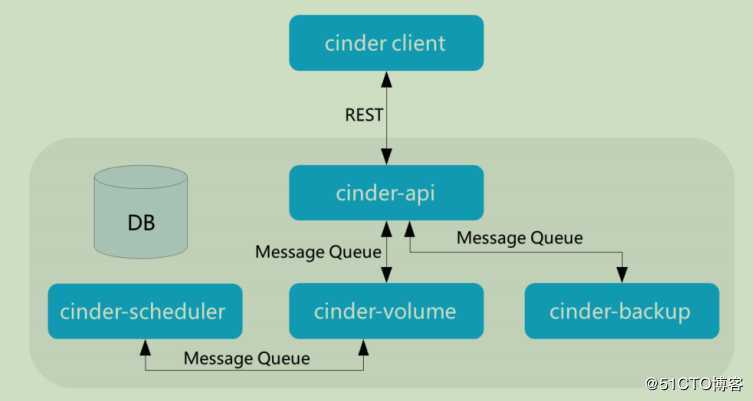
- Cinder Client封装Cinder提供rest接口,以CLI形式提供用户使用
- Cinder API对外提供rest API,对操作需求进行解析,对API进行路由寻找对应的处理方法。包含卷的增删改查(包括对源卷、镜像、快照创建)、快照增删改查、备份、volume type管理、挂载/卸载(Nova调用)等。
- Cinder Scheduler负责收集backend上报的容量、能力信息,根设定的算法完成卷到指定cinder-volume的调度
- Cinder Volume多节点部署,使用不同的配置文件,接入不同的backend设备,由各存储厂商插入driver代码与设备交互完成设备容量和能力信息的收集,卷操作
- Cinder Backup实现将卷的数据备份到其他存储介质(目前SWIFT/Ceph/TSM提供了驱动)
- SQL DB提供储卷、快照、备份、service等数据,支持mysql,PG,MSSQL等SQL数据库
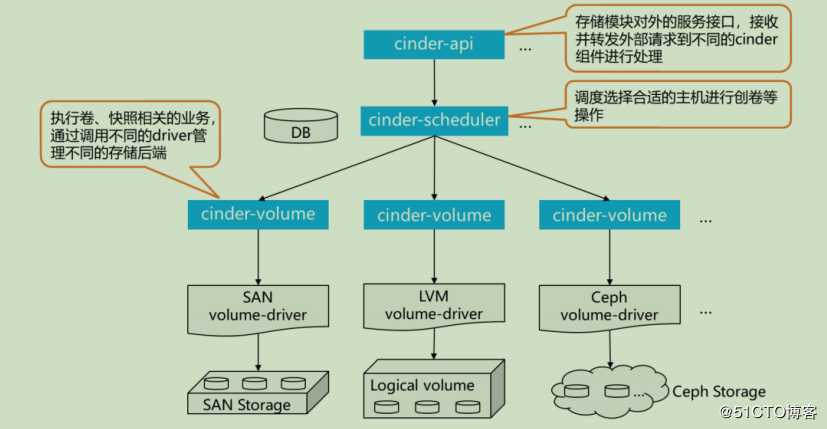
Cinder 组件-API
Cinder API对外提供REST API,对操作需求进行解析,并调用处理方法:
- 卷create/delete/list/show
- 快照create/delete/list/show
- 卷attach/detach(nova调用)
- 其他:
Volume types
Qutotas
BackupsCinder组件-Scheduler
Cinder scheduler负责收集后端上报的容量,能力信息,根据设定的算法完成卷到指定cinder-volume的调度,它通过过滤和称权,筛选出合适的后端:

根据后端的能力进行筛选 - Drivers定期报告后端的能力和状态
- 管理员创建的卷类型
- 创建卷时,用户指定卷类型
Cinder组件-Volume
Cinder volume多节点部署,使用不同的配置文件、接入不同的后端设备,由各存储厂商插入Driver代码与设备交互,完成设备容量和能力信息收集,卷操作等。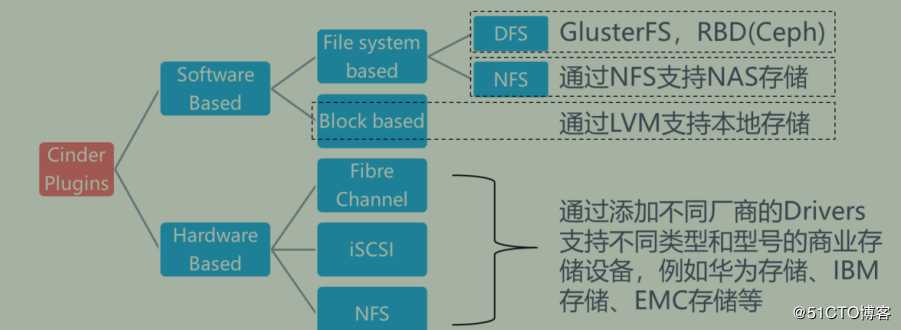
Cinder默认的后端驱动是LVM
典型工作流程
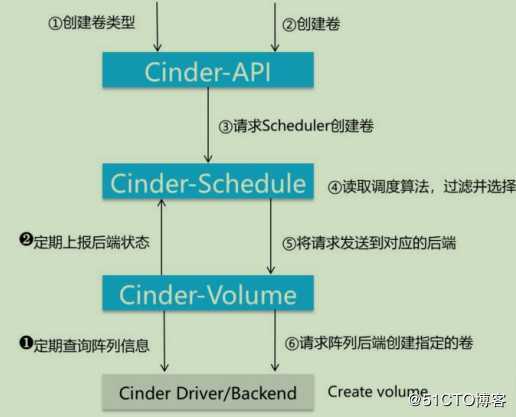
Cinder-volume会定期收集底层后端的容量信息,并通知Scheduler更新内存中的Backend信息
创建卷类型的目的是为了筛选不同的后端存储,例如SSD,STAT,高性能,低性能,通过创建不同的自定义卷类型,创建卷时自动给筛选出合适的后端存储
Cinder API
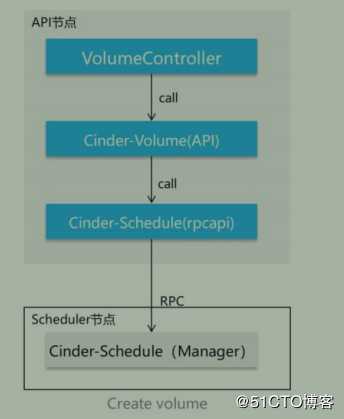
- 检查卷参数合法性(用户输入,权限,资源是否存在等)
- 准备创建参数字典,预留和提交配额
- 在数据库中创建对应的数据记录
- 通过消息列队将请求和参数发送到Scheduler
Cinder Scheduler

提取收到的请求参数
通过配置的filter和输入参数后端进行过滤
- Avialability_zone_filter
- Capactiy_filter
- Capabilities_filter
- Affinity_filter
-
Weigher计算后端进行权重
- CapactiyWeigher/AllocatedCapacityWeigher
- ChanceWeigher
- GoodnessWeigher
-
选取最优的Backend并通过消息列队将请求发送到指定的后端
和Nova Scheduler类似,Cinder Scheduler也是经过Filter删选合适条件的后端,然后使用Weigher计算后端进行权重排序,最终选择出最合适的后端存储
Cinder Volume

提供接收到的请求参数
调用对应的Driver在后端创建世纪的卷
使用Driver返回的模型更新数据库中的记录
Cinder挂载卷流程
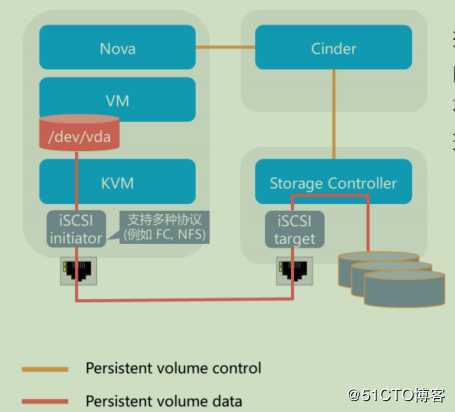
挂卷流程:挂卷时通过Nova和Cinder的配合最终将远端的卷连接到虚拟机所在的Host节点上,并最终通过虚拟机管理程序映射到内部的虚拟机中
- Nova调用Cinder api创建卷,传递主机的信息,如hostname,ISCSI initiator name,FC WWWPNs
- Cinder API将该信息传递给Cincer Volume
- Cinder Volume通过创建卷时保存的host信息找到对应的Cinder Driver
- Cinder Driver通知存储允许该主机访问该卷,并返回该存储的连接信息(如ISCSI iqn,portal,FC target WWPN,NFS path)
- Nova调用针对不同存储类型进行主机识别磁盘的代码(Cinder提供了brick模块用于参考)实现识别磁盘或者文件设备
- Nova通知Cinder已经进行了挂载
- Nova将主机的设备信息传递给hypervisor来实现虚拟机挂载磁盘
Cinder主要操作

对象存储Swift
Swift简介
Swift提供高度可用、分布式、最终一致的对象存储服务
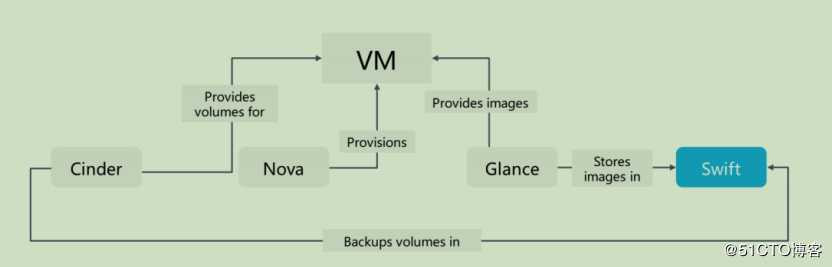
Swift并不是文件系统或者试试的数据存储系统,它称为对象存储,用于永久类型的静态数据的长期存储,这些存储可以检索,调整,必要时进行更新
最蛇和存储的数据类型的例子是虚拟机镜像,图片存储,邮件存储和存档备份
因为没有中心的单元或主控节点,Swift提供了更强的扩展性,冗余和持久性
Swift经常用于存储镜像或者用于存储虚拟机实例卷的备份副本
Swift应用
镜像存储后端:在Openstack中与镜像服务Glance结合,为其存储镜像文件
静态数据存储:由于swift的扩展能力,适合存储日志文件和数据备份仓库
Swift架构
Swift中对象存储URL如下所示:
https://swift.example.com/va/account/container/object
URL有两个部分:集权位置和存储位置
集群位置:swift.example.com/v1/
存储位置(对象):/account/containr/oject
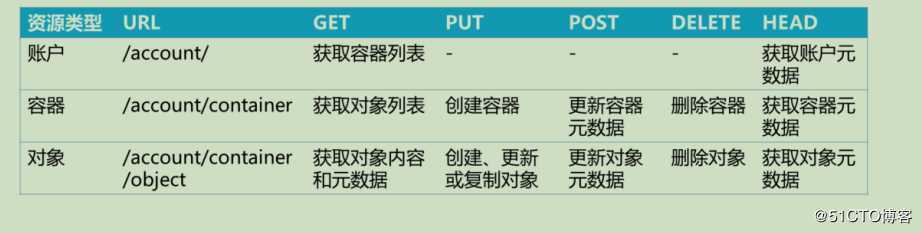
存储位置有如下三种:
/account
账户存储位置是唯一命名的存储区域,其中包含账户本身的元数据(描述性信息)以及账户中的容器列表
/account/container
容器存储位置是账号内的用户定义的存储区域,其中包含容器本身和容器中的对象列表的元数据
/account/container/object
对象存储位置存储了数据对象及元数据的位置。
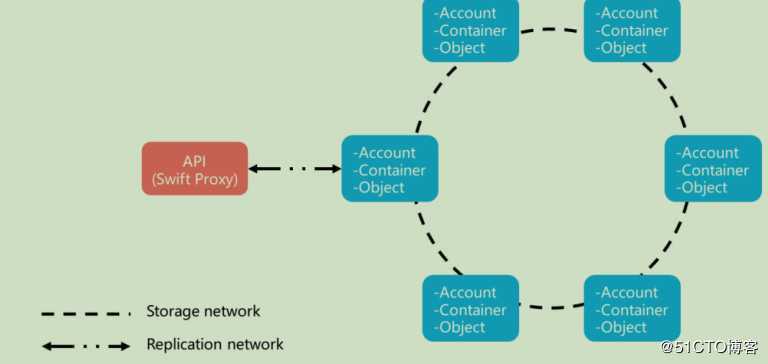
Swift组件
Proxy Server:对外提供对象服务API,由于采用无状态的REST请求协议,可以进行横向扩展来负载均衡
Account Server:提供账户元数据和统计信息,并维护所含容器列表的服务,每个账号的信息被存储在一个SQLite数据库中
Container Server:提供容器元数据和统计信息,并维护所含对象列表的服务,每个容器的信息也存储在一个SQLite数据库中
Object Server:提供对象元数据和内容服务,每个对象的内容会以文件的形式存储在文件系统中,元数据会作为文件属性来存储
Replicator:检测本地分区副本和远程副本是否一致,发现不一致时会采用推式(Push)更新远程副本,并且确保被标记删除的对象从该文件系统中移除
Updater:当对象由于高负载的原因而无法立即更新时,任务将会被序列化在本地文件系统中进行排队,以便服务恢复后进行异步更新
Auditor:检查对象,容器和账户的完整性,如果发现比特级错误,文件将被隔离,并复制其他的副本以覆盖本地损坏的副本;其他类型错误会被记录到日志中
Account Reaper:移除标记为删除的账户,删除其所包含的所有容器和对象
Swift API
Swift通过Proxy server向外提供基于HTTP的REST服务接口,对账户、容器和对象进行CRUD等操作
Swift数据模型
三层逻辑结构:Accout/Contianer/Object
每层节点数没有限制,可以任意扩展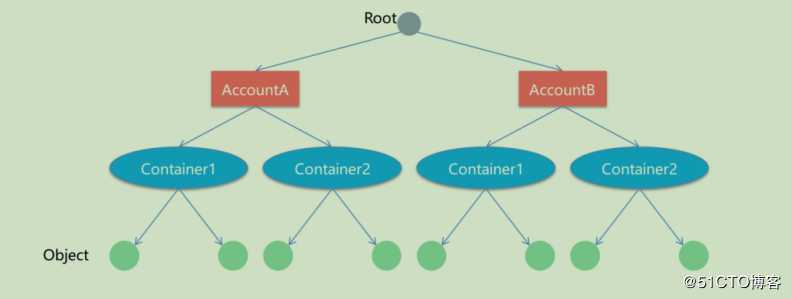
以上是关于openstack学习-理解存储管理的主要内容,如果未能解决你的问题,请参考以下文章