国际化
Posted liuzhiyun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了国际化相关的知识,希望对你有一定的参考价值。
HTTP报文可以承载任何语言表示的内容的。因为对HTTP来说,实体主体只是二进制信息的容器而已。
在HTTP中为了支持国际性,服务器返回内容的同时需要告知客户端文档是用的什么字母表和语言等信息,这样客户端才能正确的解析出信息并显示字符。服务器可以通过Content-Type中的charset参数和Content-Language首部告知客户端字母表和语言信息。
同时,客户端并不是所有的字母表和语言都能进行处理,所以客户端在发起请求的时候,也可以通过发送Accept-Charset和Accept-Language首部,告知服务端自己所能处理的编码类型和语言。这两个首部也支持优先级,可以通过q参数设置优先级。
所以,HTTP中的国际化,也就是本篇要介绍的内容主要涉及到字符集编码(character set encoding)和语言标记(language tag)
1 字符集和HTTP
1.1 字符集的概念
所谓字符集起始就是把字符转为二进制码的编码。HTTP 字符集的值说明如何把实体内容的二进制码转换为特定字母表中的字符。每个字符集标记都命名了一种把二进制码转换为字符的算法(反之亦然)。字符集标记在由 IANA 维护MIME字符集注册机构进行了标准化。一般通过Content-Type中的charset参数进行指定。如下:
Content-Type: text/html; charset=utf-8
1.2 字符集与编码
上面说了,字符集和编码目的就是为了将二进制信息同我们的字符进行转换。转换的具体流程一般经过两个步骤完成(这里以将二进制信息转为字符过程为例):
- 首先需要将二进制信息转为字符代码(某个字符集中的某个字符的特定编号);
- 得到这个代码后,我们再跟进这个代码从字符集中找到该代码对应的字符。
经过上面两个步骤,就能获得正确的字符了。而我们上面两个步骤都依赖于正确的charset值。如果该值不正确,同样一段二进制信息可能就会得出错误的字符代码,同样第二步中根据charset的值不同,字符代码和字符的对应关系也就不同。所以平时的乱码现象,有时候就是因为charset的值错误而引起。
charset的值使用的标准化的MIME charset标记。比如:utf-8, iso-8895-1, gbk等。
注:
该值一般来说是大小写不敏感的,在处理的时候需要注意这点。
HTTP只关心字符数据和相关语言及字符集标签的传输;字符形状的显示是由用户的图形显示软件(包括浏览器、操作系统、字体等)完成的。
1.3 客户端的Accept-Charset
正常情况下,服务器会通过在Content-Type首部中使用charset参数告知客户端MIME字符集。
但是如果服务器没有显示的返回信息,我们客户端可能就需要尽可能自己从文档内容判断出字符集。一般在HTML文档中,会通过<META HTTP-EQUIV="Content-Type">描述所用字符集信息。如下:
<HEAD> <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=gbk"> <META LANG="jp"> <TITLE>A Japanese Document</TITLE> </HEAD> <BODY> ...
该部分类容说明该html文档使用的gbk编码。
全世界范围类字符集编码非常多,服务器并不一定都是返回的客户端能正确处理的字符集。所以为了避免服务器端返回一些客户端无法处理的字符集,客户端在发送请求的时候,尽量通过Accept-Charset首部告知服务器,我们支持哪些字符系统。
2 字符编码简介
2.1 字符集术语
这里我们将一组把一系列 8 位字节转换为一系列字符的规则的集合称为字符集。其包括编码方案和编码后的字符集。在介绍字符集的时候会用到一下一些术语:
- 字符: 字符是指字母、数字、标点、表意文字(比如汉语)、符号,或其他文本形式的 书写“原子”。
- 字形:字形是字符的一种表现形式,同一个字符可以有多重字形,比如同样一个汉字,宋体和楷体表现出的字形是有区别的。
- 编码后的字符:分配给字符的唯一数字编号
- 代码空间:计划用于字符代码值的整数范围
- 代码宽度:每个字符代码所用的位数
- 字符库:特定的工作字符集
- 编码后的字符集:组成字符库的已经编码的字符集,并为每个字符分配代码空间中的一个代码。
- 字符编码方案:把数字化的字符代码编码为二进制码的算法。
2.2 字符编码方案
目前字符编码方案主要有以下3种:
a)、固定宽度
固定宽度方式的编码用固定数量的比特表示每个编码后的字符。这种方式处理速度较快,但是会浪费一些空间
b)、可变宽度(无模态)
顾名思义,可变宽度就是根据字符代码所需要的比特位,采用不同的宽度的比特进行存储。这样可以节约资源,而且还能根据需要利用多个字节来表示不同的文字,比如中午就需要两个字节
c)、可变宽度(有模态)
有模态的编码使用特殊的“转义”模式在不同的模态之间切换(这个我也没有太理解其含义)
常见编码示例:
a)、8位固定宽度
位固定宽度恒等编码把每个字符代码编码为相应的 8 位二进制值。它只能支持有 256 个字符代码范围的字符集。iso-8859 字符集家族系列使用的就是 8 位恒等编码。
b)、UTF-8
这个应该是目前比较流行的一种通用编码了,能够处理很多语言。是一种无模态的可变宽度编码。第一字节的高位表示编码后的字符所用的字节数,所需的每个后续字节都含有 6 位的代码 值,其编码方式可以和ASCII编码兼容。如下表: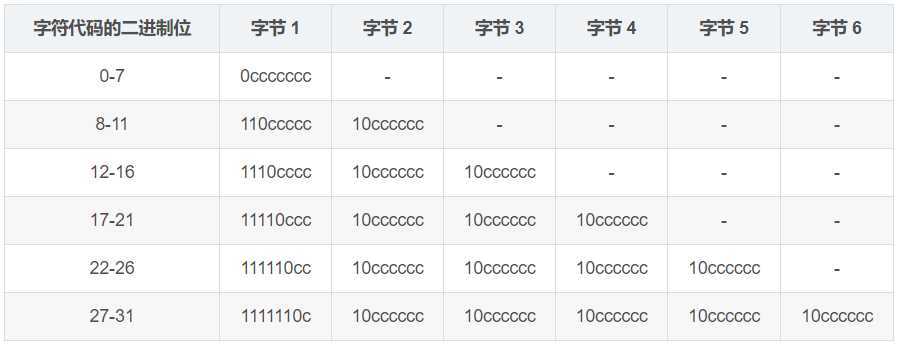
3 语言标记与HTTP
语言标记是命名口语的标准化字符串短语。同时,我们需要对这个标记的字符串进行标准化,否者每个人都有自己的命名习惯,字符串格式都不一样,就无法从标记中提取出语言信息。
3.1 Content-Language和Accept-Language首部
实体的 Content-Language 首部字段描述实体的目标受众语言,其不限于文本文档。音频片段、电影以及应用程序都有可能是面向特定语言受众的。任何面向特定语言受众的媒体类型都可以有 Content-Language 首部。同时我们也可以在该首部指定多个语言,如:Content-Language: en, fr。
相对应的,客户端也可以通过Accept-Language告知服务端我们能够接受的语言种类。其优先顺序从左至右
3.2 语言标记的类型
在 RFC 3066,“Tags for the Identification of Languages”(标识语言的标记)中记录了语言标记的标准化语法。可以用语言标记来表示:
- 一般的语言分类(比如 es 代表西班牙语);
- 特定国家的语言(比如 en-GB 代表英国英语);
- 语言的方言(比如 no-bok 指挪威的书面语);
- 地区性的语言(比如 sgn-US-MA 代表美国马撒葡萄园岛上的手语);
- 标准化的非变种语言(比如 i-navajo);
- 非标准的语言(比如 x-snowboarder-slang)。
标记一般由一个或多个部分组成,中间由"-"分隔,示例如下: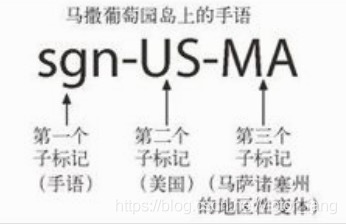
其中:
- 第一个标记是称为主子标记,其值是标准化的
- 第二个子标记是可选,遵循它自己的命名规则
- 其他尾随的子标记是未注册的
第一子标记和第二子标记都是有专门的文档及相关组织专门维护和命名的,后面会介绍一些。其他的那些没有专门维护的,一般需要在IANA进行注册。
注:所有的标记都是不区分大小写的。我们在解析的时候应该注意这点。
3.2.1 第一个子标记
第一个子标记通常是标准化的语言记号,选自 ISO 639 中的语言标准集合。不过也可以用字母 i 来标识在 IANA 中注册的名字,或用 x 表示私有的或者扩展的名字。其规则如下:
- 如果只有2个字符,那就是来自 ISO 639 和 639-1 标准的语言代码,如ar, en等
- 有3个字符,那就是来自 ISO 639-210 标准及其扩展的语言代码,如ara,eng等
- 字母i,该语言标记是在 IANA 显式注册的
- 字母 x,该语言标记是私有的、非标准的,或扩展的子标记。
3.2.2 第二个子标记
第二个子标记通常是标准化的国家记号,选自 ISO 3166 中的国家代码和地区标准集合。不过也可以是在 IANA 注册过的其他字符串,其规则如下:
- 2 个字符,那就是 ISO 316611 中定义的国家 / 地区;如:CN,FR
- 3~8 个字符,可能是在 IANA 中注册的值;
- 单个字符,这是非法的情况。
4 国家化的URI
4.1、URI字符集合
- URI允许使用ASCII字符集的子集
- URI字符被分为转义、保留和未保留三种,具体如下表所示:
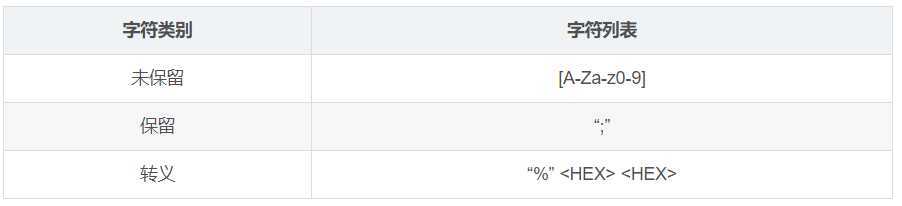
URI转义提供了一种安全的方式,可以在URI内部插入保留字符以及原本不支持的字符(比如各种空白)。
每个转义是一组3字符序列,由百分号(%)后面跟上两个十六进制数字的字符.这两个十六进制数字就表示一个US-ASCII字符的代码
在内部处理时,HTTP应用程序应当在传输和转发URI的时候保持转义不变。HTTP应用程序应该仅在需要数据的时候才对URI进行转义。
应用程序应该确保任何URI都不会被反转义2次,因为在转义的时候可能会把百分号编码进去,反转义出来之后,再转义一次就会导致数据丢失。
注:要转义的值本身应该在US-ASCII代码值的范围内(0~127)
以上是关于国际化的主要内容,如果未能解决你的问题,请参考以下文章