HBase的二级索引
Posted tesla-turing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase的二级索引相关的知识,希望对你有一定的参考价值。
使用HBase存储中国好声音数据的案例,业务描述如下:

为了能高效的查询到我们需要的数据,我们在RowKey的设计上下了不少功夫,因为过滤RowKey或者根据RowKey查询数据的效率是最高的,我们的RowKey的设计是:UserID + CreateTime + FileID,那么我们在HBase中的数据格式如下:
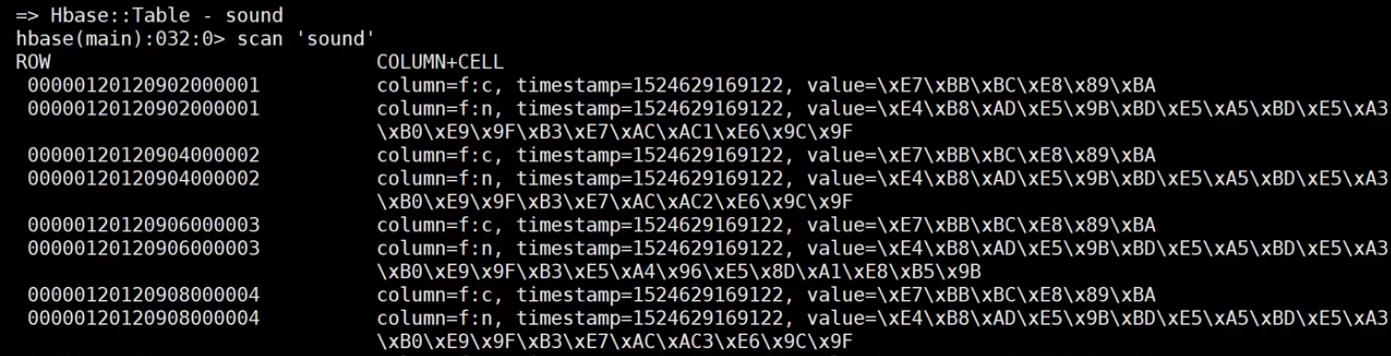
每一行数据中包含两个Column:f:c和f:n
我们在查询的时候还是用了SingleColumnValueFilter这个Filter来过滤单个的Column的Value的值,我们说如果在海量数据的时候使用这个SingleColumnValueFilter来过滤数据的话是非常耗时的事情,那么现在问题来了:
问题:
假设针对这张sound的表,我们需要查询包含“中国好声音”以及包含“综艺”的数据,也就是说我们的业务查询是:
2个条件同时输入find(“中国好声音”,“综艺”)
这个时候我们该怎么查询呢?
解决方案:
首先,我们现在的查询条件中没有对RowKey的过滤了,如果我们直接使用SingleColumnValueFilter这个Filter来过滤查询数据的话是可以达到目的,但是非常的耗时,所以我们不能使用这种方式
那么,我们现在就使用HBase中的二级索引来解决这个问题,我们先不解释二级索引是什么,我们先看下解决上面问题的过程,如下:
第一步:创建两张HBase表
第一张HBase表的RowKey是数据中的Name字段的值,这张表可以有不定数量的Column,每一个Column的值就是sound表的RowKey(和Name对应的RowKey),这张表我们称之为name_indexer表。create ‘name_indexer‘,‘f‘
第二张HBase表的RowKey是数据中的Category字段的值,这张表可以有不定数量的Column,每一个Column的值就是sound表的RowKey(和Category对应的RowKey),这张表我们称之为category_indexer表。create ‘category_indexer‘,‘f‘
第二步:将sound中的数据导入到name_indexer和category_indexer两张表中
使用Spark程序来实现索引表数据的导入,
import org.apache.hadoop.hbase.client.ConnectionFactory, Put, Scan
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.HBaseConfiguration, TableName
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* 使用Spark来建立HBase中表sound的二级索引
*/
object MyIndexBuilder
def main(args: Array[String]): Unit =
val spark = SparkSession
.builder()
.appName("MyIndexBuilder")
.master("local")
.getOrCreate()
// 1、创建HBaseContext
val configuration = HBaseConfiguration.create()
configuration.set("hbase.zookeeper.quorum", "master,slave1,slave2")
val hBaseContext = new HBaseContext(spark.sparkContext, configuration)
// 2、读取HBase表sound中的f:n和f:c两个列的值以及他们对应的rowKey的值
// 并且需要区分开是哪一个列的值
val soundRDD = hBaseContext.hbaseRDD(TableName.valueOf("sound"), new Scan())
val indexerRDD: RDD[((String, Array[Byte]), ImmutableBytesWritable)] = soundRDD.flatMap case (byteRowKey, result) =>
val nameValue = result.getValue(Bytes.toBytes("f"), Bytes.toBytes("n"))
val categoryValue = result.getValue(Bytes.toBytes("f"), Bytes.toBytes("c"))
// 区分开是哪一个列的值,使用key来区分
// 返回key是(tableName,列值), value是这个列对应的rowKey的值
Seq((("name_indexer", nameValue), byteRowKey), (("category_indexer", categoryValue), byteRowKey))
// 3、按照key进行分组,拿到相同列值对应的所有的rowKeys(因为在原表sound中多个rowKey的值可能会对应着相同的列值)
val groupedIndexerRDD: RDD[((String, Array[Byte]), Iterable[ImmutableBytesWritable])] = indexerRDD.groupByKey()
// 4、将不同的列值以及对应的rowKeys写入到相对应的indexer表中
groupedIndexerRDD.foreachPartition partitionIterator =>
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "master,slave1,slave2")
val conn = ConnectionFactory.createConnection(conf)
val nameIndexerTable = conn.getTable(TableName.valueOf("name_indexer"))
val categoryIndexerTable = conn.getTable(TableName.valueOf("category_indexer"))
try
val nameIndexerTablePuts = new util.ArrayList[Put]()
val categoryIndexerTablePuts = new util.ArrayList[Put]()
partitionIterator.map case ((tableName, indexerValue), rowKeys) =>
val put = new Put(indexerValue) // 将列值作为索引表的rowKey
rowKeys.foreach(rowKey =>
put.addColumn(Bytes.toBytes("f"), null, rowKey.get())
)
if (tableName.equals("name_indexer"))
nameIndexerTablePuts.add(put) // 需要写入到表name_indexer中的数据
else
categoryIndexerTablePuts.add(put) // 需要写入到表category_indexer中的数据
nameIndexerTable.put(nameIndexerTablePuts)
categoryIndexerTable.put(categoryIndexerTablePuts)
finally
nameIndexerTable.close()
categoryIndexerTable.close()
conn.close()
spark.stop()
第三步:查询结果
我们先从name_indexer这张表中按照RowKey查询属于“中国好声音”的记录,这些记录中的所有的列的值就是需要在sound中查询的RowKey的值
然后从category_indexer这张表中按照RowKey查询属于“综艺”的记录,这些记录中的所有的列的值就是需要在sound中查询的RowKey的值
最后将上面两步查询出来的结果做一个合并,就是将查询出来的结果做一次去重,得到了所有在sound中符合需求的RowKey,然后在根据这些RowKey去sound表中查询相应的数据
我们每一步查询都是根据HBase中的一级索引RowKey来查询的,所以查询速度会非常的快
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class SecondaryIndexSearcher
public static void main(String[] args) throws IOException
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "master,slave1,slave2");
try(Connection connection = ConnectionFactory.createConnection(config))
Table nameIndexer = connection.getTable(TableName.valueOf("name_indexer"));
Table categoryIndexer = connection.getTable(TableName.valueOf("category_indexer"));
Table sound = connection.getTable(TableName.valueOf("sound"));
// 1、先从表name_indexer中找到rowKey包含“中国好声音”对应的所有的column值
Scan nameIndexerScan = new Scan();
SubstringComparator nameComp = new SubstringComparator("中国好声音");
RowFilter nameRowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, nameComp);
nameIndexerScan.setFilter(nameRowFilter);
Set<String> soundRowKeySetOne = new HashSet<>();
ResultScanner rsOne = nameIndexer.getScanner(nameIndexerScan);
try
for (Result r = rsOne.next(); r != null; r = rsOne.next())
for (Cell cell : r.listCells())
soundRowKeySetOne.add(Bytes.toString(CellUtil.cloneValue(cell)));
finally
rsOne.close(); // always close the ResultScanner!
// 2、再从表category_indexer中找到rowKey包含“综艺”对应的所有的column值
Scan categoryIndexerScan = new Scan();
SubstringComparator categoryComp = new SubstringComparator("综艺");
RowFilter categoryRowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, categoryComp);
nameIndexerScan.setFilter(categoryRowFilter);
Set<String> soundRowKeySetTwo = new HashSet<>();
ResultScanner rsTwo = categoryIndexer.getScanner(categoryIndexerScan);
try
for (Result r = rsTwo.next(); r != null; r = rsTwo.next())
for (Cell cell : r.listCells())
soundRowKeySetTwo.add(Bytes.toString(CellUtil.cloneValue(cell)));
finally
rsTwo.close(); // always close the ResultScanner!
// 3、合并并去重上面两步查询的结果
soundRowKeySetOne.addAll(soundRowKeySetTwo);
// 4、根据soundRowKeySetOne中所有的rowKeys去sound表中查询数据
List<Get> gets = new ArrayList<>();
for (String rowKey : soundRowKeySetOne)
Get get = new Get(Bytes.toBytes(rowKey));
gets.add(get);
Result[] results = sound.get(gets);
for (Result result : results)
for (Cell cell : result.listCells())
System.out.println(Bytes.toString(CellUtil.cloneRow(cell)) + "===> " +
Bytes.toString(CellUtil.cloneFamily(cell)) + ":" +
Bytes.toString(CellUtil.cloneQualifier(cell)) + "" +
Bytes.toString(CellUtil.cloneValue(cell)) + "");
结论:
那么表name_indexer和category_indexer中的RowKey就是我们解决问题的二级索引,
所以二级索引的本质就是:建立各列值与行键之间的映射关系
最后,我们需要知道创建HBase二级索引的方式
1、Spark来实现二级索引的建立
我们前面使用的是Spark来实现二级索引的建立,但是这种方式适用于离线批处理,这些二级索引是每天或者每段时间执行一次的建立的
2、使用HBase的协处理器(coprocessor)
对于如果数据是实时更新的话,则这种离线批处理的方式是不行的,这个时候我们可以使用HBase的协处理器(coprocessor)
HBase的协处理器(Coprocessor)的介绍可以参考:https://www.cnblogs.com/small-k/p/9648453.html
3、HBase + Solr其实也是一个二级索引实现,只不过是把二级索引存储在Solr中
以上是关于HBase的二级索引的主要内容,如果未能解决你的问题,请参考以下文章