Spark专业术语定义
Posted tiepihetao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark专业术语定义相关的知识,希望对你有一定的参考价值。
1.1.1. Application/App:Spark应用程序
指的是用户编写的Spark应用程序/代码,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
Spark应用程序,由一个或多个作业JOB组成(因为代码中可能会调用多次Action),如下图所示:
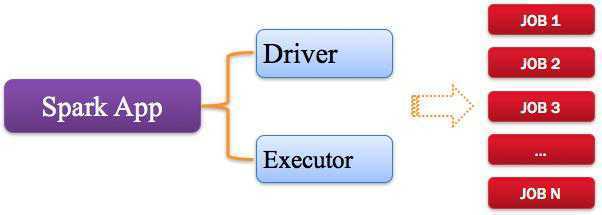
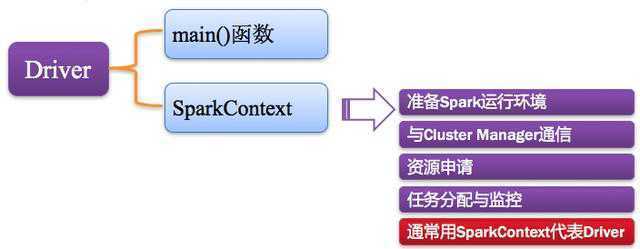
1.1.2. Driver:驱动程序
-
Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。
-
在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;
-
当Executor部分运行完毕后,Driver负责将SparkContext关闭。
-
通常SparkContext代表Driver,如下图所示:
1.1.3. Cluster Manager:资源管理器
指的是在集群上获取资源的外部服务,常用的有:
-
Standalone,Spark原生的资源管理器,由Master负责资源的分配;
-
Haddop Yarn,由Yarn中的ResourcesManager负责资源的分配;
-
Messos,由Messos中的Messos Master负责资源管理,
如下图所示:

1.1.4. Worker:计算节点
集群中任何可以运行Application代码的节点,类似于Yarn中的NodeManager节点。
-
在Standalone模式中指的就是通过Slave文件配置的Worker节点,
-
在Spark on Yarn模式中指的就是NodeManager节点,
-
在Spark on Messos模式中指的就是Messos Slave节点,
如下图所示:
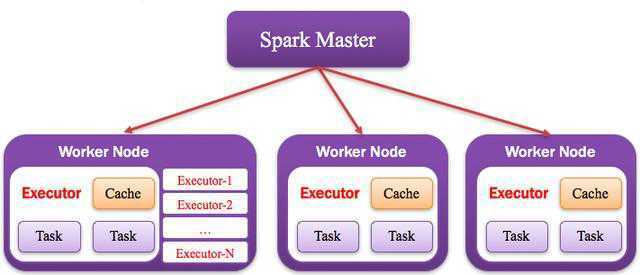
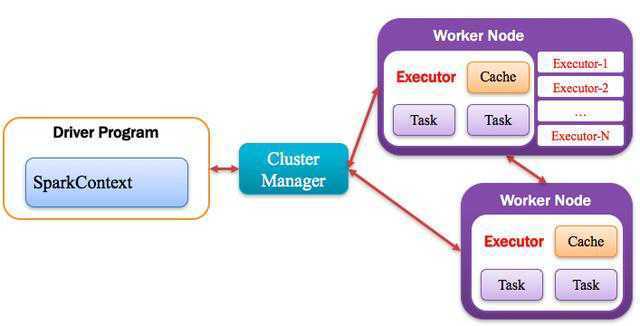
1.1.5. Executor:执行器
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,
每个Application都有各自独立的一批Executor,
如下图所示:
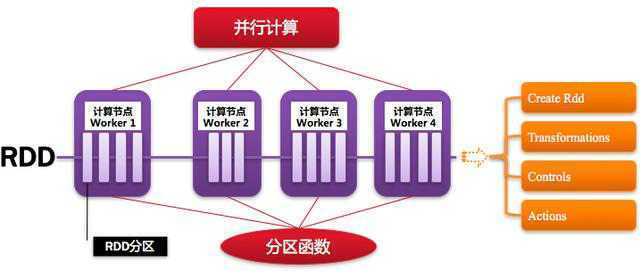
1.1.6. RDD:弹性分布式数据集
Resillient Distributed Dataset,Spark的基本计算单元,可以通过一系列算子进行操作(主要有Transformation和Action操作),
如下图所示:
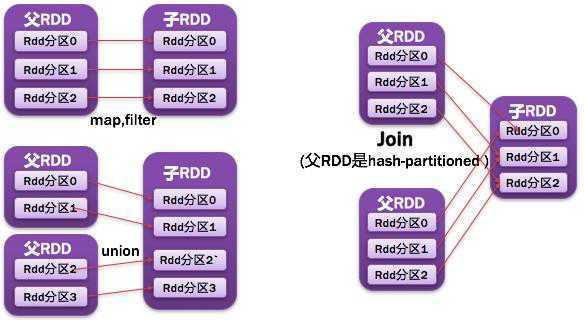
1.1.7. NarrowDependency窄依赖
父RDD一个分区被一个子RDD的分区所依赖;
如图所示:
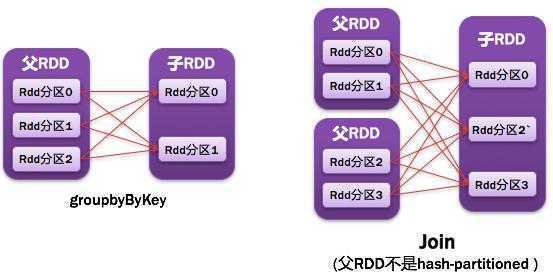
1.1.8. ShuffleDependency宽依赖
父RDD的一个分区都被子RDD多个分区所使用/依赖
如图所示:
- ●常见的窄依赖有:
- map、filter、union、mapPartitions、mapValues、join
- ●常见的宽依赖有:
- groupByKey、partitionBy、reduceByKey、join
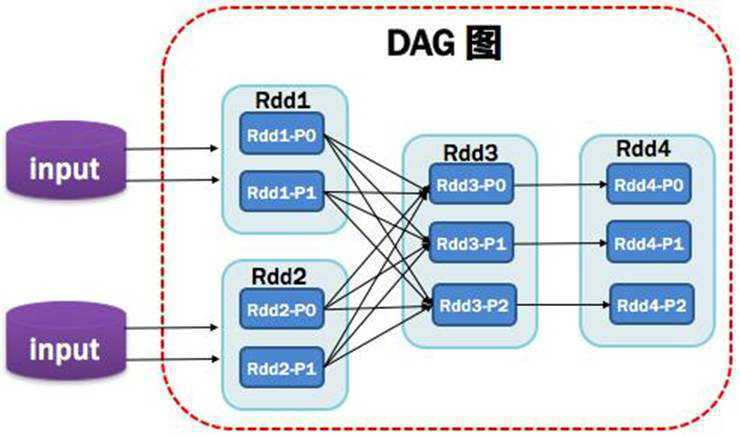
1.1.9. DAG:有向无环图
Directed Acycle graph,反应RDD之间的依赖关系,
DAG其实就是一个JOB(会根据依赖关系被划分成多个Stage)
注意:一个Spark程序会有1~n个DAG,调用一次Action就会形成一个DAG
如图所示:
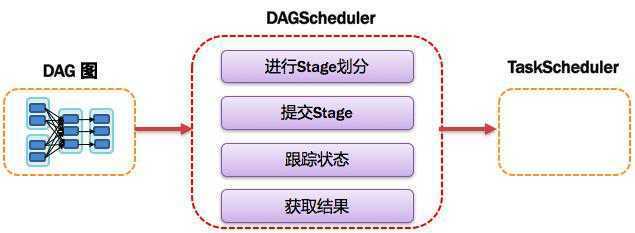
1.1.10.DAGScheduler:有向无环图调度器
基于DAG划分Stage 并以TaskSet的形式提交Stage给TaskScheduler;
负责将作业拆分成不同阶段的具有依赖关系的多批任务;
最重要的任务之一就是:计算作业和任务的依赖关系,制定调度逻辑。
在SparkContext初始化的过程中被实例化,一个SparkContext对应创建一个DAGScheduler。
●总结:DAGScheduler完成以下工作:
1. DAGScheduler划分Stage(TaskSet),记录哪个RDD或者 Stage 输出被物化(缓存),通常在一个复杂的shuffle之后,通常物化一下(cache、persist),方便之后的计算。
2. 重新提交出错/失败的Stage(shuffle输出丢失的stage/stage内部计算出错)
3. 将 Taskset 传给底层调度器
-
spark-cluster TaskScheduler
-
yarn-cluster YarnClusterScheduler
-
yarn-client YarnClientClusterScheduler
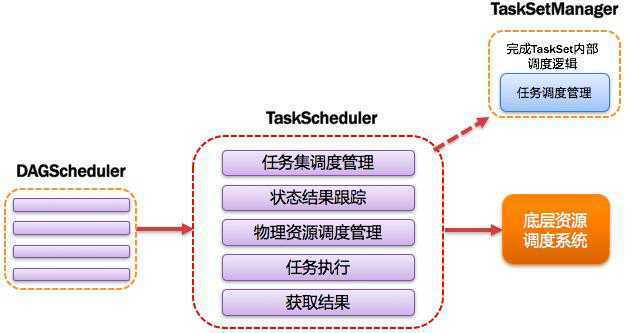
1.1.11.TaskScheduler:任务调度器
将Taskset提交给worker(集群)运行并回报结果;
负责每个具体任务的实际物理调度。
●总结:TaskScheduler完成以下工作:
1. 为每一个TaskSet构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
2. 数据本地性决定每个Task最佳位置(移动计算比移动数据更划算)
3. 提交 taskset(一组task) 到集群运行并监控
4. 推测执行,碰到 straggle(计算缓慢) 任务需要放到别的节点上重试
5. 重新提交Shuffle输出丢失的Stage给DAGScheduler
如图所示:
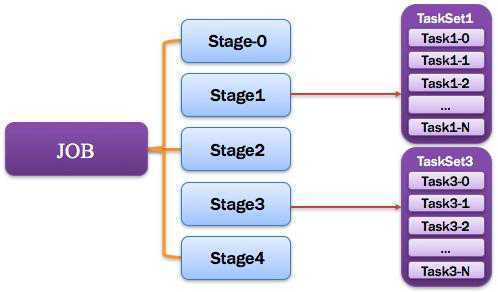
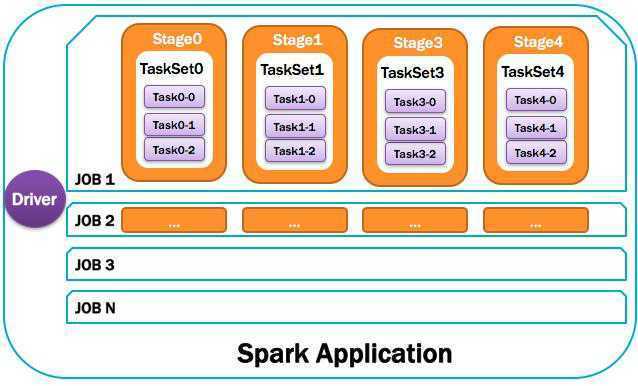
1.1.12.Job:作业
由一个或多个调度阶段Stage所组成的一次计算作业;
包含多个Task组成的并行计算,往往由Spark Action催生,
一个JOB包含多个RDD及作用于相应RDD上的各种Operation。
一个DAG其实就是一个Job
如图所示:
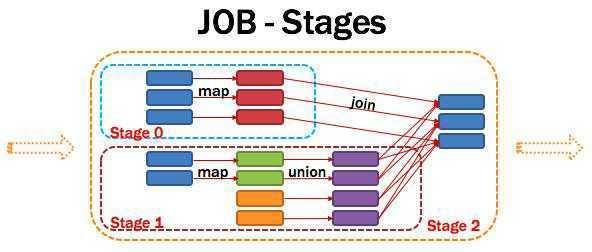
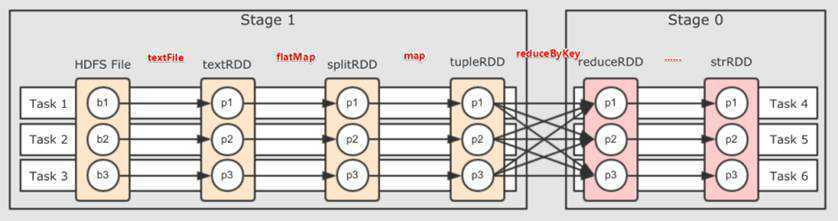
1.1.13.Stage:阶段
一个任务集对应的调度阶段;
一个Stage ==> 一个TaskSet
DAG会根据shuffle/宽依赖划分Stage(也就是TaskSet)
每个Job会被拆分很多组TaskSet,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;
Stage分成两种类型ShuffleMapStage、ResultStage。
如图所示:
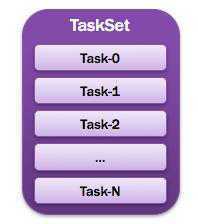
1.1.14. TaskSet:任务集
由一组关联的,但相互之间没有Shuffle依赖关系的任务所组成的任务集。
也就是一个Stage一个TaskSet
如图所示:
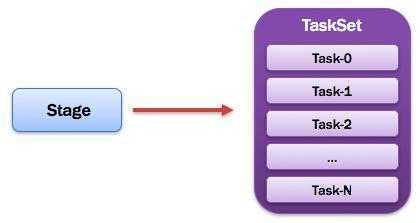
注意:
1)一个Stage创建一个TaskSet;
2)Stage的每个Rdd分区会创建一个Task,多个Task封装成TaskSet
1.1.15.Task:任务
被送到某个Executor上的工作任务;单个分区数据集上的最小处理流程单元。
如图所示:
1.1.16. 整体图示
以上是关于Spark专业术语定义的主要内容,如果未能解决你的问题,请参考以下文章