Structured Streaming 实战案例 读取文本数据
Posted tiepihetao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Structured Streaming 实战案例 读取文本数据相关的知识,希望对你有一定的参考价值。
1.1.1.读取文本数据
spark应用可以监听某一个目录,而web服务在这个目录上实时产生日志文件,这样对于spark应用来说,日志文件就是实时数据
Structured Streaming支持的文件类型有text,csv,json,parquet
●准备工作
在people.json文件输入如下数据:
"name":"json","age":23,"hobby":"running"
"name":"charles","age":32,"hobby":"basketball"
"name":"tom","age":28,"hobby":"football"
"name":"lili","age":24,"hobby":"running"
"name":"bob","age":20,"hobby":"swimming"
注意:文件必须是被移动到目录中的,且文件名不能有特殊字符
●需求
接下里使用Structured Streaming统计年龄小于25岁的人群的爱好排行榜
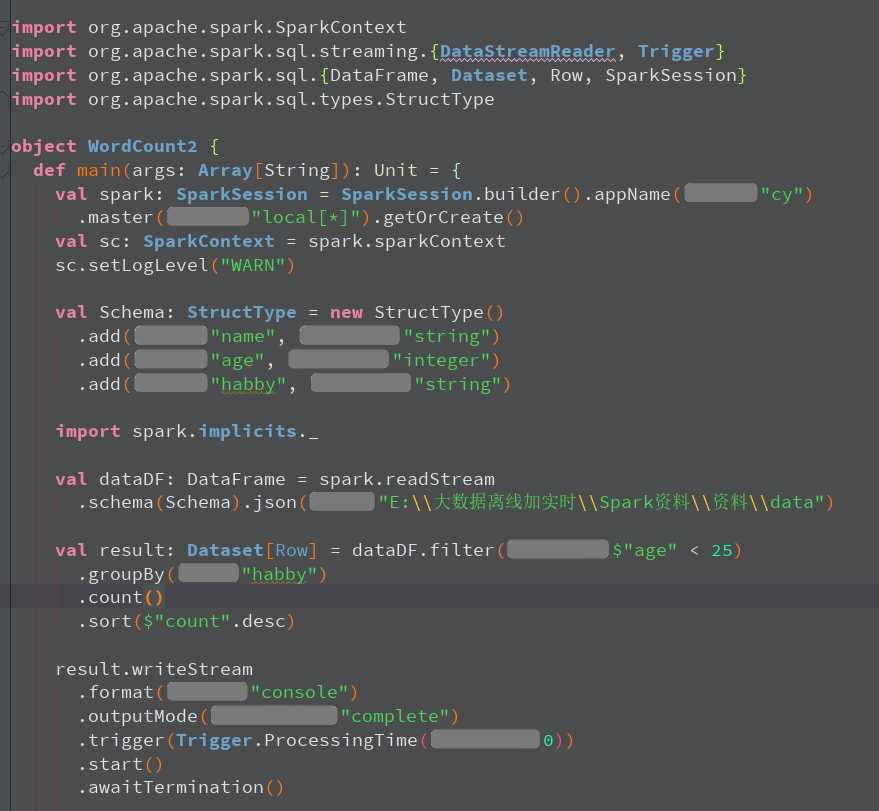
●代码演示:
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.DataFrame, Dataset, Row, SparkSession
/**
* "name":"json","age":23,"hobby":"running"
* "name":"charles","age":32,"hobby":"basketball"
* "name":"tom","age":28,"hobby":"football"
* "name":"lili","age":24,"hobby":"running"
* "name":"bob","age":20,"hobby":"swimming"
* 统计年龄小于25岁的人群的爱好排行榜
*/
object WordCount2
def main(args: Array[String]): Unit =
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
val Schema: StructType = new StructType()
.add("name","string")
.add("age","integer")
.add("hobby","string")
//2.接收数据
import spark.implicits._
// Schema must be specified when creating a streaming source DataFrame.
val dataDF: DataFrame = spark.readStream.schema(Schema).json("D:\\\\data\\\\spark\\\\data")
//3.处理数据
val result: Dataset[Row] = dataDF.filter($"age" < 25).groupBy("hobby").count().sort($"count".desc)
//4.输出结果
result.writeStream
.format("console")
.outputMode("complete")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination()
1
import org.apache.spark.SparkContext
2
import org.apache.spark.sql.streaming.Trigger
3
import org.apache.spark.sql.types.StructType
4
import org.apache.spark.sql.DataFrame, Dataset, Row, SparkSession
5
/**
6
* "name":"json","age":23,"hobby":"running"
7
* "name":"charles","age":32,"hobby":"basketball"
8
* "name":"tom","age":28,"hobby":"football"
9
* "name":"lili","age":24,"hobby":"running"
10
* "name":"bob","age":20,"hobby":"swimming"
11
* 统计年龄小于25岁的人群的爱好排行榜
12
*/
13
object WordCount2
14
def main(args: Array[String]): Unit =
15
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
16
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
17
val sc: SparkContext = spark.sparkContext
18
sc.setLogLevel("WARN")
19
val Schema: StructType = new StructType()
20
.add("name","string")
21
.add("age","integer")
22
.add("hobby","string")
23
//2.接收数据
24
import spark.implicits._
25
// Schema must be specified when creating a streaming source DataFrame.
26
val dataDF: DataFrame = spark.readStream.schema(Schema).json("D:\\\\data\\\\spark\\\\data")
27
//3.处理数据
28
val result: Dataset[Row] = dataDF.filter($"age" < 25).groupBy("hobby").count().sort($"count".desc)
29
//4.输出结果
30
result.writeStream
31
.format("console")
32
.outputMode("complete")
33
.trigger(Trigger.ProcessingTime(0))
34
.start()
35
.awaitTermination()
36
37
代码截图:
以上是关于Structured Streaming 实战案例 读取文本数据的主要内容,如果未能解决你的问题,请参考以下文章